作者:霓Nin氵ini | 来源:互联网 | 2023-10-12 15:06
之前面试淘点点的时候被问倒得一个问题至今牵挂,由于工作环境的限制,我没能接触到一些大数据量的并发工作,也没能有机遇参与复杂系统的设计,而我学习复杂或高并发系统的唯一途径就是阅读源码,惭愧的是,至今也只阅读了Tomcat的部分源码
从事开发工作两年来,从未写过只言片语,俗话说的好”好记性不如烂笔头“,最近心血来潮开始想慢慢写点博文,不仅是知识的积累还是为了若干年后回头看看当年努力的过程,希望把这个养成习惯并坚持下去,啰嗦了这么久 来点干货把。
之前面试淘点点的时候被问倒得一个问题至今牵挂,由于工作环境的限制,我没能接触到一些大数据量的并发工作,也没能有机遇参与复杂系统的设计,而我学习复杂或高并发系统的唯一途径就是阅读源码,惭愧的是,至今也只阅读了Tomcat的部分源码,于是我在oschina上贴出问题与互联网猿一同分析( 大家可以先看看问题:关于淘点点面试中碰到的架构问题 ),非常感谢大家的意见,尤其是@林中漫步 @JerryLin 两位先生 最终确定两钟实现思路:
1、具有排序功能的队列
2、Redis+定时器
思路 1
原理:第一种思路也就是大家推荐的延迟队列实现的原理,其就是一个按时间排好序的队列,每次put的时候排序,然后take的时候就计算时间是否过期,如果过期则返回队列第一个元素,否则当前线程阻塞X秒,这个也是JDK 自带 DelayQueue 的思路。详细可看源码
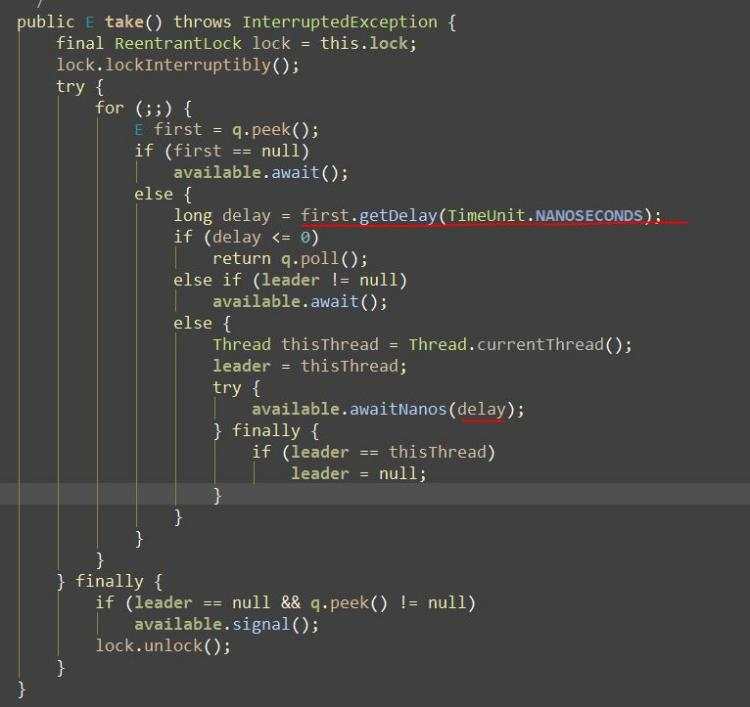
代码实现:待实现后补充
思路 2
原理:第二种思路需要利用Redis的有序集合,说到使用 Redis 就不得不考虑Score的设计,因为它直接决定你代码的复杂度,你思路的清晰性,在这我并没有采用林中漫步 先生的设计,而是通过精确到秒的时间做Score(去掉毫秒),然后使用线程每一秒扫一次,使用当前时间作为zrangeBysocre命令的Score去查询。详细请看代码。
业务场景:按京东一天500万的成交量,一天主要成交时间为8小时,计算得出每秒173个订单,当然实际上订单不能均匀分布在每秒,但我们主要为了论证思想的可行性。
代码实现:这里首先我简单的利用Spring Scheduled作为订单的生产者,每一秒制造170个订单,放入Redis,注意Score的生成,为当前时间的后60秒,removeMillis()生成去掉毫秒的时间戳作为Rredis的Zadd方法的 Score(不了解的可以百度下)。

第二步:同样利用Spring Scheduled 一秒钟心跳一次,每次利用当前时间作为Key 从Redis 取数据。

经过测试,没有出现漏单的情况,这只是简单的实现,很多地方可以优化,在实际中用也可能会出现很多问题,需要不断完善,此案例只是提供思路,另外我觉得JDK的 DelayQueue 相对于Redis来说没有那么好,因为Queue毕竟每次取一个,如果同一时间的比较多可能不能符合当前这种时间严谨的需求,另外他是单机的,有时间我去研究下kafka、Rabbit的延迟队列再来补充。
终于写完了,因为公司的代码是加密的,所以不能上传源码了(其实也没得什么上的,哈哈),另外本人技术有限难免会有纰漏或者错误,欢迎拍砖,另外希望自己以后能够坚持写技术日志。
来自: http://www.importnew.com/17437.html









 京公网安备 11010802041100号
京公网安备 11010802041100号