这里是网站:美团网站 ,这里举例足疗
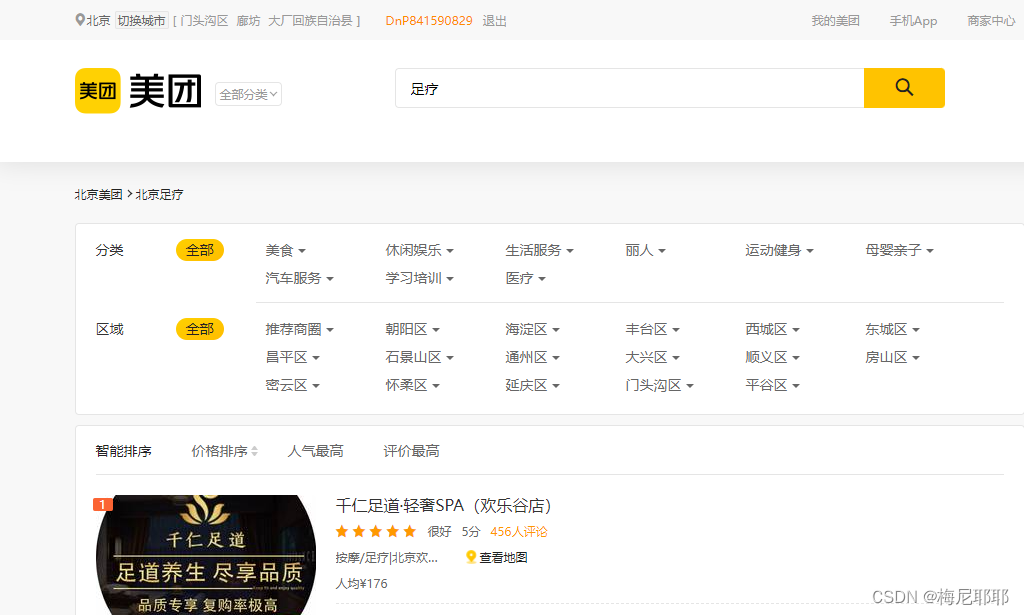
美团的数据请求方式是Ajax的请求方式,属于数据异步加载方式,这是一个动态页面,而解决这种方式有两种,一种selenium,一种使用requests进行抓包。在这里我们使用requests进行抓包
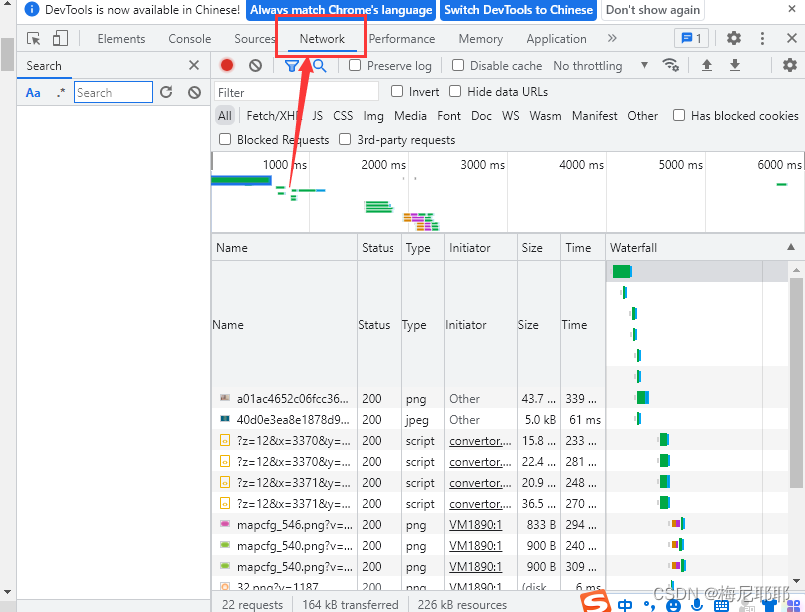
这里显示的所有就是这个页面的数据包,各种数据都在这里,图片,视频等等,我们找到我们要找的数据包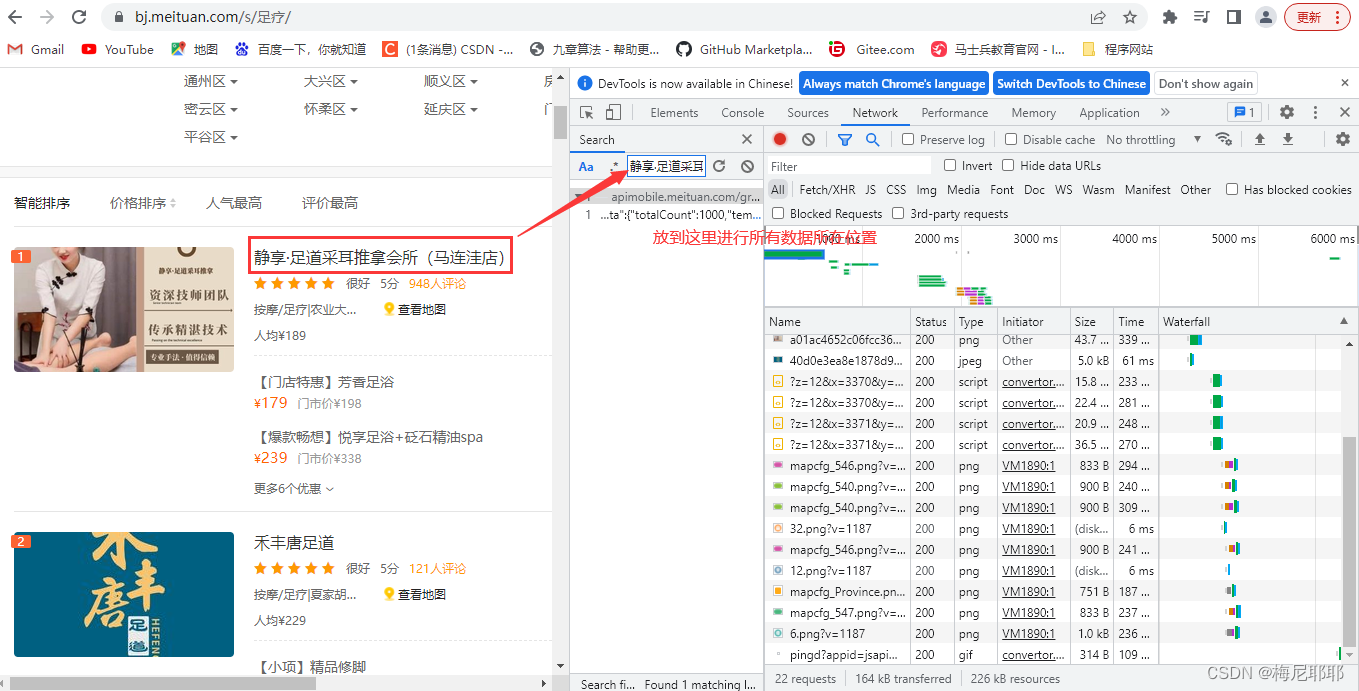
从而里面出现给的就是数据所在的位置,点击即可找到数据包
数据所在的位置,查看即可,然后找到数据包对应的url,和请求方式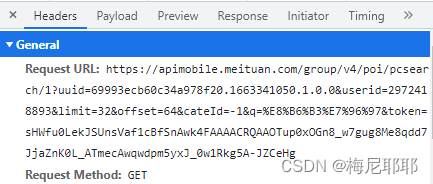
这里我们可以看到url和请求方式,请求方式是get,所以在我们使用requests的时候我们就要使用get方式来请求这个url
发现这个?后面有很多参数,所以url我们选择到?之前,剩下的参数我们选择传入,在开发者工具中找到参数将所有参数复制粘贴到代码中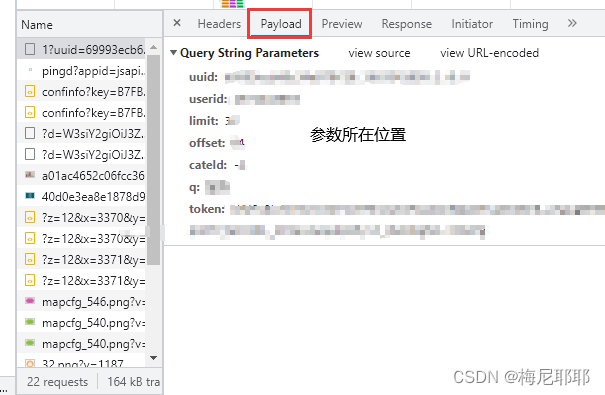
下面开始敲代码**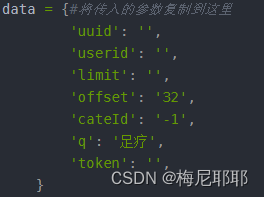
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/1?'
data = {#将传入的参数复制到这里
#上一张图片的形式写入
}
#headers表示的是请求头,用来避免识别你是程序
#Referer是表示从那个页面跳转过来的
headers = {
'Referer': 'https://bj.meituan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
}
#发起请求对数据网址
resp = requests.get(url, params=data, headers=headers)
我们参数和请求头的准备好,已经对网址进行了get请求
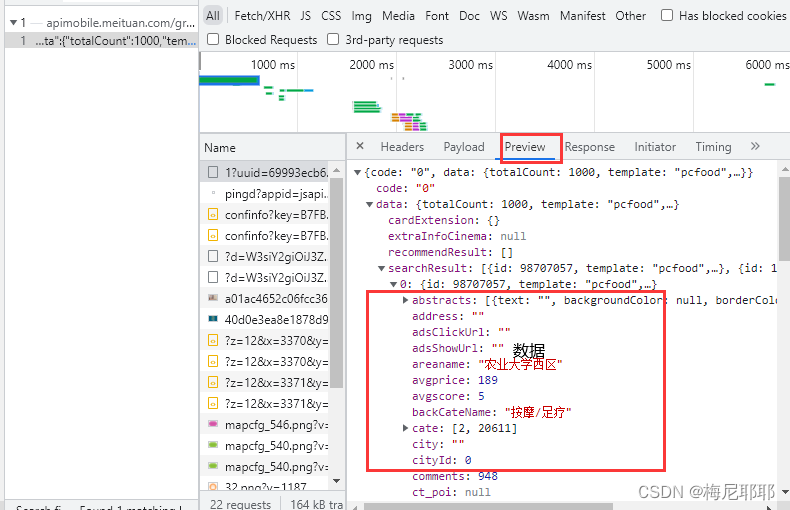
现在开始分析数据报格式,拿到数据的格式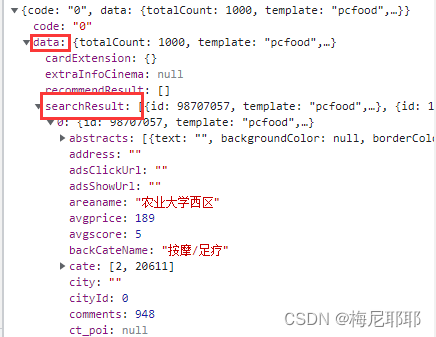
可以看到数据是json格式,是在data里面的searchResult中,所以我们先把数据定位到searchResult中
因为数据是json格式,索引我们应该先把拿到的响应数据转换成json格式,然后再定位到searchResult中
searchresult = resp.json()['data']['searchResult']
这样就可以得到searchResult中的数据了
例如这个样式
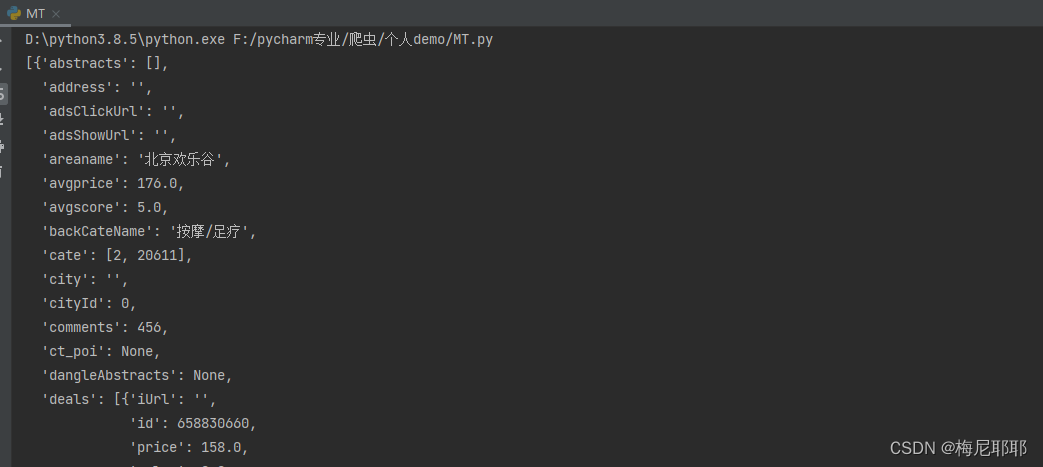
然后我们就可以根据字典的获取元素的方式来拿到响应得到数据元素
searchresult = resp.json()['data']['searchResult']
for item in searchresult:
# pprint.pprint(item)
shop_id = item['id']
shop_url = f'https://www.meituan.com/xiuxianyule/{shop_id}'
dict = {
'商店id': item['id'],
'标题': item['title'],
'类型': item['backCateName'],
'评分': item['avgscore'],
'地区': item['areaname'],
'商店链接': shop_url
}
这就可以拿到美团搜索到的数据的封面的响应数据,详情页面的数据需要进一步访问,详情页的数据是静态数据,可以直接获取
在这里我最后存储的格式是csv格式的数据,所以要引入csv包
import csv
f=open('meituan.csv','a',encoding='utf-8',newline='')
csv_writer=csv.DictWriter(f,fieldnames=['商店id','标题','类型','评分','地区','商店链接'])
csv_writer.writeheader()#写入标头
csv_writer.writerow(dict)#写入爬取的数据
这样我们的爬取过程就完成了,针对于爬取多页,可以自行查看参数的变化规律,进行修改即可
爬取文件大概就是这个样子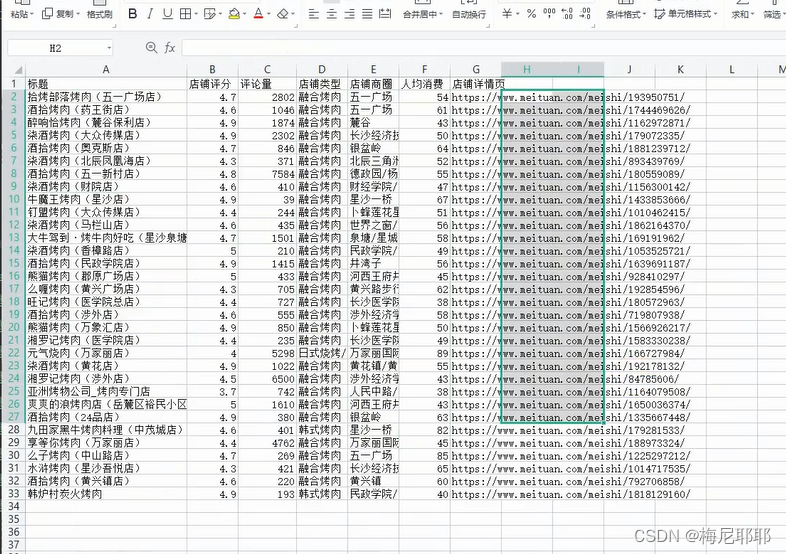
最后展示完整代码
import requests
import csv
f=open('meituan.csv','a',encoding='utf-8',newline='')
csv_writer=csv.DictWriter(f,fieldnames=['商店id','标题','类型','评分','地区','商店链接'])
csv_writer.writeheader()#写入标头
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/1?'
#美团的每一页网址不会变更,但变更的是offect,步值是32,没加一页,offect的值就加32
data = {
#传入的参数全部写到这里,使用键值对的形式
}
headers = {
'Referer': 'https://bj.meituan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
}
resp = requests.get(url, params=data, headers=headers)
# print(resp.text)
# pprint.pprint(resp.json())
searchresult = resp.json()['data']['searchResult']
for item in searchresult:
# pprint.pprint(item)
shop_id = item['id']
shop_url = f'https://www.meituan.com/xiuxianyule/{shop_id}'
dict = {
'商店id': item['id'],
'标题': item['title'],
'类型': item['backCateName'],
'评分': item['avgscore'],
'地区': item['areaname'],
'商店链接': shop_url
}
csv_writer.writerow(dict)#写入对应表头的数据
print(dict)
如果没有requests库需要pip install requests,安装这个库。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有