本文是对于github上一篇关于无人驾驶的深度学习方面提问的
‘’部分个人见解+论坛内外对该问题的解答‘’
本文属于搬运+整合的笔记贴,主要是为了自身学习用。
搬运会标明出处,如有侵权,无意冒犯,
希望原作者联系我,我会进行处理,感谢。
Github面试题地址:https://github.com/Ewenwan/MVision**
1、机器学习和深度学习的区别,各自适用于什么问题
2、随机梯度下降(stochastic gradient descent)
SGD算法 – 从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,在更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型,是一种逐个样本进行loss计算进行迭代的方法。
3、神经网络训练如何解决过拟合和欠拟合
解决过拟合:
a、获取更多的训练数据
训练数据越多,模型的泛化能力越好,这个是最优的方法,但是很多情况下我们无法获取更多的数据,因此需要其他方法
b、减小网络容量
这是防止过拟合最简单的方法 在深度学习中,模型容量就是模型中可学习参数的个数。 参数越多,模型就拥有越大的记忆容量。 减小网络容量,即减少参数的个数,即对层数和每层的单元个数进行处理。
c、添加权重正则化 – L1,L2正则化
根据奥卡姆剃刀原理: 如果一件事有两件解释,那么最可能正确的解释就是最简单的那个,即假设更少的那个。
简单的模型(参数更少的模型)比复杂模型更不容易过拟合。
通过强制让模型权重只能取得较小的值来降低过拟合
实现方法:向网络损失函数中添加与较大权重值相关的成本。
L1:添加的成本与权重系数的绝对值成正比。
L2:添加的成本与权重系数的平方成正比。
4、L1正则化(L1 normalization)和L2正则化(L2 normalization)区别,具体有何用途
a、L1正则化 – 在原本损失函数基础上加上权重参数的绝对值
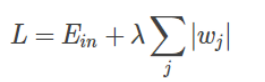
或者

L1正则化对所有参数的惩罚力度都一样,可以让一部分权重变为0,因此产生稀疏模型,能够去除某个些特征(权重为0则等效于去除)。
b、L2正则化 – 在原本损失函数的基础上加上权重参数的平方和

或者

L2正则化减少了权重的固定比例,使得权重平滑,L2正则化不会使权重变为0(不会产生稀疏模型),所以选择了更多的特征.
具体区别:
A、L1可以产生0解,L2可以产生趋近0的解
B、L1获得稀疏解,L2获得非零稠密解 – L1使得权重系数,L2使得权重平滑
C、如果事先假定只有非常少数的特征是重要的,可以用L1
D、L1优点是能够获得sparse模型,对于large-scale的问题来说这一点很重要,因为可以减少存储空间
E、L2优点是实现简单,能够起到正则化的作用。缺点就是L1的优点:无法获得sparse模型
5、L1正则化相比于 L2正则化为何具有稀疏解?
相比L2正则化,L1正则化的稀疏性具有本质的不同,L1正则化产生的更稀疏的解是指最优值中的一些参数为0.
由于个人能力,仅能从数据计算的角度解释,数据先验的角度暂不理解。
假设只有一个参数w,损失函数为L(w),分别加上L1正则化和L2正则化后有:
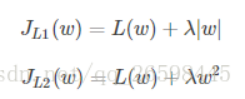
假设L(W)在0出的倒数为d0

那么,引入L2正则化项后,在0处导数为

引入L1正则化项后,在0处导数为

总结为:
L1和L2正则化项在0处导数不一样,对于L2,损失函数在0处导数不变;
而对于L1,损失函数在0处导数有突变,从d0+λ到d0-λ,导致原函数在0处会有一个极小值点。
因此在优化时,很可能会优化到该极小值点上,即w=0处.
6、CNN基本原理,CNN的哪些部分是神经元
解释”CNN基本原理”的角度— CNN的定义 + CNN的各层意义
CNN神经元 —— 神经元就是指一个带权重W和偏置B,以及激活方程f的一个单元 输入I和输出O的关系是 O = f(WI+B)
CNN的定义:
卷积网络(convolutional network),也叫作卷积神经网络(convolutional neural network,CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。
CNN的各层意义:
搭建一个神经网络,通常都是
Input > convolutional Layer(s)(+activated) > pooling Layer(s) > fully-connected > Output
其中卷积层和池化层可以视情况任意增加,即是 in- loop(>-conv-pooling-…-conv-pooling>)- fc > out
下面主要对卷积层,池化层和全连接层进行说明
Input和Output层作用和意义暂不说明
---------------------------------Convolutions Layer(卷积层)的作用和意义 : ---------------------------------

对于该图的理解 —— 像素矩阵输入后经过卷积核映射后(矩阵运算)后,输出一个5 * 5的矩阵。
如图,一个7 * 7的矩阵,卷积核为3 * 3,输出为(7-3+1) * (7-3+1)= 5 * 5 的矩阵,
矩阵放置到了经过bagging后的7 * 7矩阵。
- 理解局部感知概念
通俗来说权值共享指 —— 给一张输入图片,用一个卷积核去扫这张图,卷积核里面的数就叫权重,这张图每个位置是被同样的卷积核扫的,所以权重是一样的,也就是共享。
参照blog:
卷积神经网络CNN基本原理详解
https://blog.csdn.net/woaijssss/article/details/79535052
CNN卷积神经网络原理详解(上)
https://blog.csdn.net/LEEANG121/article/details/102633718?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=1329187.8310.16178419329314091&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
---------------------------------Activated function(激活函数)的作用和意义:---------------------------------
常用的激励函数有:
Sigmoid函数
Tanh函数
ReLU
Leaky ReLU
ELU
Maxout
激励层建议:首选ReLU,因为迭代速度快,但是有可能效果不佳。如果ReLU失效的情况下,考虑使用Leaky
ReLU或者Maxout,此时一般情况都可以解决。Tanh函数在文本和音频处理有比较好的效果。
---------------------------------Pooling layer(池化层)的作用和意义:---------------------------------
- 主要有:
- 一般池化: Max Pooling:最大池化 Average Pooling:平均池化
- 重叠池化 : OverlappingPooling
- 空金字塔池化 : Spatial Pyramid Pooling
---------------------------------Full-connected layer(全连接层)的作用和意义:---------------------------------
作用:连接所有特征,将输出值送给分类器(如softmax分类器)
在来到FC层之前,已经经过若干次卷积+激励+池化,
如果神经元数目过大,学习能力强,有可能出现过拟合。
因此可以引入dropout,局部归一化(LRN)、数据增强等操作来防止过拟合。
当来到FC层之后,可以理解为一个简单的多分类神经网络,通过softmax函数得到最终的输出,整个模型训练完毕。
下图展示了一个含有多个卷积层+激励层+池化层的过程:

7、CNN去掉激活函数会怎么样
“激活函数是用来加入非线性因素的,因为线性模型的表达力不够”
- 我们知道在神经网络中,对于图像,
我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。
但是对于我们样本来说,不一定是线性可分的,
为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
8、介绍下你了解的轻量级CNN模型(了解)
轻量级深度学习网络(一):详解谷歌轻量级网络MobileNet-v1
https://blog.csdn.net/chenyuping333/article/details/81363125?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
轻量级模型:MobileNet V2
https://blog.csdn.net/kangdi7547/article/details/81431572?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
9、无监督/半监督深度学习(了解)?
解答思路:首先了解无监督/半监督学习,再到无监督/半监督深度学习
监督学习(Supervised Learning)
监督学习是使用已知正确答案的示例来训练网络的
其中:数据集的创建和分类 中对分类和回归的解释值得记录
在数学上,我们在神经网络中找到一个函数,这个函数的输入是一张图片(图像检测应用),
当目标不在图片中,输出0,否则为1.这个过程叫分类。
在这种情况下,我们进行的通常是一个yes or no的训练,
但是,监督学习还能输出一组介于0和1值,这个任务我们称为回归。
无监督学习(Unsupervised Learning)
无监督学习适用于具有数据集但无标签的情况。
无监督学习采用输入集,并尝试查找数据中的模式。
无监督的学习方法包括:
自编码
主成分分析
随机森林
K均值聚类
生成对抗网络
半监督学习(Semi-supervised Learning)
半监督学习在训练阶段结合了大量未标记的数据和少量标签数据,与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。
为什么使用未标记数据有时可以帮助模型更准确,关于这一点的体会就是:
即使你不知道答案,但你也可以通过学习来知晓,有关可能的值是多少以及特定值出现的频率。
对于无监督深度学习和半监督深度学习:
第一类 — 无标签数据预训练,有标签数据微调
好的初始化,能够让结果更加稳定,迭代次数更少
初始化方式主要有两种:无监督预训练,伪有监督预训练
无监督预训练:
a、用所有数据逐层重构预训练,对网络的每一侧给,都做重构自编码,得到参数后用有标签数据微调
b、用所有数据训练重构自编码网络,然后把自编码网络的参数,作为初始参数,用有标签数据微调。
伪有监督与训练:
通过某种方式/算法(如半监督算法,k均值聚类算法等),给无标签数据附上伪标签信息,先用这些伪标签信息来预训练网络,然后再用有标签数据微调。第二类 — 使用从网络得到的深度特征来做半监督算法 给神经网络制造标签数据,相当于简洁的self-training。 一般流程为:
先用有标签数据训练网络(此时网络一般过拟合),从该网络中提取所有数据的特征,以这些特征来用某种分类算法对无标签数据进行分类,挑选你认为的分类正确的无标签数据加入到训练集,再训练网络,如此循环。
由于网络得到新的数据(挑选出来分类后的无标签数据)会更新提升,使得后续提出来的特征更好,后面对无标签数据分类就更精确,挑选后加入到训练集中又继续提升网络。对于该想法的性能,个人保持猜疑态度,由于噪声的影响,挑选加入到训练无标签数据一般都带有有标签噪声(就是某些无标签数据被分类错误),这些噪声会误导网络且被网络学习记忆第三类 — 让网络以半监督学习的方式运行
第一类和第二类都是用了有标签数据和无标签数据,但就神经网络本身而言,其实还是运行再一种有监督的方式上。 让深度学习真正成为半监督算法的方法:
b 、2015-Semi-Supervised Learning with Ladder Networks
2015年诞生半监督ladderNet,ladderNet是其他文章中先提出来的想法,但这篇文章使它 work in semi-supervised fashion,而且效果非常好,达到了当时的 state-of-the-art 性能。
ladderNet是有监督算法和无监督算法的有机结合。前面提到,很多半监督深度学习算法是用无监督预训练这种方式对无标签数据进行利用的,但事实上,这种把无监督学习强加在有监督学习上的方式有缺点:两种学习的目的不一致,其实并不能很好兼容。
无监督预训练一般是用重构样本进行训练,其编码(学习特征)的目的是尽可能地保留样本的信息;而有监督学习是用于分类,希望只保留其本质特征,去除不必要的特征。
ladderNet 通过 skip connection 解决这个问题,通过在每层的编码器和解码器之间添加跳跃连接(skip connection),减轻模型较高层表示细节的压力,使得无监督学习和有监督学习能结合在一起,并在最高层添加分类器,ladderNet就变身成一个半监督模型。
ladderNet 有机地结合了无监督学习和有监督学习,解决兼容性问题,发展出一个端对端的半监督深度模型。
10、Relu为什么比sigmod好?
a 、采用sigmoid作为激活函数进行指数运算时,计算量大,尤其是在反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用relu激活函数,整个过程的计算量节省很多。
b 、对于深层网络,sigmoid函数进行反向传播时,很容易出现梯度消失的情况(在sigmoid接近饱和区域时,变换太缓慢,倒数趋向于0,这时候会造成信息丢失),从而无法完成深层网络的训练。
c 、Relu会使一部分神经元的输出为,这样造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 


