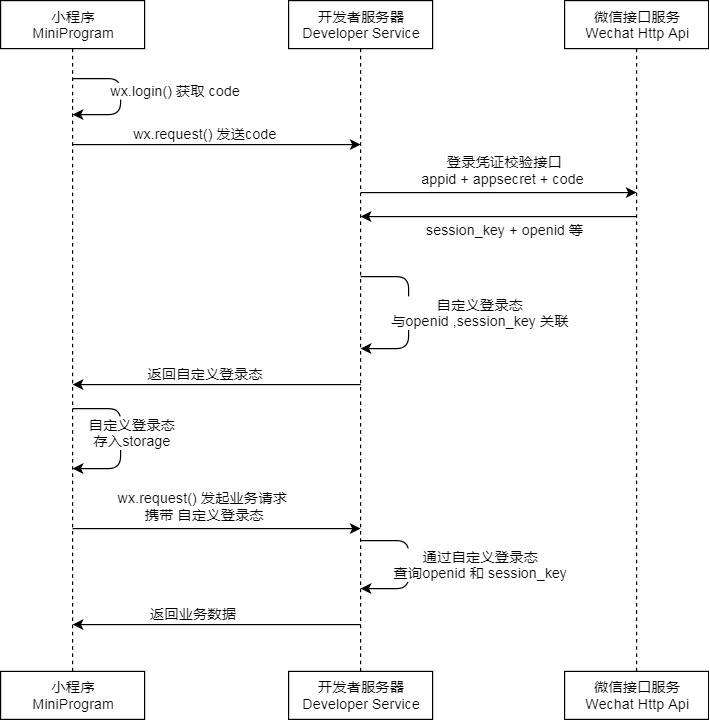
FlightTrainTask定时任务,通过Spring的@Scheduled来定时调用
@Scheduled(cron ="0 0 2 * * ?") // 每天的16整点执行一次,每一次请求一页数据
public void taskCycle() {
在此方法中,
将采集网址固定了,所以,ArticlegatherController没有启用。
采集模式,不同的网址,使用不同的采集方式,因此,出现了Timing1、Timing2、Timing3、Timing4、Timing5、Timing6共6个不同的采集类。
在Timing1类里的No1
0)输入采集URL地址,这个地址,打开后,是一个文章发布列表。
1)spiderTitle 采集标题
11)使用java.net.URL打开一个URL连接
12)使用BufferedReader包装InputStreamReader流
br = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));
13)正则匹配,通过Pattern.compile编译正则表达式
Matcher m = Pattern.compile("").matcher(buf);
根据获得的Matcher,取得title内容。
2)spiderURL 采集标题名连接
21)采集到新闻标题对应的href后,由于此href是相对地址,因此,加上网站域名,拼接成网站的URL链接。
3)goCopyContent采集内容
31)foreach ArrayList,将列表内容通过CopyContent循环抓取
4)CopyContent采集内容,使用Jsoup框架采集
41)设置post下载方式
doc = Jsoup.connect(con).userAgent("Mozilla/5.0").timeout(3000).post();
42)找到所有的p标签
Elements elements = doc.getElementsByTag("p");// 找到所有p标签
43)保存所有的正文内容saveArticle
5)文章保存saveArticle
保存方式:直接写文件到本地,然后将本机url存入数据库。简单,直接,爆炸,不用考虑磁盘空间情况,不用考虑文件读取速度,不用考虑性能。
File file = new File(src);
FileWriter fw = new FileWriter(file, true);
BufferedWriter bw = new BufferedWriter(fw);
bw.write(NewLinkHref);
6)Filedown 获取文章链接里面的链接,主要是图片
if (".pdf".equals() || ".doc" || ".zip" || ".xls" || ".rar" || ".jpg" || ".bmp")
// 下载附件
sqlPic = catchPic(picurl);
7)catchPic下载附件
import java.net.HttpURLConnection;
HttpURLConnection huc = (HttpURLConnection) url.openConnection();
BufferedInputStream bis = new BufferedInputStream(ips);
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream());
byte[] b = new byte[1024];
int len = 0;
// 将数据写入文件
while ((len = bis.read(b)) != -1) {
bos.write(b, 0, len);
// 刷新资源------write方法使用完需要刷新
bos.flush();
}
// 关闭流,释放资源
bos.close();
bis.close();
ips.close();
3、对这段逻辑的评价
1)这是一个中级Java程序员的开发成果
2)从这端代码过程中看,开发人员没有从理论上,来考虑程序逻辑和架构,在当前互联网行业,这是通用,且常见的软件开发方式。






 京公网安备 11010802041100号
京公网安备 11010802041100号