1.改进的二叉树多分类决策树算法
上层节点的分类性能对整个分类模型的影响较大,在分类过程中,应尽量减少上层节点的分类,提出类分离测度,将类分离测度大的属性作为二叉树的上层分叉节点,优先分离
参考:《改进的二叉决策树多分类算法在入侵检测中的应用》
2.多分类AdaBoost
多分类问题的Ada Boost.SAMME算法:α=1/2 * log(1 - e / e) + lg(k - 1) ,当k=2时,为二分类,在解决k(k>2)类问题时,算法正确率大于1/k即可
本文使用SVM(高斯核函数)做基分类器
参考:《基于多分类AdaBoost的航空发动机故障诊断》
3.AdaBoost改进随机森林
用AdaBoost算法来调整随机森林中的决策树对不同地物类别的投票权重, 将分类能力强的决策树赋予高权重, 分类能力弱的决策树赋予低权重, 最终通过加权投票的形式进行组合, 采用最大投票准则获得分类结果
参考:《基于AdaBoost改进随机森林的高光谱图像地物分类方法研究》
4.Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets
针对不平衡数据集,将数据分成4类,针对不同类别的数据点确定上采样

5. Diversity Analysis on Imbalanced Data Sets by Using Ensemble Models
1. 类别不平衡不能单纯的将少数类别的数量增加至相同数量,这可能会导致新的“内部”不平衡,提出一种计算方法,少数类应该生成多少样本(用在SMOTEBagging)

2. 每个类别应该上采样或下采样多上样本时,提出了一种方法(用在UnderBagging和OverBagging中):

2. 衡量生成样本的多样性和准确性(多样性有个公式)
3. 提出针对不平衡样本的UnderBagging、OverBagging、SMOTEBagging三种算法
多分类AdaBoost算法:
- AdaBoost.SAMME(多类指数损失函数逐步添加模型 Stagewise Additive Modeling using a Multi-class Exponential loss function):相比较与传统AdaBoost算法,改变的是弱分类器的权重确定公式:
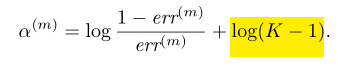 (注:sklearn)
(注:sklearn) - AdaBoost.M1
- AdaBoost.M2
- AdaBoost.MH
论文:《Muiti-class AdaBoost》
不平衡数据集的多分类AdaBoost
- EasyEnsemble:每个弱分类器,对多数类随机下采样与少数类样本相同数量的样本构成当前若分类器的数据集
- CaseCade:每个分类器,在数据集中移除上一个弱分类器分类正确的多数类中的样本,直至数据集平衡
- CUSBoost:k-means聚类采样与AdaBoostd算法结合。对多数类使用聚类算法,从每个聚类中随机抽取部分样本,与少数类样本组成平衡数据集。聚类的方法帮助我们在多数类别数据中选择了差异性更大的数据(同一个聚类里面的数据则选择的相对较少)。CUSBoost combines the sampling and boosting methods to form an efficient and effective algorithm for class imbalance learning.
- SMOTEBoost:SMOTE上采样方法与AdaBoost算法结合
- SAMME.R:为了解决 SAMME 算法对基分类器要求过弱的问题,对每次迭代训练出的弱分类器进行检验,判断各类中分到
每类样本的权值和,并且要求分到正确类的权值和大于分到任意错误类的权值和,如果满足该条件则保留该基分类器,否则重新训练新的基分类器。SAMME. R 算法的主要改进在于通过筛选基分类器保证算法训练出的强分类器可以分类正确 - SAMME.RD(SAMME with Resampling and Dynamic weighting):传统的 AdaBoost 算法对待测样本进行预测时各个分类器的加权系数是固定不变的,但是通过分析可以知道基分类器对不同的待测样本的分类能力是不一样的,这是因为基分类使用不同的训练集训练而来,它们对分布在不同区域的样本分类能力是不一样的。如果在预测时使用相同的加权系数,预测结果的准确性将会受到一定的影响,所以为了进一步提升算法的预测性能,动态加权投票,1)对基分类器的分类结果进行统计,统计分到各类的基分类器个数,如果分到某类的个数与基分类器总数的比值大于一个设定的阈值 α,则直接输出此类作为待测样本的类别。2) 对于分到各类的数目没有大于设定阈值 α 的情况,求出待测样本在训练样本中的有效邻域,统计基分类器对有效邻域中的样本的分类能力,根据基分类器对有效邻域分类正确率的大小来确定基分类器的加权系数。《基于多类指数损失函数逐步添加模型的改进多分类 AdaBoost 算法》
- EnsembleAdaBoost.M:针对EasyEnsemble算法中随机欠采样可能改变数据分布的问题,先采用样本均值的方法进行采样,使样本均衡

然后传统的 AdaBoost 分类器无法解决上采样产生的噪音数据降低分类性能的问题,引入了阈值 μ和惩罚次数 P 。当某个样本的权重超过 μ,则将该样本的权重赋值为所有样本中的最小权重,同时记为一次惩罚,增加惩罚次数 P n ,若被惩罚过的样本在下次迭代中样本权重依然超过 μ,则可以判断该样本为噪音数据,将其权重赋值为 0,从数据集中剔除掉。《基于多类不平衡分类的改进 AdaBoost 算法研究》
随机森林的改进:
- 引入分层抽样降低样本类别平衡率,代价敏感学习(样本加权)通过对样本权重赋值,能够提高分类器对小样本类的检测率和检测准确率《层次采样的代价敏感随机森林算法及其应用》
- MR-RF-SHDSE算法:分层抽样,针对不平衡数据集,采用G-mean值衡量决策树的强度,公式如下,

采用不合度量(disagreement measure)衡量两个决策树之间的相似度,计算公式如下:

目的是找到一个mapper下具有一定差异其具有一定轻度的决策树,选择方法如下:


《 MapReduce环境下处理多类别不平衡数据的改进随机森林算法》
- 基分类器选择BT-SVM(二叉树结构),自上至下选择类别时采用类间距离,距离大的先分离;在集成分类器中最重要的是如何综合个分类器的结果,常用的是简单投票,如随机森林,然而,当各分类器性能不统一时此种做法往往造成较大的负面效果,尤其在出现各类别得票数相差无几或多类得票数相同的情况时,如果还采用之前的简单投票进行预测,则预测准确性将大打折扣。采用动态加权,设定阈值,将待分类样本代入各个分类器,通过给定阈值判断是否加权,如果低于阈值,将进行动态加权给各个基分类器分配权。重本文利用 KNN思想,从样本中选出与待测样本相似的 K 个样本代入已训练好的分类器得到错分率,并利用错分率得到各个分类器的权重,最后进行线性加权,求出最优的识别结果。

时间序列特征提取的python库:tsfresh


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)









 京公网安备 11010802041100号
京公网安备 11010802041100号