Flink是什么
为什么选择Flink
lambda架构:先快速的得到一个近似的结果 在用batch layer慢一点得到正确的结果
流(stream)和微批(micro-batching) 底层的架构不一样
问题:如果要开始 处理 一开始 没有想过要处理的的数据,没有太大的办法.
因为flink是替代原架构的spark streaming的部分
晚上再测试一下
单节点的standalone 还有 多节点的standalone的 都需要测试的
Session-cluster模式:
开启命令: ./yarn-session.sh -s 2 -jm 1024 -tm 1024 -nm test -d
启动命令: ./flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with- dependencies.jar --host localhost –port 7777
Per-Job-cluster:比启动yarn-session 直接
略
什么是solt 怎么划分的
JobManager TaskManager ResourceManager Dispatcher
资源就是TaskManager上的slots
抽象的任务提交(下图):
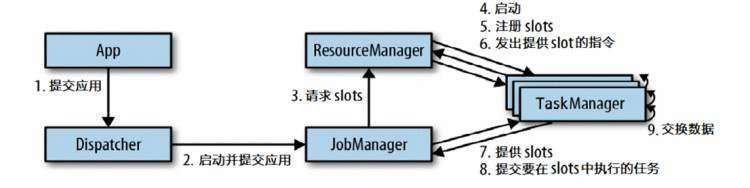
两个要求:one to one 和 要相同的并行度
https://github.com/wushengran/FlinkTutorial.git
总结 :
主要就是Flink中的窗口函数的使用 可以使用简单的timewindow 来进行滚动或者滑动窗口 或者 countwindow 还是比较简单的 (也可以使用window() 比较一般的方法 具体的方法可以在代码上查看)
然后还有一些可以使用的其他api
重要的有两点 第一: 当开窗的时候 后面一定需要使用Window function 来进行聚合 (增量聚合函数 或 全窗口函数)
window()接收的输入参数是一个 window Assigner 之后用窗口函数来返回成为DataStream
window Function
其他API
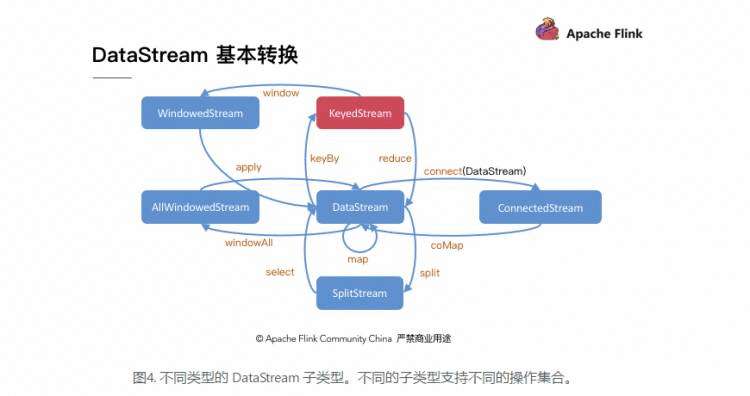

总结 :
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[](Time.second(1)){override def extractTimestamp(element: SensorReading): Long = {element.timestamp * 1000}
})
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
flink里面的思想 : 你需要自己做权衡
底层有公式 " timestamp - (timestamp -offset + size) % size"
总结 :
processElement(v: IN, ctx: Context, out: Collector[OUT]),
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT]) 是一个回调函数
Context和OnTimerContext所持有的TimerService对象拥有以下方法:
val monitoredReadings: DataStream[SensorReading] = readings.process(new FreezingMonitor)monitoredReadings.getSideOutput(new OutputTag[String]("freezing-alarms")).print()readings.print()class FreezingMonitor extends ProcessFunction[SensorReading, SensorReading] {// 定义一个侧输出标签lazy val freezingAlarmOutput: OutputTag[String] =new OutputTag[String]("freezing-alarms")override def processElement(r: SensorReading,ctx: ProcessFunction[SensorReading, SensorReading]#Context,out: Collector[SensorReading]): Unit = {// 温度在32F以下时,输出警告信息if (r.temperature < 32.0) {ctx.output(freezingAlarmOutput, s"Freezing Alarm for ${r.id}")}// 所有数据直接常规输出到主流out.collect(r)}
}
对于两条输入流,DataStream API提供了CoProcessFunction这样的low-level操作。CoProcessFunction提供了操作每一个输入流的方法: processElement1()和processElement2()。
类似于ProcessFunction,这两种方法都通过Context对象来调用。这个Context对象可以访问事件数据,定时器时间戳,TimerService,以及side outputs。CoProcessFunction也提供了onTimer()回调函数。
val sensorData: DataStream[SensorReading] = ...
val keyedData: KeyedStream[SensorReading, String] = sensorData.keyBy(_.id)val alerts: DataStream[(String, Double, Double)] = keyedData
.flatMap(new TemperatureAlertFunction(1.7))class TemperatureAlertFunction(val threshold: Double) extends RichFlatMapFunction[SensorReading, (String, Double, Double)] {
private var lastTempState: ValueState[Double] = _override def open(parameters: Configuration): Unit = {
val lastTempDescriptor = new ValueStateDescriptor[Double]("lastTemp", classOf[Double])
lastTempState = getRuntimeContext.getState[Double](lastTempDescriptor)
}override def flatMap(reading: SensorReading,
out: Collector[(String, Double, Double)]): Unit = {
val lastTemp = lastTempState.value()
val tempDiff = (reading.temperature - lastTemp).abs
if (tempDiff > threshold) {
out.collect((reading.id, reading.temperature, tempDiff))
}
this.lastTempState.update(reading.temperature)
}
}
快照的时间 : 所有任务都恰好处理完一个相同的输入数据的时候
source要重置发生故障之前的授予数据
基于Chandy-Lamport算法的分布式快照 : 将检查点的保存和数据处理分离开 , 不暂停整个应用
Savepoints : 自定义的镜像保存功能
状态的存储 维护以及访问,有一个可插入的组件决定,这个组件就是State Backends
那就需要保存,保存就是checkpoint ,还要有容错机制
MemoryStateBackend
FsStateBackend
RocksDBStateBackend
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors._
这三个要隐式转换的 要有印象 不然会忘记了
Table API 和 Flink SQL 是什么
引入的依赖
<dependency><groupId>org.apache.flinkgroupId><artifactId>flink-table-planner_2.12artifactId><version>1.10.1version>
dependency><dependency><groupId>org.apache.flinkgroupId><artifactId>flink-table-api-scala-bridge_2.12artifactId><version>1.10.1version>
dependency>
catalog : 高层级目录 catalog.database.table
版本不同有 oldPlanner 和 BlinkPlanner的区别 : blink批流统一
连接外部系统的时候 source 和 sink 其实差不多
创建表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SQMuX52L-1599569101105)(https://raw.githubusercontent.com/tanzhongjingyue/OSS/master/img/image-20200904140838828.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kzka9xCI-1599569101107)(https://raw.githubusercontent.com/tanzhongjingyue/OSS/master/img/image-20200904140919877.png)]
输出表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZpG2duuT-1599569101108)(https://raw.githubusercontent.com/tanzhongjingyue/OSS/master/img/image-20200904141006912.png)]
更新模式



table转换成DataStream 有两种模式 : Append Mode和 Retract Mode
流处理和关系代数的区别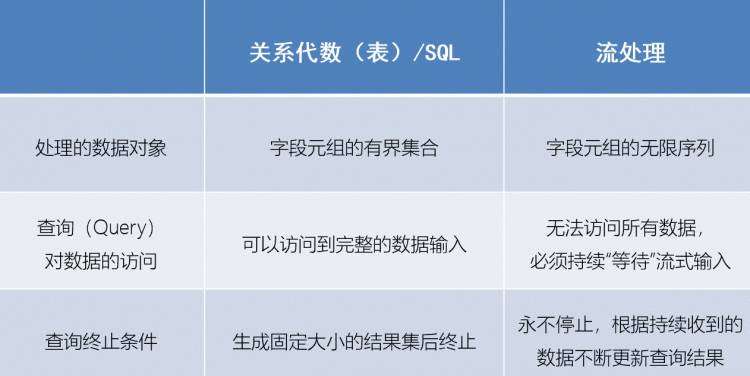
val table = input.window([w: GroupWindow] as 'w) // 定义窗口,别名 w.groupBy('w, 'a) // 以属性a和窗口w作为分组的key .select('a, 'b.sum) // 聚合字段b的值,求和或者,还可以把窗口的相关信息,作为字段添加到结果表中:val table = input.window([w: GroupWindow] as 'w) .groupBy('w, 'a) .select('a, 'w.start, 'w.end, 'w.rowtime, 'b.count)
Table API提供了一组具有特定语义的预定义Window类,这些类会被转换为底层DataStream或DataSet的窗口操作
滚动窗口
// Tumbling Event-time Window(事件时间字段rowtime)
.window(Tumble over 10.minutes on 'rowtime as 'w)// Tumbling Processing-time Window(处理时间字段proctime)
.window(Tumble over 10.minutes on 'proctime as 'w)// Tumbling Row-count Window (类似于计数窗口,按处理时间排序,10行一组)
.window(Tumble over 10.rows on 'proctime as 'w)
滑动窗口
// Sliding Event-time Window
.window(Slide over 10.minutes every 5.minutes on 'rowtime as 'w)// Sliding Processing-time window
.window(Slide over 10.minutes every 5.minutes on 'proctime as 'w)// Sliding Row-count window
.window(Slide over 10.rows every 5.rows on 'proctime as 'w)
会话窗口
// Session Event-time Window
.window(Session withGap 10.minutes on 'rowtime as 'w)// Session Processing-time Window
.window(Session withGap 10.minutes on 'proctime as 'w)
写法 :
无界的over Windows
// 无界的事件时间over window (时间字段 "rowtime")
.window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)//无界的处理时间over window (时间字段"proctime")
.window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)// 无界的事件时间Row-count over window (时间字段 "rowtime")
.window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)//无界的处理时间Row-count over window (时间字段 "rowtime")
.window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
有界的over Windows
api操作 :
// 有界的事件时间over window (时间字段 "rowtime",之前1分钟)
.window(Over partitionBy 'a orderBy 'rowtime preceding 1.minutes as 'w)// 有界的处理时间over window (时间字段 "rowtime",之前1分钟)
.window(Over partitionBy 'a orderBy 'proctime preceding 1.minutes as 'w)// 有界的事件时间Row-count over window (时间字段 "rowtime",之前10行)
.window(Over partitionBy 'a orderBy 'rowtime preceding 10.rows as 'w)// 有界的处理时间Row-count over window (时间字段 "rowtime",之前10行)
.window(Over partitionBy 'a orderBy 'proctime preceding 10.rows as 'w)
我们已经了解了在Table API里window的调用方式,同样,我们也可以在SQL中直接加入窗口的定义和使用。
SELECT COUNT(amount) OVER (PARTITION BY userORDER BY proctimeROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
FROM Orders
todo 要补充
注册用户自定义函数UDF
标量函数(Scalar Functions)
只能输出单值
扩展基类 ScalaFunction , 写public的eval方法
class HashCode( factor: Int ) extends ScalarFunction {def eval( s: String ): Int = { s.hashCode * factor }}
表函数
返回任意数量的行(输出一张表)
扩展TableFunction , 写public的eval方法
class Split(separator: String) extends TableFunction[(String, Int)]{def eval(str: String): Unit = {str.split(separator).foreach(word => collect((word, word.length)))}}
聚合函数
表聚合函数
略
略
略








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有