1、文件准备
在项目的resource目录下创建一个words文件

文件内容:
hello word
hello scala
hello flink
hello spark
2、数据处理
文件准备后,开始读取文件,将处理后数据输出到目标文件中
代码:
object Wordcount {def main(args: Array[String]): Unit = {//创建环境变量val env = StreamExecutionEnvironment.getExecutionEnvironment//设置并行为1env.setParallelism(1)//文件路径val filePath="D:\\BBQ\\bigdata-dm\\flinkemo\\src\\main\\scala\\resource\\words.txt"//读取文件val inputDS=env.readTextFile(filePath)//分词统计import org.apache.flink.api.scala._val wordcountDS =inputDS.flatMap(_.split(" ")).map((_, 1)).keyBy(0).sum(1)wordcountDS.print()wordcountDS.writeAsText("D:\\BBQ\\bigdata-dm\\flinkemo\\src\\main\\scala\\resource\\result.txt")env.execute()}
}
结果:
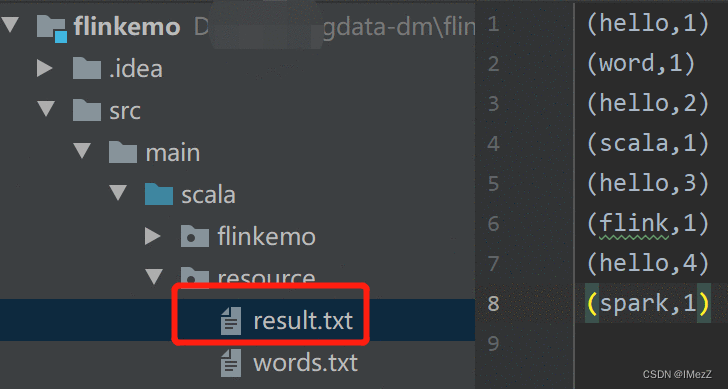
3、 结论:
可以看到resource目录下生成了一个result.txt文件,文件内容是按代码逻辑处理过的结果。





 京公网安备 11010802041100号
京公网安备 11010802041100号