篇首语:本文由编程笔记#小编为大家整理,主要介绍了Flink+zookeeper安装部署!相关的知识,希望对你有一定的参考价值。
设备准备:
节点 ip地址 系统 软件 磁盘
node1 192.168.0.11 centos7 flink,zookeeper,hadoop 40G+100G
node2 192.168.0.22 centos7 flink,zookeeper,hadoop 40G+100G
node3 192.168.0.33 centos7 flink,zookeeper,hadoop 40G+100G
systemctl stop firewalld
setenforce 0
##添加地址映射
vim /etc/hosts
192.168.0.11 node1
192.168.0.12 node2
192.168.0.13 node3
##三节点做免交互
ssh-keygen
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
##安装java环境,可以先java -version查看版本,如果匹配可以不用安装
yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel
zookeeper部署
[root@node1 ~]# vi /etc/wgetrc
check_certificate = off #末尾添加
##下载zookeeper包
[root@node1 ~]# wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
[root@node1 ~]# tar zxf apache-zookeeper-3.7.0-bin.tar.gz -C /opt #解压包到opt下
[root@node1 ~]# cd /opt/apache-zookeeper-3.7.0-bin/conf/
[root@node1 conf]# mv zoo_sample.cfg zoo.cfg #给配置文件改名
[root@node1 conf]# vi zoo.cfg #设置配置文件
dataDir=/opt/zk_datadir #这里更改,下面是添加内容
server.1=192.168.0.11:2888:3888
server.2=192.168.0.12:2888:3888
server.3=192.168.0.13:2888:3888
[root@node1 conf]# mkdir /opt/zk_datadir #创建目录
##三节点设置myid,
node1: echo 1 > /opt/zk_datadir/myid
node2: echo 2 > /opt/zk_datadir/myid
node3: echo 3 > /opt/zk_datadir/myid
##设置环境变量
[root@node1 conf]# cd /root
[root@node1 ~]# vim .bash_profile
PATH=$PATH:$HOME/bin:/opt/apache-zookeeper-3.7.0-bin/bin #这行后面添加内容
[root@node1 ~]# source .bash_profile
##启动zookeeper
[root@node1 ~]# zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
##连接zookeeper集群查看
[root@node1 ~]# zkCli.sh -server 192.168.0.11:2181,192.168.0.12:2181,192.168.0.12:2181
ls /
[zookeeper]
[zk: 192.168.0.11:2181,192.168.0.12:2181,192.168.0.12:2181(CONNECTED) 2]
quit
部署hadoop
##下载hadoop软件包
[root@node1 ~]# cd /opt
[root@node1 opt]# wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
[root@node1 opt]# tar xzf hadoop-3.2.2.tar.gz #解压
##格式化分区,挂载
[root@node1 opt]# fdisk /dev/vdb
n
p
回车
回车
w
[root@node1 opt]# mkdir /data01
[root@node1 opt]# mkfs.xfs /dev/vdb1
[root@node1 opt]# mount /dev/vdb1 /data01
[root@node1 opt]# vim /etc/fstab
/dev/vdb1 /data01 xfs defaults 0 0
[root@node1 opt]# mount -a
[root@node1 opt]# df -h | grep vdb1
/dev/vdb1 100G 33M 100G 1% /data01
[root@node1 opt]# vi hadoop-3.2.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
</configuration>
[root&#64;node1 opt]# vi /opt/hadoop-3.2.2/etc/hadoop/hadoop-env.sh #末尾添加以下内容
export HDFS_NAMENODE_USER&#61;root
export HDFS_JOURNALNODE_USER&#61;root
export HDFS_ZKFC_USER&#61;root
export JAVA_HOME&#61;/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64
[root&#64;node1 opt]# vi /opt/hadoop-3.2.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.node1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.node2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.node3</name>
<value>node3:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node1</name>
<value>node1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node2</name>
<value>node2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node3</name>
<value>node3:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jorunal_data</value>
</property>
<property>
<name>dfs.ha.nn.not-become-active-in-safemode</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data01/nn</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop-3.2.2/etc/hadoop/dfs.hosts</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data01/data</value>
</property>
</configuration>
[root&#64;node1 opt]# vi /opt/hadoop-3.2.2/etc/hadoop/dfs.hosts
node1
node2
node3
##添加环境变量
[root&#64;node1 opt]# vim /root/.bash_profile
PATH&#61;$PATH:$HOME/bin:/opt/apache-zookeeper-3.7.0-bin/bin:/opt/hadoop-3.2.2/bin:/opt/hadoop-3.2.2/sbin
[root&#64;node1 opt]# source /root/.bash_profile
##启动journalnode
node1&#xff1a;
[root&#64;node1 opt]# hdfs zkfc -formatzk
[root&#64;node1 opt]# hdfs --daemon start journalnode
[root&#64;node1 opt]# jps
8497 QuorumPeerMain
8754 JournalNode
8796 Jps
894 WrapperSimpleApp
node2&#xff0c;3&#xff1a;
[root&#64;node2 opt]# hdfs --daemon start journalnode
WARNING: /opt/hadoop-3.2.2/logs does not exist. Creating.
[root&#64;node3 opt]# hdfs --daemon start journalnode
WARNING: /opt/hadoop-3.2.2/logs does not exist. Creating.
##启动zkfc
node1&#xff1a;
[root&#64;node1 opt]# hdfs zkfc -formatZK
[root&#64;node1 opt]# hdfs --daemon start zkfc
[root&#64;node1 opt]# jps
8497 QuorumPeerMain
8754 JournalNode
8915 DFSZKFailoverController
8947 Jps
894 WrapperSimpleApp
node2&#xff0c;3:
[root&#64;node2 opt]# hdfs --daemon start zkfc
[root&#64;node2 opt]# jps
870 WrapperSimpleApp
8701 JournalNode
8493 QuorumPeerMain
8814 Jps
8782 DFSZKFailoverController
[root&#64;node3 opt]# hdfs --daemon start zkfc
##启动namenode
node1&#xff1a;
[root&#64;node1 opt]# hdfs namenode -format
[root&#64;node1 opt]# hdfs --daemon start namenode
[root&#64;node1 opt]# jps
19504 Jps
19409 NameNode
8497 QuorumPeerMain
8754 JournalNode
8915 DFSZKFailoverController
894 WrapperSimpleApp
node2&#xff0c;3&#xff1a;
[root&#64;node2 opt]# hdfs --daemon start namenode -bootstrapstandby
[root&#64;node2 opt]# hdfs --daemon start namenode
namenode is running as process 8870. Stop it first.
[root&#64;node2 opt]# jps
870 WrapperSimpleApp
8870 NameNode
8935 Jps
8701 JournalNode
8493 QuorumPeerMain
8782 DFSZKFailoverController
##启动datanode&#xff0c;三节点同时进行&#xff0c;下面只显示node1
[root&#64;node1 opt]# hdfs --daemon start datanode
[root&#64;node1 opt]# jps
19409 NameNode
8497 QuorumPeerMain
8754 JournalNode
8915 DFSZKFailoverController
19560 DataNode
19628 Jps
894 WrapperSimpleApp
[root&#64;node1 opt]# hdfs dfs -put /var/log/messages /
[root&#64;node1 opt]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 125075 2021-10-05 14:24 /messages
部署flink
[root&#64;node1 opt]# tar xzf flink-1.13.1-bin-scala_2.11.tgz
[root&#64;node1 opt]# cd /opt/flink-1.13.1/bin/
[root&#64;node1 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host ecs-edfe-0001.
Starting taskexecutor daemon on host ecs-edfe-0001.
[root&#64;node1 bin]# netstat -antp | grep 8081
tcp6 0 0 :::8081 :::* LISTEN 20133/java
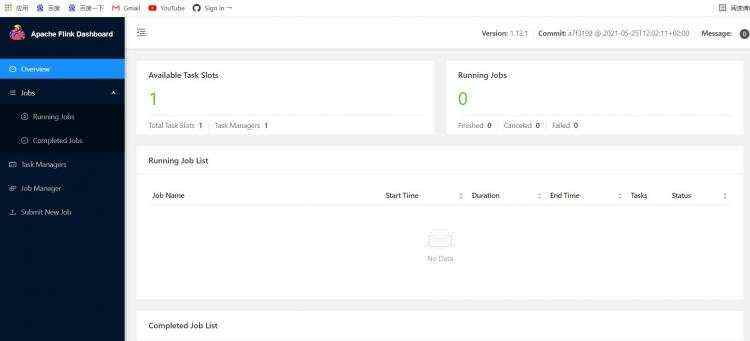
[root&#64;node1 bin]# cd /opt/flink-1.13.1
[root&#64;node1 flink-1.13.1]# bin/flink run ./examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 4d1ff2a2f0b97b4eeb0c0a5aa7deabd7
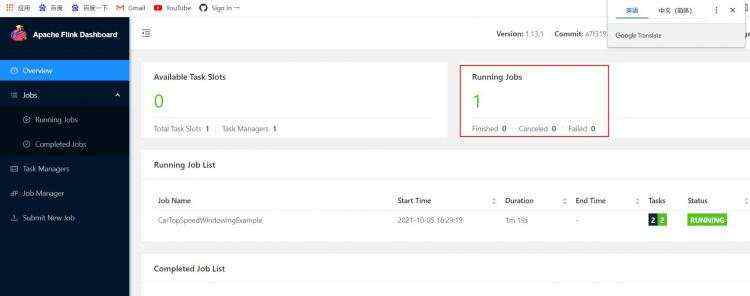
##先关闭flink&#xff08;因为前面运行过&#xff0c;它一直在采取数据&#xff09;
[root&#64;node1 bin]# ./stop-cluster.sh
[root&#64;node1 bin]# ./start-cluster.sh
##重开一个node1终端&#xff0c;下载netcat
[root&#64;node1 flink-1.13.1]# nc -l 9000 ##执行命令&#xff0c;持续传输数据
##回node1节点执行命令采取数据
[root&#64;node1 flink-1.13.1]# bin/flink run ./examples/streaming/SocketWindowWordCount.jar --port 9000
Job has been submitted with JobID 440b3d6c0e5596c444f5fb3a33b7594c
##在node1新终端上输入aaa
[root&#64;node1 flink-1.13.1]# nc -l 9000
aaa
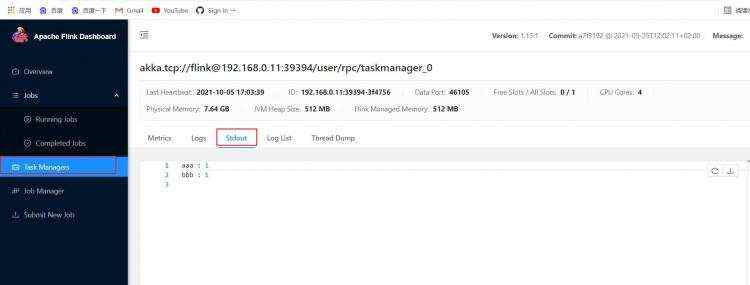
##在node2节点远程登录node1&#xff0c;查看日志文件
[root&#64;node2 bin]# ssh node1
[root&#64;node1 ~]# tail -f /opt/flink-1.13.1/log/flink-root-taskexecutor-0-ecs-edfe-0001.out
aaa : 1








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有