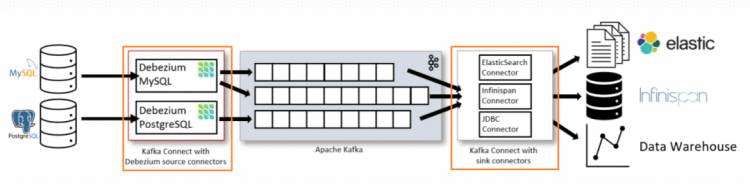
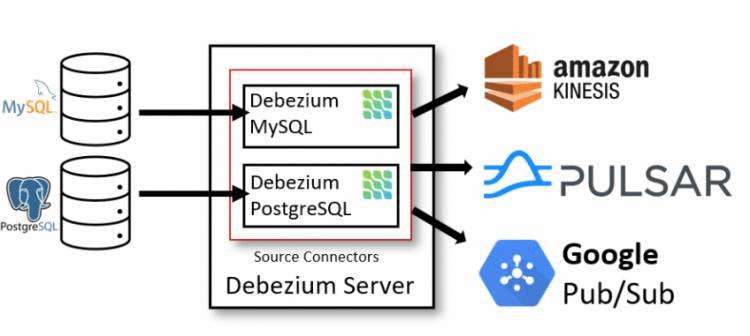
一、Debezium 介绍Debezium 是一个分布式平台,它将现有的数据库转换为事件流,应用程序消费事件流,就可以知道数据库中的每一个行级更改,并立即做出响应。 Debezium 构建在 Apache Kafka 之上,并提供 Kafka 连接器来监视特定的数据库。在介绍 Debezium 之前,我们要先了解一下什么是 Kafka Connect。 二、Kafka Connect 介绍Kafka 相信大家都很熟悉,是一款分布式,高性能的消息队列框架。 一般情况下,读写 Kafka 数据,都是用 Consumer 和 Producer Api 来完成,但是自己实现这些需要去考虑很多额外的东西,比如管理 Schema,容错,并行化,数据延迟,监控等等问题。 而在 0.9.0.0 版本之后,官方推出了 Kafka Connect ,大大减少了程序员的工作量,它有下面的特性: REST 接口,用来查看和管理Kafka connectors; 自动化的offset管理,开发人员不必担心错误处理的影响; Kafka Connect 有两个核心的概念:Source 和 Sink,Source 负责导入数据到 Kafka,Sink 负责从 Kafka 导出数据,它们都被称为是 Connector。 如下图,左边的 Source 负责从源数据(RDBMS,File等)读数据到 Kafka,右边的 Sinks 负责从 Kafka 消费到其他系统。 三、Debezium 架构和实现原理Debezium 有三种方式可以实现变化数据的捕获 以插件的形式,部署在 Kafka Connect 上 在上图中,中间的部分是 Kafka Broker,而 Kafka Connect 是单独的服务,需要下载 debezium-connector-mysql 连接器,解压到服务器指定的地方,然后在 connect-distribute.properties 中指定连接器的根路径,即可使用。 这种模式中,需要配置不同的连接器,从源头处捕获数据的变化,序列化成指定的格式,发送到指定的系统中。 内嵌模式,既不依赖 Kafka,也不依赖 Debezium Server,用户可以在自己的应用程序中,依赖 Debezium 的 api 自行处理获取到的数据,并同步到其他源上。 四、使用 Docker 来安装 Debezium Kafka Mysql这里我们使用官网提供的 Docker 方式快速的搭建一个演示环境。 Docker 的安装和基本命令,可以参考我之前的文章或者在网上找相关的教程。 1. 首先获取一个 zk 的镜像 docker pull debezium/zookeeper以 daemo 的方式运行镜像,并且暴露 2181,2888,3888 端口
docker run -d -it --rm --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper--rm 表示容器停止后删除本地数据
2. 获取一个 kafka 的镜像 docker pull debezium/kafka
docker run -d -it --rm --name kafka -p 9092:9092 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.10:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 --link zookeeper:zookeeper debezium/kafka--link 表示可以和 zookeeper 容器互相通信
3. 拉取一个 mysql 的镜像 docker pull debezium/example-mysql
在后台执行 mysql 的镜像
docker run -d -it --rm --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql
4. 单独开一个 shell 进入 mysql 的命令行中 docker run -it --rm --name mysqlterm --link mysql --rm debezium/example-mysql sh -c 'exec mysql -h"$MYSQL_PORT_3306_TCP_ADDR" -P"$MYSQL_PORT_3306_TCP_PORT" -uroot -p"$MYSQL_ENV_MYSQL_ROOT_PASSWORD"'
5 拉取一个 debezium/connect 的镜像 docker pull debezium/connect
启动 kafka connect 服务
docker run -d -it --rm --name connect -p 8083:8083 -e GROUP_ID=1 -e CONFIG_STORAGE_TOPIC=my_connect_configs -e OFFSET_STORAGE_TOPIC=my_connect_offsets -e STATUS_STORAGE_TOPIC=my_connect_statuses --link zookeeper:zookeeper --link kafka:kafka --link mysql:mysql debezium/connect
启动之后,我们可以使用 rest api 来检查 Kafka Connect 的服务状态
curl -H "Accept:application/json" localhost:8083/
{"version":"2.6.0","commit":"62abe01bee039651","kafka_cluster_id":"vkx8c6lhT1emLtPSi-ge6w"}
使用 rest api 来查看有多少 connect 服务注册到 Kafka Connect 上了
curl -H "Accept:application/json" localhost:8083/connectors/
现在会返回一个空数组,表示还没有服务注册上去。
6 注册一个 Connector 去检测 mysql 数据库的变化 注册的话,需要往 Kafka Connect 的 rest api 发送一个 Post 请求,请求内容如下 3 task 最大数量,应该配置成 1,因为 Mysql 的 Connector 会读取 Mysql 的 binlog,使用单一的任务才能保证合理的顺序; 4 这里配置的是 mysql,其实是一个 host,如果非 docker 环境,则要配置成 ip 地址或者可以解析的域名; 5 唯一的 serverId,会被作为 Kafka Topic 的前缀; 执行下面的命令发送一个 Post 请求,注册到 Kafka Connect 上: curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "mysql", "database.port": "3306", "database.user": "debezium", "database.password": "dbz", "database.server.id": "184054", "database.server.name": "dbserver1", "database.include.list": "inventory", "database.history.kafka.bootstrap.servers": "kafka:9092", "database.history.kafka.topic": "dbhistory.inventory" } }'
7 新开一个 shell,启动一个 Kafka 的消费者,来查看 Debezium 发送过来的事件 docker run -it --rm --name watcher --link zookeeper:zookeeper --link kafka:kafka debezium/kafka watch-topic -a -k dbserver1.inventory.customers
8 在 mysql 的命令行窗口上,修改一条数据 use inventory;UPDATE customers SET first_name='Anne211' WHERE id =1004 ;
9 观察 kafka 消费者窗口的变化 发现会发送过来两条 json,一条是更新的哪个主键,一条是具体的更新内容
五、Flink 集成 Debezium 同步数据下面我们使用 Flink 来消费 Debezium 产生的数据,把变更的数据都同步到另外一张表中。主要步骤有: package com.hudsun.flink.cdc;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.SqlDialect;import org.apache.flink.table.api.TableResult;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/**@Author wangkai@Time 2020/12/22 23:11 public class DebeziumCDC public static void main (String[] args) throws Exception // debezium 捕获到变化的数据会写入到这个 topic 中 "dbserver1.inventory.customers" ;"192.168.56.10:9092" ;"testGroup" ;// 目标数据库地址 "jdbc:mysql://192.168.56.10:3306/inventory" ;"root" ;"debezium" ;"customers_copy" ;// 创建一个 Kafka 数据源的表 "CREATE TABLE customers (\n" +" id int,\n" +" first_name STRING,\n" +" last_name STRING,\n" +" email STRING \n" +") WITH (\n" +" 'connector' = 'kafka',\n" +" 'topic' = '" + topicName + "',\n" +" 'properties.bootstrap.servers' = '" + bootStrpServers + "',\n" " 'debezium-json.schema-include' = 'true',\n" +" 'properties.group.id' = '" + groupID + "',\n" +" 'format' = 'debezium-json'\n" +")" );// 创建一个写入数据的 sink 表 "CREATE TABLE customers_copy (\n" +" id int,\n" +" first_name STRING,\n" +" last_name STRING,\n" +" email STRING, \n" +" PRIMARY KEY (id) NOT ENFORCED\n" +") WITH (\n" +" 'connector' = 'jdbc',\n" +" 'url' = '" + url + "',\n" +" 'username' = '" + userName + "',\n" +" 'password' = '" + password + "',\n" +" 'table-name' = '" + mysqlSinkTable + "'\n" +")" );"insert into customers_copy select * from customers" ;"sync-flink-cdc" );
最后的最后,推荐进我的微信群,每天都有在更新干货,公众号回复:进群,即可。













 京公网安备 11010802041100号
京公网安备 11010802041100号