系列文章
- .Net微服务实战之技术选型篇
- .Net微服务实战之技术架构分层篇
- .Net微服务实战之DevOps篇
- .Net微服务实战之负载均衡(上)
- .Net微服务实战之CI/CD
- .Net微服务实战之Kubernetes的搭建与使用
- .Net微服务实战之负载均衡(下)
- .Net微服务实战之必须得面对的分布式问题
前言
很多次去面试,有经验的面试官都会问一个问题,你是怎么去定位日常遇到的问题?平常跟同行分享自己遇到的问题,事后他会问我,这种看起来毫无头绪的问题,你是怎么去定位解决的?
其实我们平常不知道怎么问题出在哪,主要是所了解的信息量不足,那么怎么才能提高给咱们定位问题的信息量呢?其实上面两个问题的答案都是同一个:日志、指标、跟踪。
有日志记录才能清楚知道当前系统的运行状况和具体问题;指标是给与后续做优化和定位偶发性问题的一些参考,没指标参考就没标准;我们平常做得多的调试、查看调用栈也是跟踪的一种,但是在分布式时代,更多考量的是跨进程通信的调用链路。
日志、指标、跟踪三者结合起来有一种统称——可观测性
运维是架构的地基,我第一次看到这句是在张辉清写的《小团队构建大网站:中小研发团队架构实践》,说实话,我非常的认同。不少小团队的运维都是由开发兼职的,而团队的运维能力决定了日后架构选型与日常维护。有良好的运维监控体系,就有足够的信息量提供给开发人员进行定位排错。
可观测性
可观测性的意思是可以由系统的外部输出推断其内部状态的程度,在软件系统中,可观察性是指能够收集有关程序执行、模块内部状态以及组件之间通信的数据。分别由三个方向组成:日志(logging)、跟踪( tracing)、指标(Metrics)《Metrics, tracing, and logging》
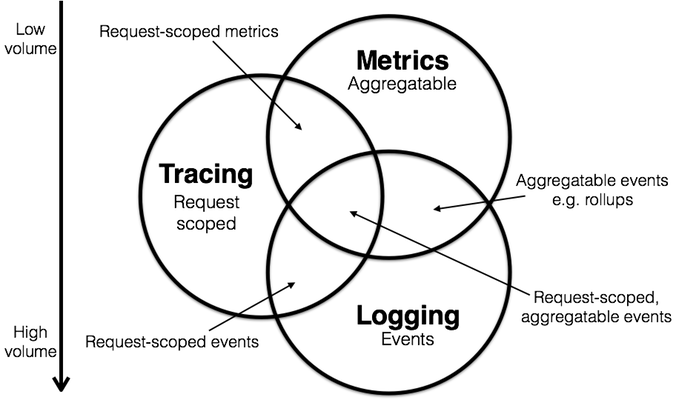
日志(logging)
日志的定义特征是它记录离散事件,目的是通过这些记录后分析出程序的行为。
例如:应用程序调试或错误消息通过转换文件描述,通过 syslog 发送到 Elasticsearch;审计跟踪事件通过 Kafka 推送到 BigTable 等数据存储;或从服务调用中提取并发送到错误跟踪服务(如 NewRelic)的特定于请求的元数据。
跟踪( tracing)
跟踪的定义特征是它处理请求范围内的信息,目的是排查故障。
在系统中执行的单个事务对象生命周期里,所绑定的数据或元数据。例如:RPC远程服务调用的持续时间;请求到数据库的实际 SQL 查询语句;HTTP 请求入站的关联 ID。
指标(Metrics)
指标的定义特征是它们是可聚合的,目的是监控和预警。
这些指标在一段时间内,能组成单个逻辑仪表、计数器或直方图。例如:队列的当前长度可以被建模为一个量规;HTTP 请求的数量可以建模为一个计数器,更新后通过简单的加法聚合计算;并且可以将观察到的请求持续时间建模为直方图,更新汇总到某个时间段中并建立统计摘要。
代表性产品
日志(logging)基本上是ELK (ElasticSearch, Logstash, Kibana) 技术栈一家独大了,但是Logstash比较重量级的,而轻量级的Filebeat可能更加受大家的青睐。下文里的实战部分,我是以EFK(ElasticSearch, Filebeat, Kibana)演示。
跟踪( tracing)相比于日志就是百花齐放了,Skywalking、zipkin、鹰眼、jeager、Datadog等等……但是在.Net的技术栈里,能提供出SDK的相对会少,所以选择也会少一些,我在之前的实战和下文的演示都是用Skywalking,主要优势无侵入。
指标(Metrics)在云生时代Prometheus比Zabbix更加受大家欢迎,同时Prometheus社区活跃度也占非常大的优势。下文实战部分我以Prometheus 作为演示。
ElasticSearch部署与安装
后面的Skywaking和日志都需要用到ElasticSearch,所以我把部署流程优先提了出来。
导入 GPG key
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
添加源
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md
重新加载
yum makecache
安装
sudo yum install -y --enablerepo=elasticsearch elasticsearch
修改配置
vim /etc/elasticsearch/elasticsearch.yml
network.host: 0.0.0.0 discovery.type: single-node
启动
/sbin/chkconfig --add elasticsearch sudo -i service elasticsearch start systemctl enable elasticsearch.service
用浏览器访问,能出现下图就是可以了
Prometheus与Grafana实现指标
架构简析
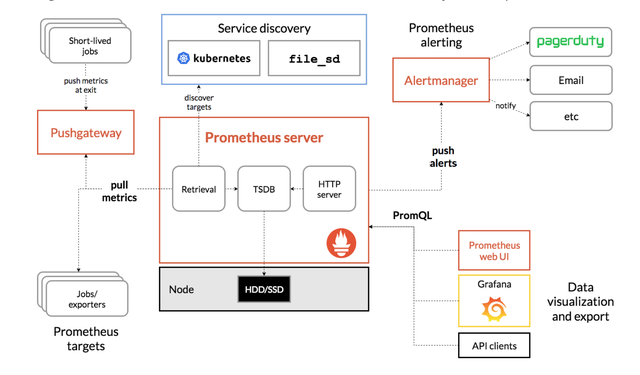
核心组件
Prometheus server
Prometheus的主程序,本身也是一个时序数据库,它来负责整个监控集群的数据拉取、处理、计算和存储,是使用pull方式由服务端主动拉取监控数据。
Alertmanager
Prometheus的告警组件,负责整个集群的告警发送、分组、调度、警告抑制等功能。 需要知道的是alertmanager本身是不做告警规则计算的,简单来说就是,alertmanager不去计算当前的监控取值是否达到我设定的阈值,上面已经提过该部分规则计算是prometheus server来计算的,alertmanager监听prometheus server发来的消息,然后在结合自己的配置,比如等待周期,重复发送告警时间,路由匹配等配置项,然后把接收到的消息发送到指定的接收者。同时他还支持多种告警接收方式,常见的如邮件、企业微信、钉钉等。1.3
Pushgateway
Pushgateway 它是prometheus的一个中间网管组件,类似于zabbix的zabbix-proxy。它主要解决的问题是一些不支持pull方式获取数据的场景,比如:自定义shell脚本来监控服务的健康状态,这个就没办法直接让prometheus来拉数据,这时就可以借助pushgateway,它是支持推送数据的,我们可以把对应的数据按照prometheus的格式推送到pushgateway,然后配置prometheus server拉取pushgateway即可。
UI
Grafana、prometheus-ui是用来图形化展示数据的组件,其中prometheus-ui是prometheus项目原生的ui界面,但是在数据展示方面不太好用,因此推荐grafana来展示你的数据,grafana支持prometheus的PromQL语法,能够和prometheus数据库交互,加上grafana强大的ui功能,我们可以很轻松的获取到很多好看的界面,同时也有很多做好的模版可以使用。
Prometheus Target
采集指标的API,有不同的Exporter,如果redis、mysql、server nodel提供给Prometheus server定时pull数据到数据库。
安装Prometheus
mkdir /var/prometheus docker run -d --name=prometheus -p 9090:9090 prom/prometheus docker cp prometheus:/etc/prometheus/prometheus.yml /var/prometheus/
删除之前的容器
docker run -d --name=prometheus -p 9090:9090 -v /var/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
到浏览器输入地址访问,出现以下页面则成功
安装Grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
安装完成后,使用admin/admin登录
安装Node Exporter
docker run -d -p 9100:9100 \ -v "/proc:/host/proc:ro" \ -v "/sys:/host/sys:ro" \ -v "/:/rootfs:ro" \ --net="host" \ --restart always \ prom/node-exporter
到浏览器输入地址访问(http://192.168.184.129:9100/metrics),出现以下页面则成功
配置Prometheus
vim /var/prometheus/prometheus.yml
添加以下配置 (注意格式)
配置Grafana
添加数据源

导入模板,其他模板可以到 https://grafana.com/grafana/dashboards 查看
确认后则生成(注意修改主机名)
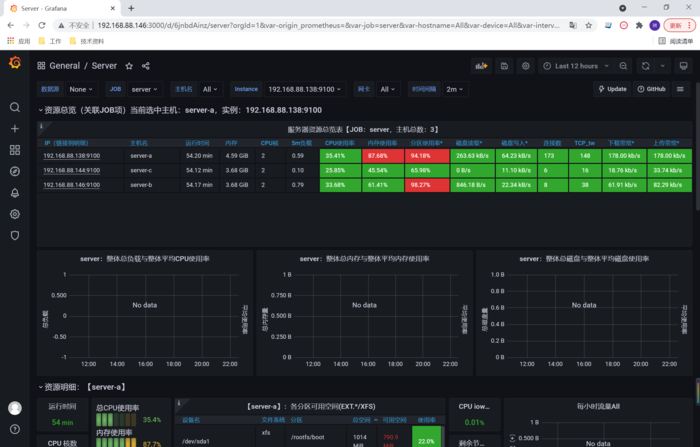
到这里完整的一次监控就完成,我们可以根据上诉的步骤添加容器和docker的监控。
使用Docker Exporter监控容器
用docker进行安装
docker run --name docker_exporter --detach --restart always --volume "/var/run/docker.sock":"/var/run/docker.sock" --publish 9417:9417 prometheusnet/docker_exporter
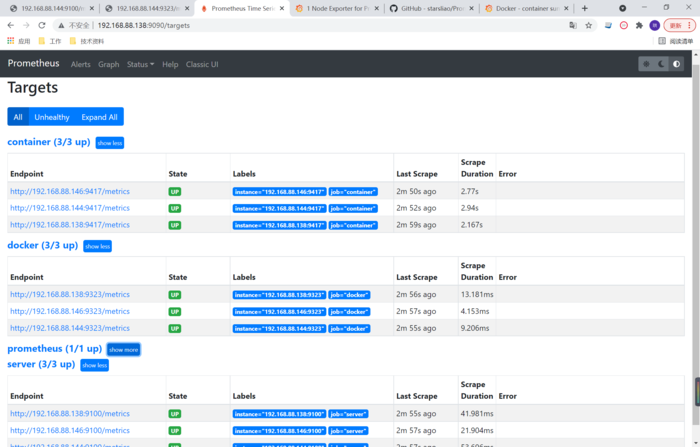
在Prometheus进行配置,添加下面配置项
vim /var/prometheus/prometheus.yml
- job_name: "container" static_configs: - targets: ["192.168.88.138:9417"]
在grafana根据上面node-exporter的步骤进行导入对应的模板 https://grafana.com/grafana/dashboards/11467
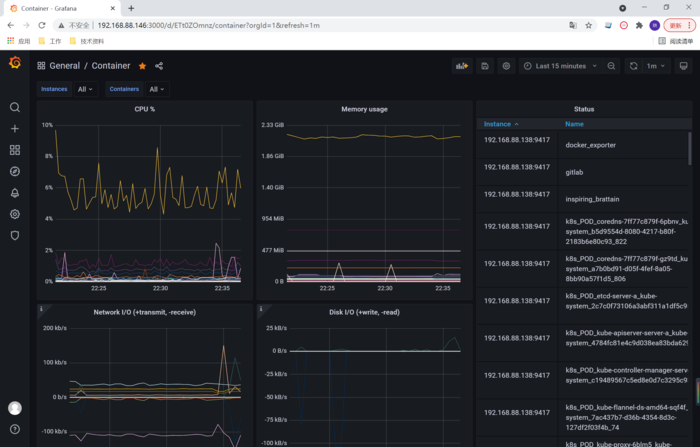
使用docker metrics 监控docker
开启metrics
vim /etc/docker/daemon.json
{ "metrics-addr" : "192.168.88.146:9323", "experimental" : true }
重启docker
systemctl daemon-reload
service docker restart
配置Prometheus
- job_name: "docker" static_configs: - targets: ["192.168.88.138:9323", "192.168.88.146:9323", "192.168.88.146:9323"]
导入模板https://grafana.com/grafana/dashboards/1229
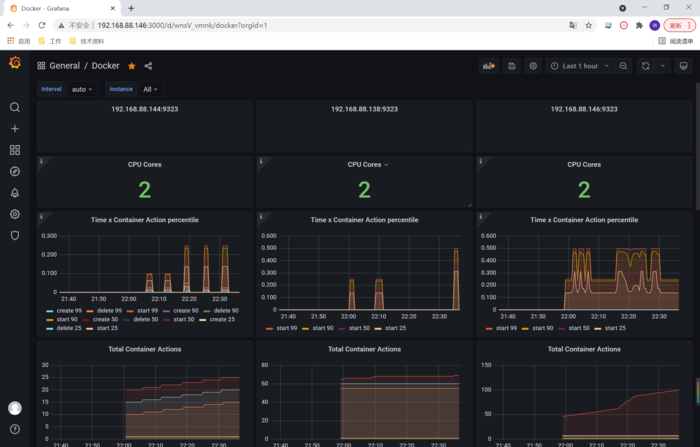
SkyWalking实现跟踪
架构简析

核心组件
Skywalking OAP Server
Skywalking收集器,接受写入请求与UI数据查询。
Skywalking UI
有调用链路记录、网络拓扑图、性能指标展示等。
Skywalking客户端代理
提供了多种语言的SDK(Java, .NET Core, NodeJS, PHP, Python等),在应用程序进行网络请求的时候进行埋点拦截,整理成需要的指标发送到Skywalking OAP Server,
安装SkyWalking的收集器
docker run --name skywalking-oap-server -p 12800:12800 -p 11800:11800 -p 1234:1234 --restart always -d -e SW_STORAGE=elasticsearch7 -e SW_STORAGE_ES_CLUSTER_NODES=192.168.184.129:9200 apache/skywalking-oap-server:8.4.0-es7
启动成功后去ES查看,多了很多的Index
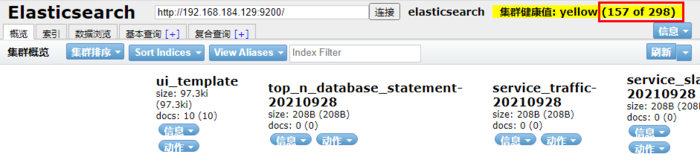
安装SkyWalking UI
docker run --name skywalking-ui -p 8888:8080 --restart always -d -e SW_OAP_ADDRESS=192.168.184.129:12800 apache/skywalking-ui:8.4.0
使用时注意调整右下角的时区
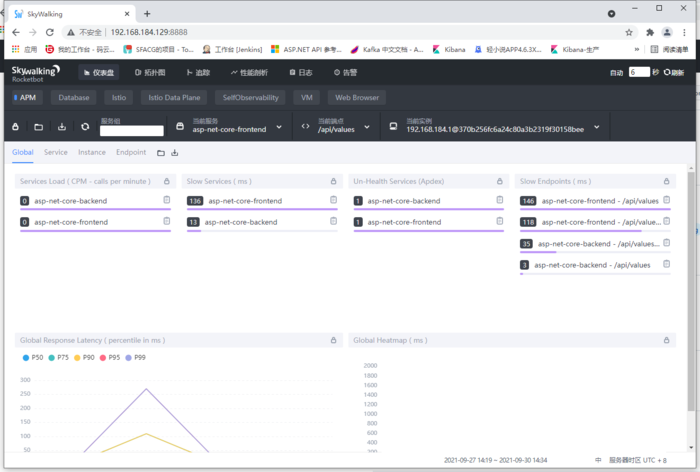
我们到Github下载源码 https://github.com/SkyAPM/SkyAPM-dotnet,根据how-to-build文档进行编译
- Prepare git and .NET Core SDK. - `git clone https://github.com/SkyAPM/SkyAPM-dotnet.git` - `cd SkyAPM-dotnet/` - Switch to the tag by using `git checkout [tagname]` (Optional, switch if want to build a release from source codes) - `git submodule init` - `git submodule update` - Run `dotnet restore` - Run `dotnet build src/SkyApm.Transport.Grpc.Protocol` - Run `dotnet build skyapm-dotnet.sln`
启动SkyApm.Sample.Frontend与SkyApm.Sample.Backend两个项目,浏览器访问http://localhost:5001/api/values/postin ,就可以见到下面的调用链了。
我在19年的时候使用0.9版本,http.request_body和http.response_body都是没记录需要自己扩展,而现在最新版已经有记录,省了不少的事。
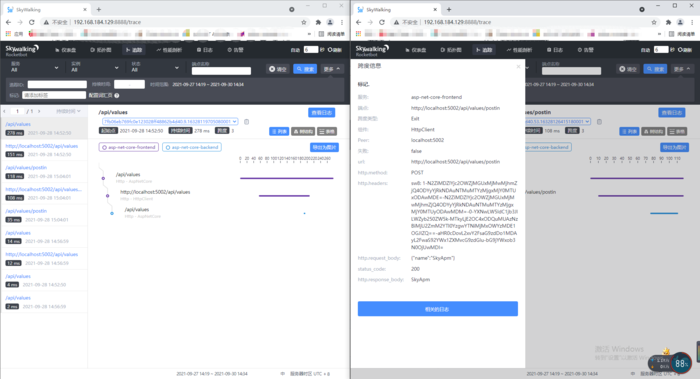
EFK(ElasticSearch+Filebeat+Kibana)实现日志
安装Nginx
主要用来测试的
rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
安装
yum install -y nginx
vim /etc/nginx/nginx.conf
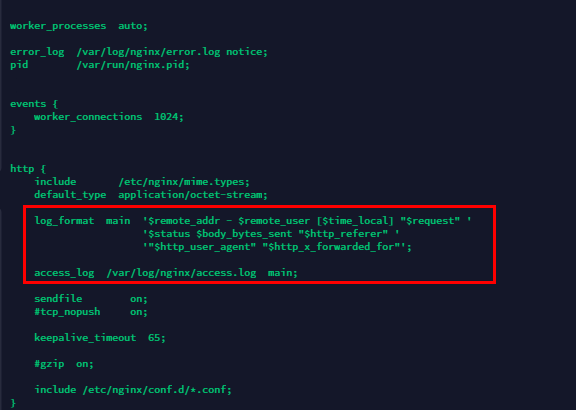
把圈起来的配置改动一下
log_format json \'{"@timestamp":"$time_iso8601",\' \'"host": "$server_addr",\' \'"clientip": "$remote_addr",\' \'"request_body": "$request_body",\' \'"responsetime": $request_time,\' \'"upstreamtime": "$upstream_response_time",\' \'"upstreamhost": "$upstream_addr",\' \'"http_host": "$host",\' \'"url": "$uri",\' \'"referer": "$http_referer",\' \'"agent": "$http_user_agent",\' \'"status": "$status"}\';
access_log /var/log/nginx/access.log json;
systemctl start nginx.service
systemctl enable nginx.service
用浏览器访问,刷新几次,执行cat /var/log/nginx/access.log 就可以看到json格式的日志了
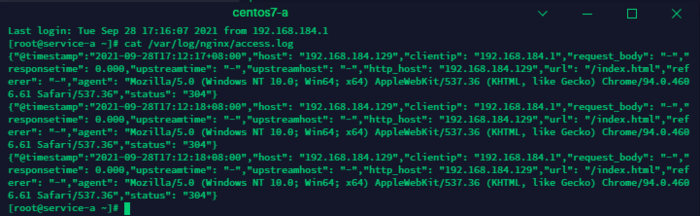
安装Filebeat
导入安装源
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
vim /etc/yum.repos.d/elastic.repo
保存下面文案
[elastic-7.x] name=Elastic repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
执行安装指令
yum install -y filebeat
添加配置
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
json.key_under_root: true
json.overwrite_keys: true
json.message_key: log
tags: ["nginx-access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
json.key_under_root: true
json.overwrite_keys: true
json.message_key: log
tags: ["nginx-error"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.ilm.enabled: false
setup.template:
name: "nginx"
pattern: "nginx-*"
setup.template.overwrite: true
setup.template.enabled: false
output.elasticsearch:
hosts: ["192.168.184.129:9200"]
indices:
- index: "nginx-access-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-access"
- index: "nginx-error-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-error"
启动
systemctl start filebeat
systemctl enable filebeat
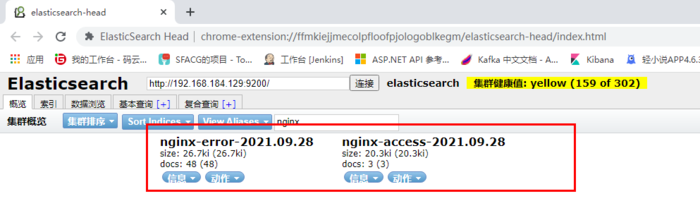
安装kibana
docker run --name kibana -d -p 5601:5601 kibana:7.7.0
mkdir /var/kibana
docker cp kibana:/usr/share/kibana/config /var/kibana/config
删除之前的容器再安装一次
docker run --name kibana -d -v /var/kibana/config:/usr/share/kibana/config -p 5601:5601 kibana:7.7.0
修改配置后,重启容器
vim /var/kibana/config/kibana.yml
打开浏览器访问
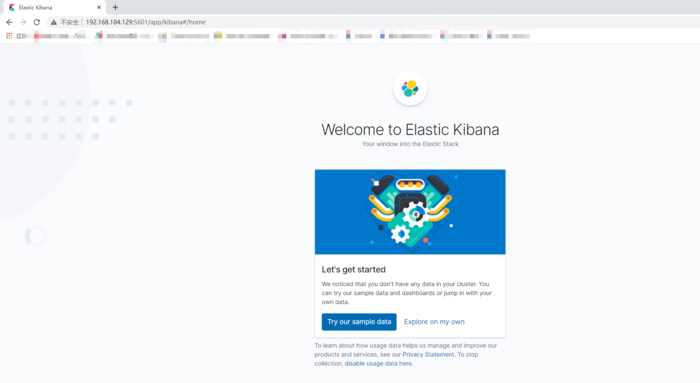
创建索引,填写nginx-access-*
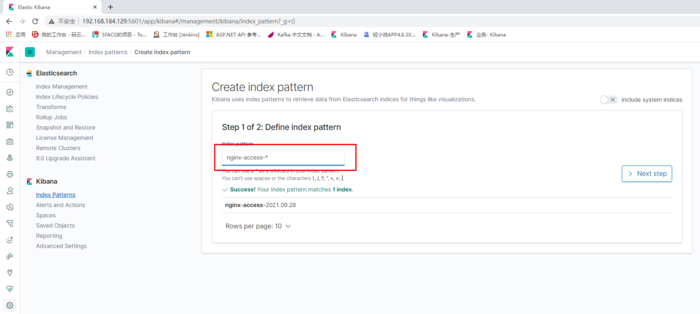
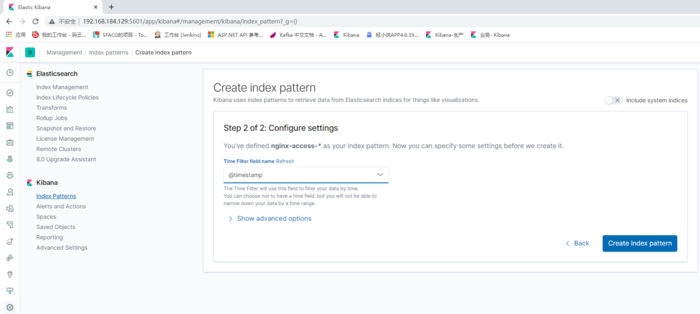
最后的展示UI
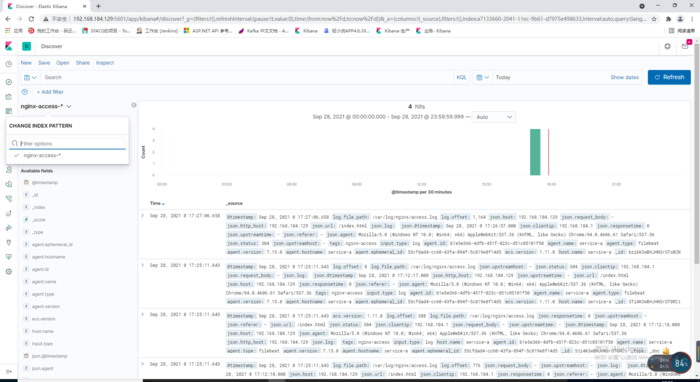
.Net的日志同样可以使用Json保存,然后通过Filebeat进行采集。
结束
本篇文章是我之前实现微服务的时的运维的技术栈,如果有什么问题与建议,可以给在评论区反馈给我。









 京公网安备 11010802041100号
京公网安备 11010802041100号