Maven 翻译为”专家”、”内行”,是 Apache 下的一个纯 Java 开发的开源项目。基于项目对象模型(Project Object Model 缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。
在开发一些大型项目的时候,需要用到各种各样的开源包jar,为了方便管理及加载jar,使用maven开发项目可以节省大量时间且方便项目移动至新的开发环境。
开发环境
Maven安装
我使用的这个版本的Eclipse已经自带了Maven插件,不需要在自行安装,因此我也没有实际操作,本文就不介绍如何配置。
至于怎么知道自己使用的Eclipse是否自带有Maven,可以在Eclipse->Preference->Maven->Installations查看是否有Maven及版本号。或者直接新建项目查看是否有Maven选项。
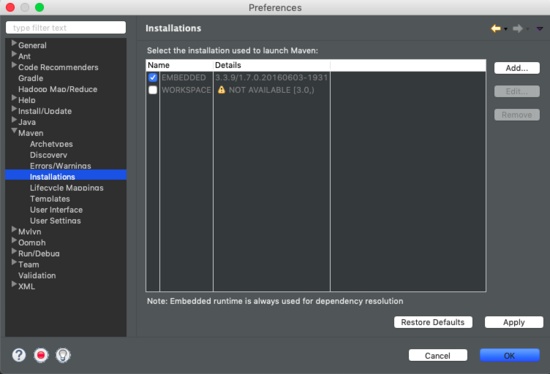
构建Hadoop环境
创建Maven项目
打开Eclipse,File->new->project,选择Maven,然后下一步next
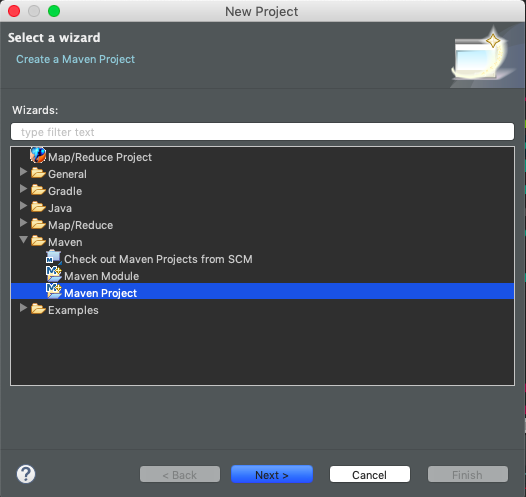
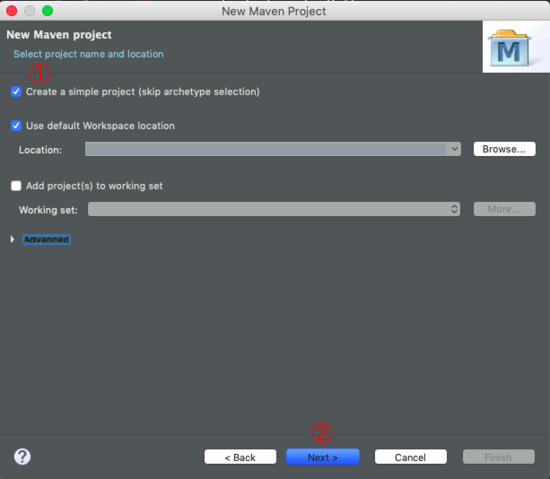
选择Creat a simple project,然后下一步next
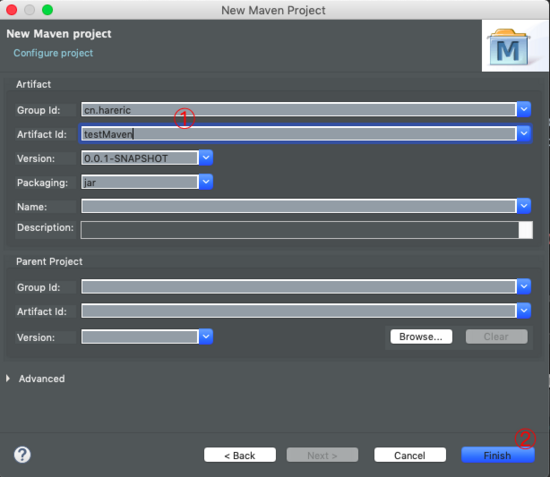
输入Group id和artifact id。然后finish。
groupid和artifactId被统称为“坐标”是为了保证项目唯一性而提出的,如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。
groupId一般分为多个段,这里我只说两段,第一段为域,第二段为公司名称。域又分为org、com、cn等等许多,其中org为非营利组织,com为商业组织。举个apache公司的tomcat项目例子:这个项目的groupId是org.apache,它的域是org(因为tomcat是非营利项目),公司名称是apache,artigactId是tomcat。
比如我创建一个项目,我一般会将groupId设置为cn.snowin,cn表示域为中国,snowin是我个人姓名缩写,artifactId设置为testProj,表示你这个项目的名称是testProj,依照这个设置,你的包结构最后是cn.snowin.testProj打头。(引自 链接 )
完成上述步骤后,就可以在Project Explorer中看到刚刚创建的Maven项目。

增加Hadoop依赖
我使用的Hadoop 2.7版本,以下是我的POM配置文件
4.0.0 practice.hadoop simple-examples 0.0.1-SNAPSHOT jar simple-examples http://maven.apache.org UTF-8 junit junit 4.12 test org.apache.hadoop hadoop-common 2.7.0 org.apache.hadoop hadoop-hdfs 2.7.0 org.apache.hadoop hadoop-client 2.7.0 org.apache.mrunit mrunit 1.1.0 hadoop2 test org.apache.hadoop hadoop-mapreduce-client-core 2.7.0 org.apache.hadoop hadoop-yarn-api 2.7.0 org.apache.hadoop hadoop-auth 2.7.0 org.apache.hadoop hadoop-minicluster 2.7.0 test org.apache.hadoop hadoop-mapreduce-client-jobclient 2.7.0 provided
在Project Explorer中右键该项目,选择build project,Maven就会根据POM.xml配置文件下载所需要的jar包。
稍等一段时间后,就可以看到Maven Dependencies中已经下载好的jar包。
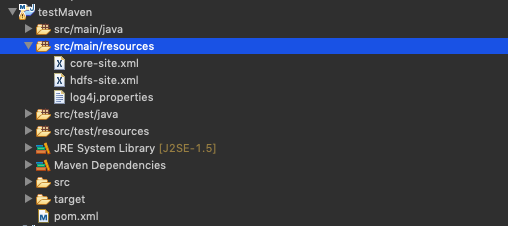
hadoop配置文件
运行 MapReduce 程序前,务必将 /usr/local/Cellar/hadoop/2.7.0/libexec/etc/hadoop 中将有修改过的配置文件(如伪分布式需要core-site.xml 和 hdfs-site.xml),以及log4j.properties复制到 src/main/resources/
MapReduce实例—WordCount
在 src/main/java/ 路径下,创建java文件,代码如下
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper {
/**
* LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java
* 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品。
*/
private final static IntWritable One= new IntWritable(1); // 值为1
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); // 对字符串进行切分
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration cOnf= new Configuration();
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String[] otherArgs = {"/input", "/output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputDirRecursive(job, true);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有