作者:她丶无可取代 | 来源:互联网 | 2023-07-19 14:04
一、背景
Apache Flink 作为新一代的实时计算框架已经被应用到各个行业与领域,虽说应用程度不同,但都会遇到一些使用上的痛点,基础的应用痛点比如 FlinkSQL 作业提交不友好、作业无监控报警等。很大程度上说,FlinkSQL 大大加快了 Flink 的应用推广,而本文将简述开源项目 Dinky 如何改善 Flink 的痛点来优化 FlinkSQL 应用体验。
https://github.com/DataLinkDC/dlink
https://gitee.com/DataLinkDC/Dinky
二、简介
一个 开箱即用 、易扩展 ,以 Apache Flink 为基础,连接 OLAP 和 数据湖 等众多框架的 一站式 实时计算平台,致力于 流批一体 和 湖仓一体 的建设与实践。
其主要目标如下:
-
可视化交互式 FlinkSQL 和 SQL 的数据开发平台:自动提示补全、语法高亮、调试执行、语法校验、语句美化、全局变量等
-
支持全面的多版本的 FlinkSQL 作业提交方式:Local、Standalone、Yarn Session、Yarn Per-Job、Yarn Application、Kubernetes Session、Kubernetes Application
-
支持 Apache Flink 所有的 Connector、UDF、CDC等
-
支持 FlinkSQL 语法增强:兼容 Apache Flink SQL、表值聚合函数、全局变量、CDC多源合并、执行环境、语句合并、共享会话等
-
支持易扩展的 SQL 作业提交方式:ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、SqlServer 等
-
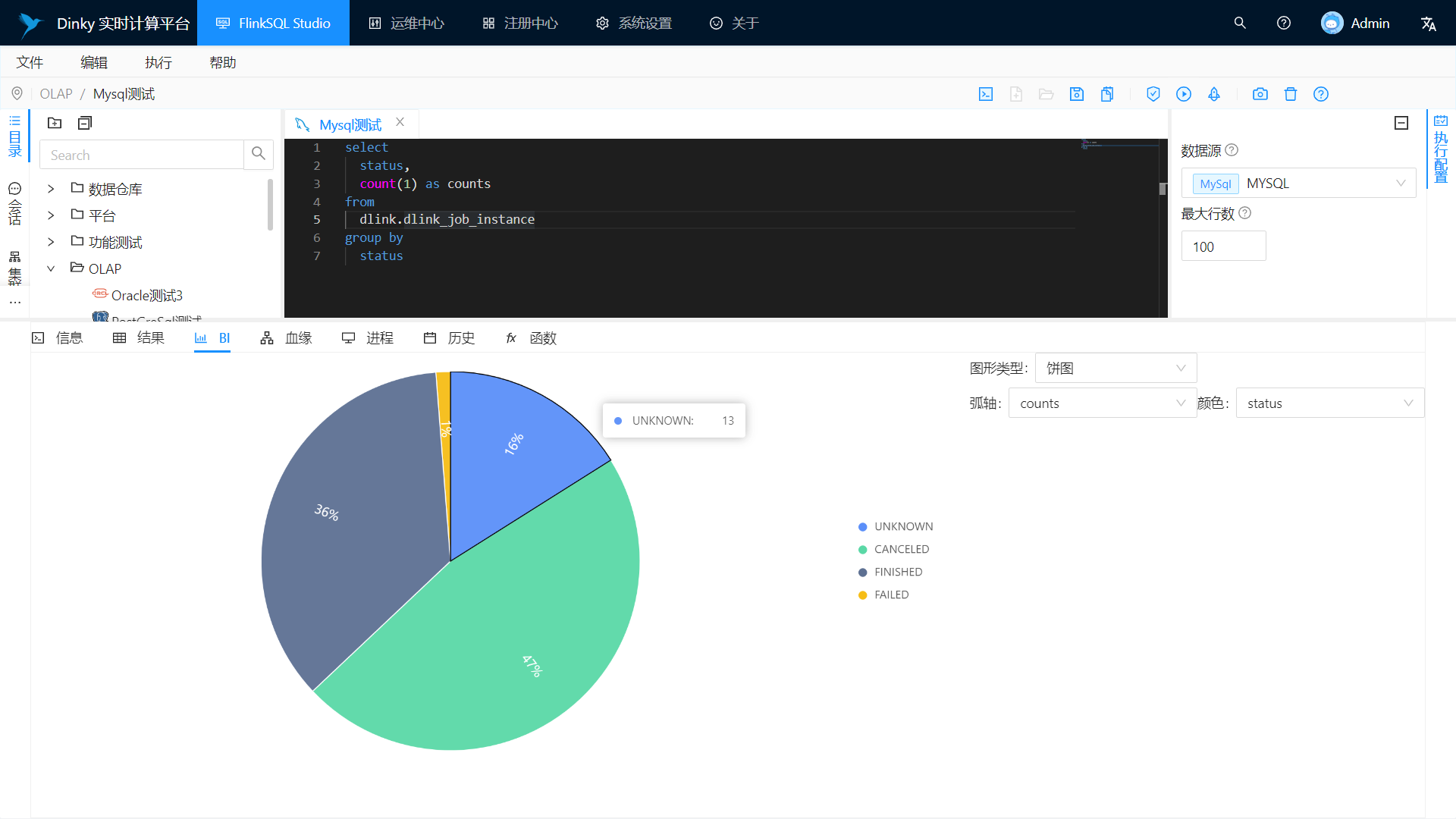
支持实时调试预览 Table 和 ChangeLog 数据及图形展示
-
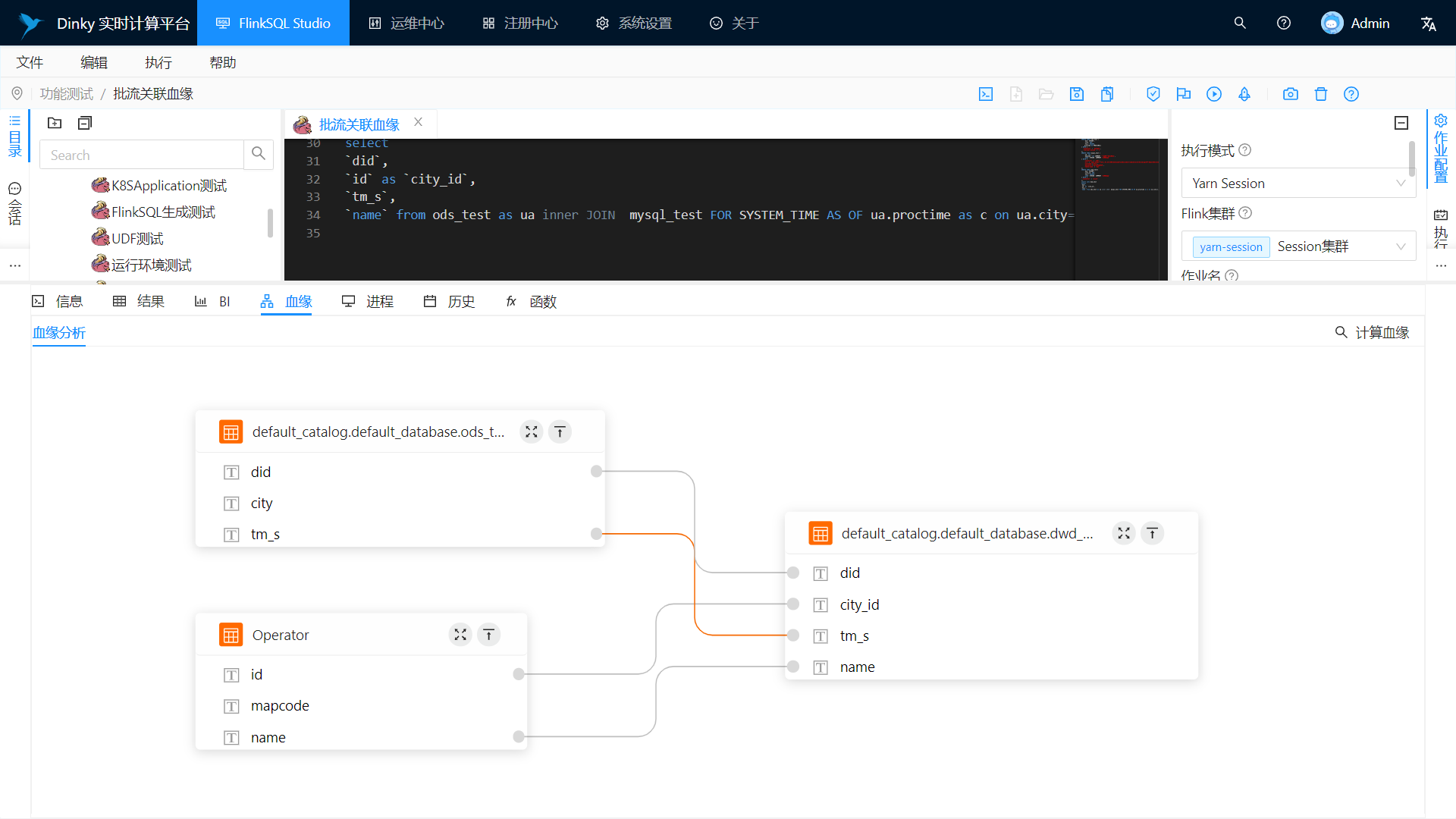
支持语法逻辑检查、作业执行计划、字段级血缘分析等
-
支持 Flink 元数据、数据源元数据查询及管理
-
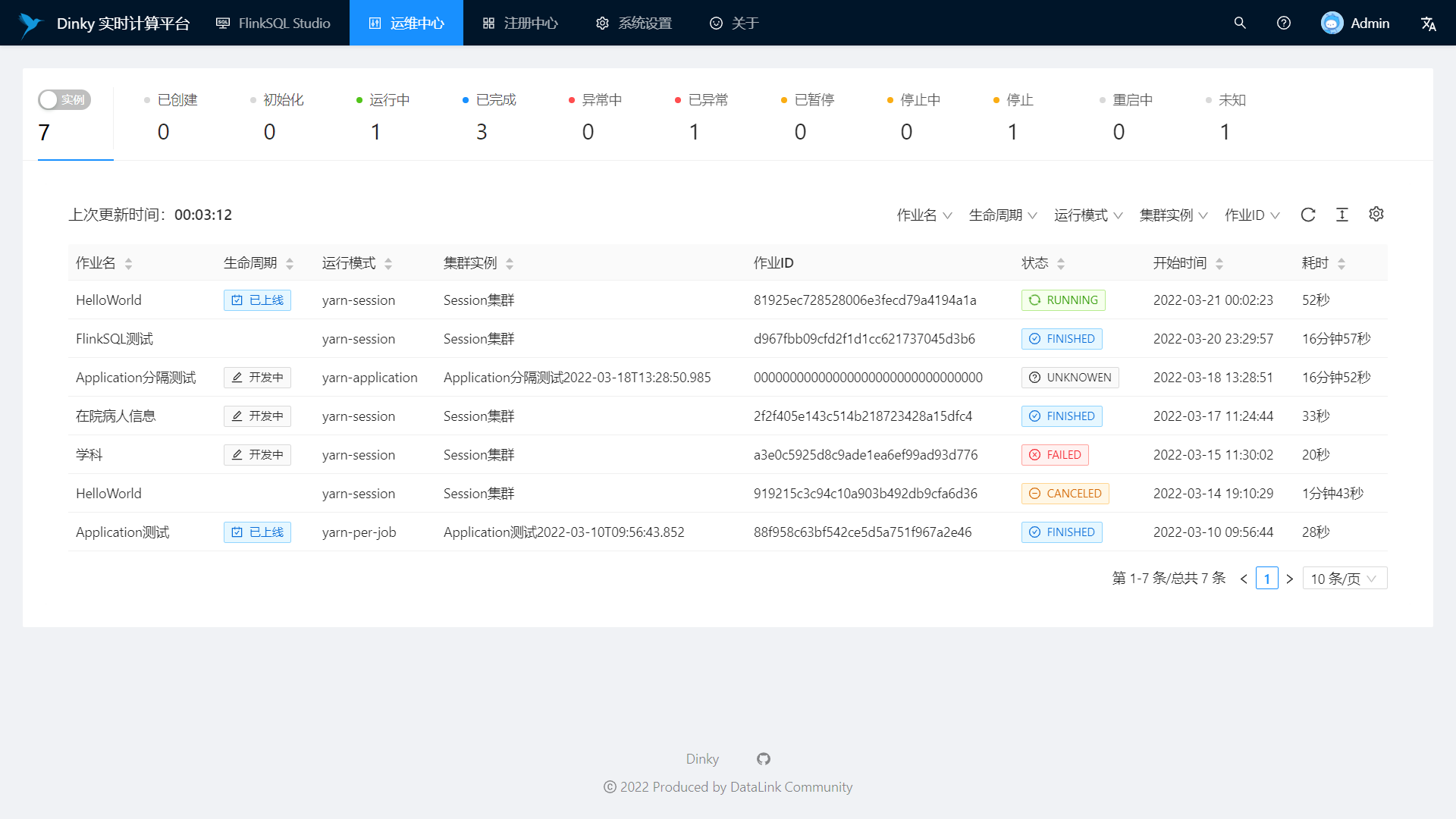
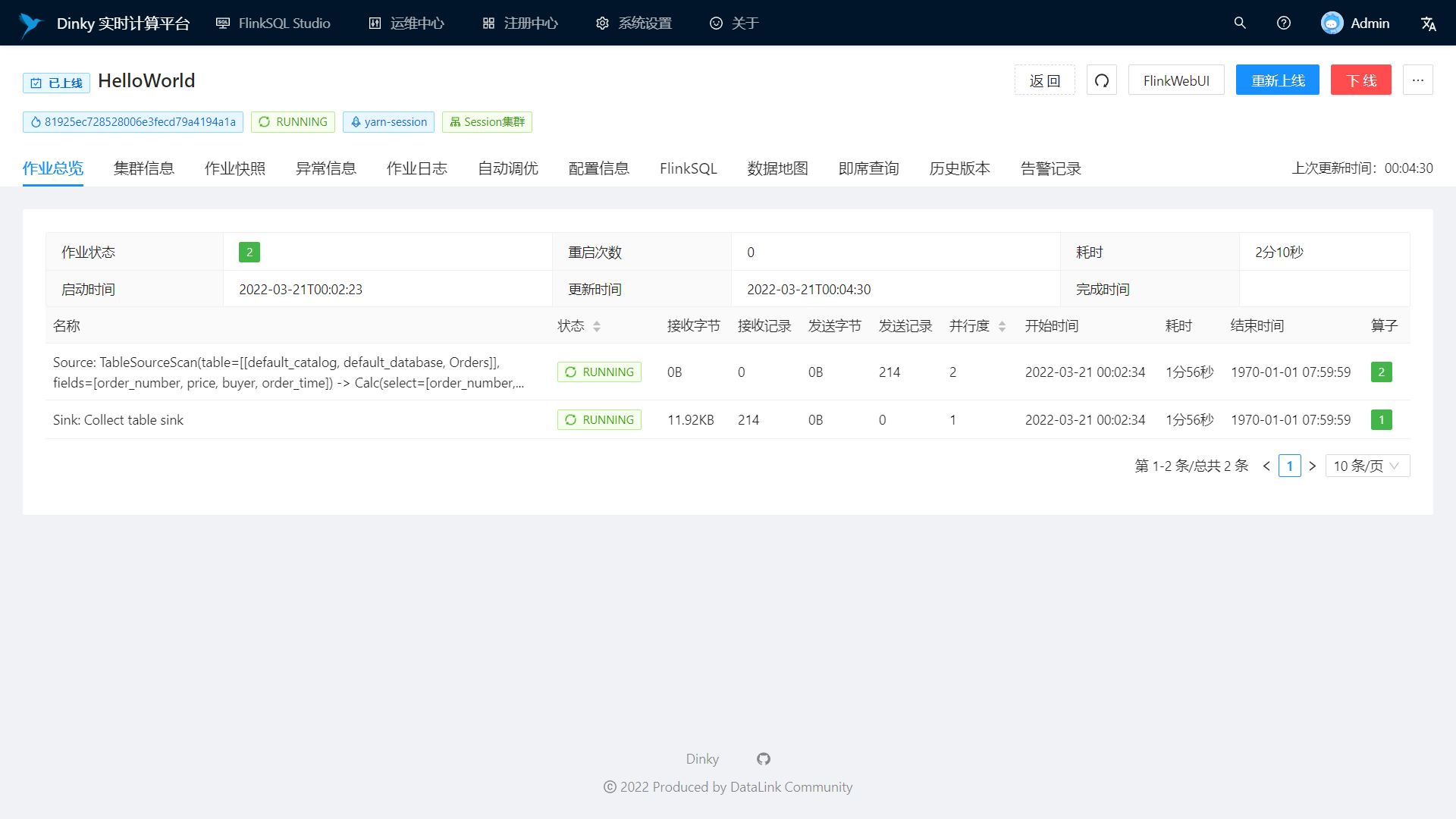
支持实时任务运维:作业上线下线、作业信息、集群信息、作业快照、异常信息、作业日志、数据地图、即席查询、历史版本、报警记录等
-
支持作为多版本 FlinkSQL Server 的能力以及 OpenApi
-
支持易扩展的实时作业报警及报警组:钉钉、微信企业号等
-
支持完全托管的 SavePoint 启动机制:最近一次、最早一次、指定一次等
-
支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、用户、系统配置等
-
更多隐藏功能等待小伙伴们探索
三、原理
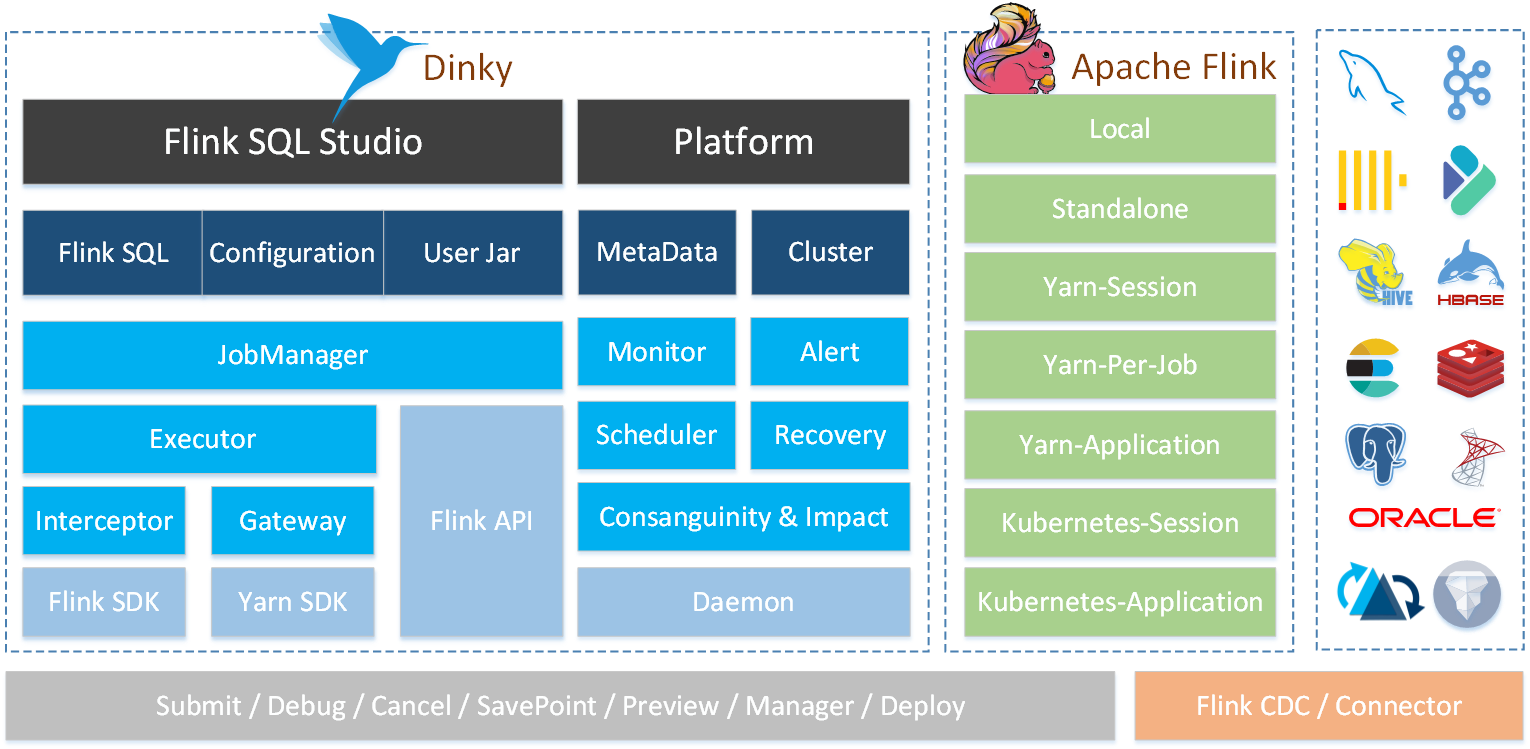
四、精彩瞬间
FlinkSQL Studio
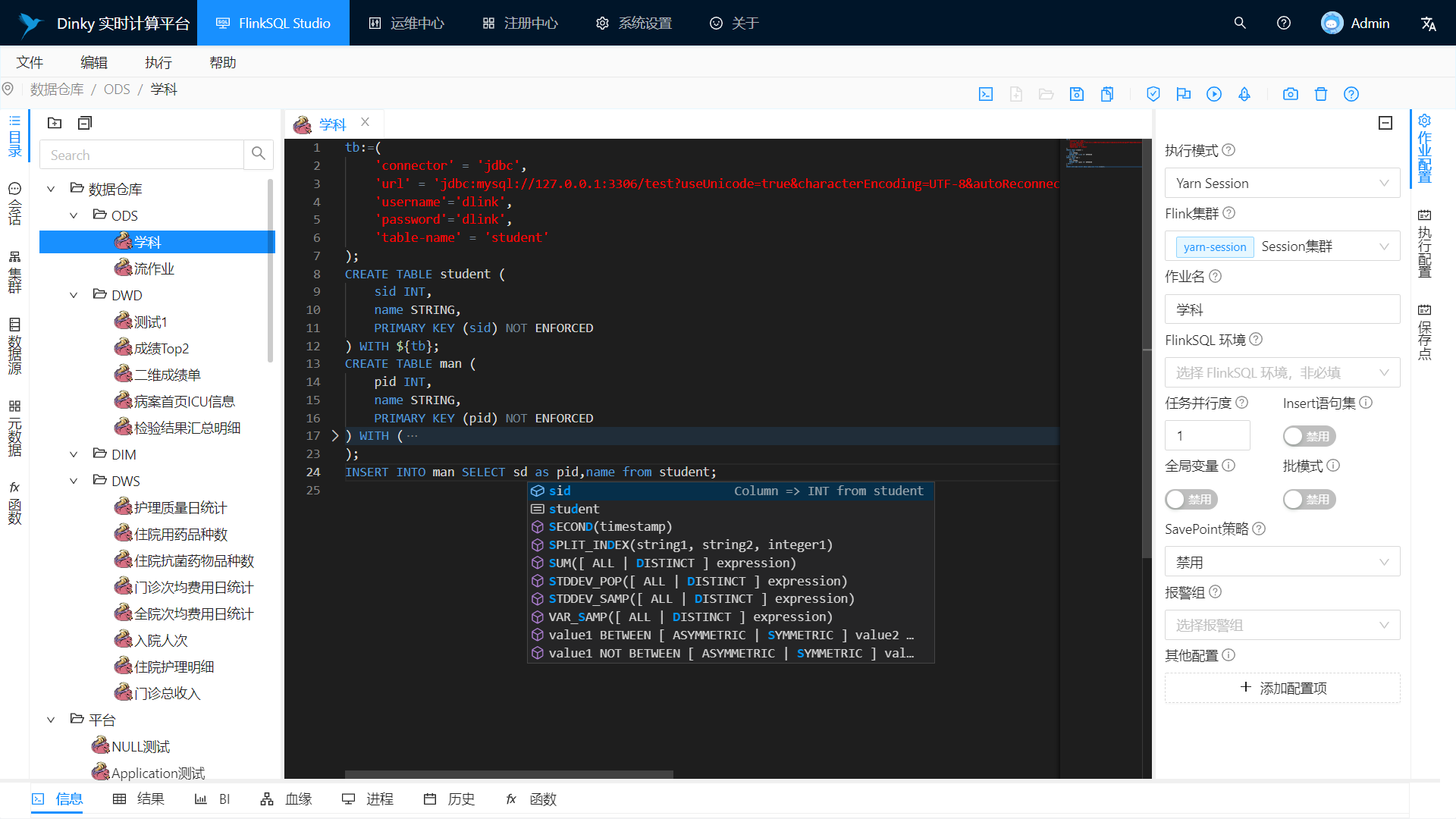
实时调试预览
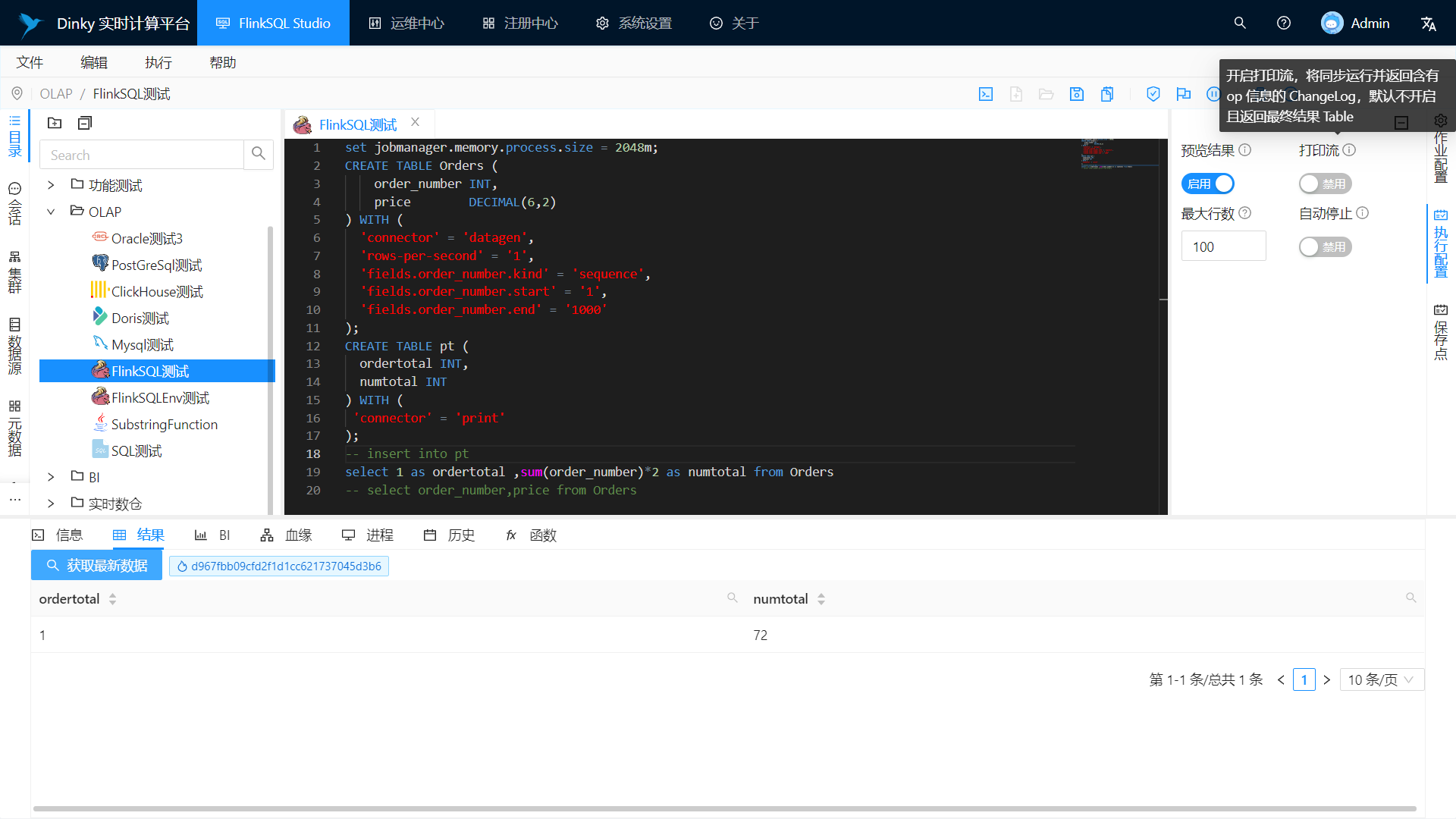
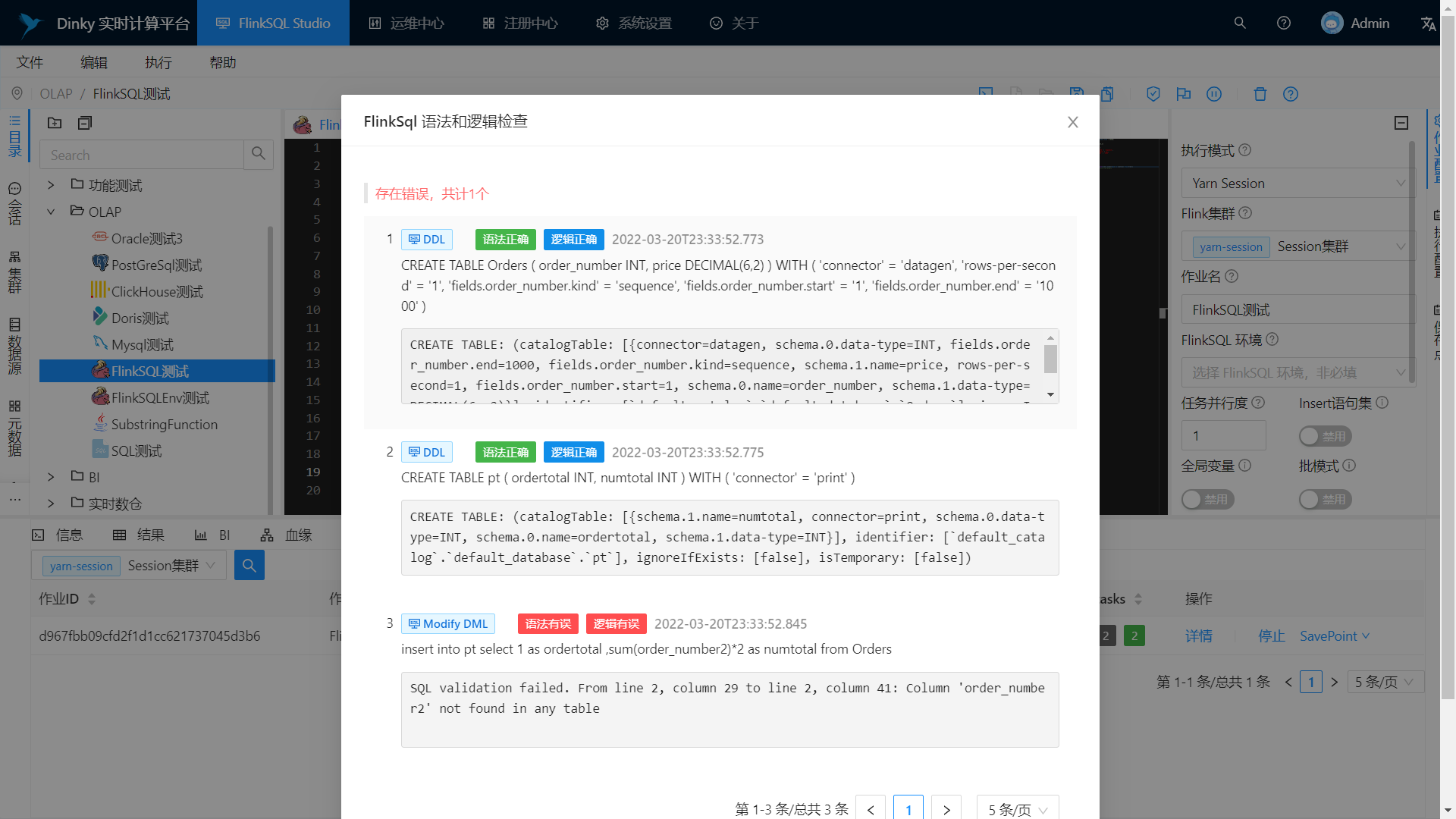
语法和逻辑检查
字段级血缘
BI展示
元数据查询

实时任务监控
实时作业信息
数据源注册

五、优化 Flink 体验
沉浸式的 FlinkSQL IDE
Apache Flink 提供了 sql-client,但 sql-client 仅作为一个 beta 的功能,难以被应用到生产中。
Dinky 提供了沉浸式的 FlinkSQL IDE 开发能力,提供了自动提示与补全、语法高亮、语句美化、语法校验和逻辑检查、调试预览结果、字段级血缘分析等专业的功能,使 FlinkSQL 的开发如同 SQL 开发一样舒适与简单。
易用的任务构建方式
Flink 在构建 FlinkSQL Jar 任务时通常需要考虑依赖及版本的维护、代码的编写、繁琐的编译打包过程等。
Dinky 将 FlinkSQL 任务的构建进行了极简,开发人员只需要专注 FlinkSQL 的口径书写,并且可以实时进行检查与调试,在任务提交的过程则是快速的自动化托管,以实现一个 FlinkSQL 语句可以在所有的执行模式与外部集群上随意切换。
对于 Dinky 来说,主要划分两类用户。一类是平台运维人员,该人员需要根据官网文档及自身的 Flink 知识储备来手动搭建稳定的 Dinky 运作环境,门槛较高;另一类是数据开发人员,该类人员只需熟悉 FlinkSQL 的语法与常见的应用场景,即可快速高效地进行 FlinkSQL 的开发与运维,达到易用的任务构建方式。这也是最符合企业生产团队的分工策略,平台和开发分离。
无侵入的部署模式
一些开源项目或自建平台通常需要绑死 Flink 集群或者侵入 Flink 的源码,容易 Flink 功能受限或在搭建和后续扩展时出现问题。
Dinky 则是完全无侵入,可部署与各个集群之外,同时连接和监控多个集群。轻易地对接各个版本的 Flink 集群与公司内仓库分支优化过的 Flink 集群,完全兼容 Flink 自身的 connector、udf、cdc 等。
增强式的功能体验
一些开源项目及自建平台一般只专注于 Flink 任务的提交与运维。
Dinky 则不同,为更舒适地使用 Flink 的相关功能进行的功能增强,如表值聚合函数、全局变量、CDC多源合并、执行环境、语句合并、共享会话等,并且还在不断地扩展新的功能增强,以使 Flink 更贴近企业的需求。
实时的监控报警
Dinky 提供实时的监控报警能力,实时守护已上线的流或批任务,在任务触发异常停止和成功完成时都会实时报警通知,并且记录了外部集群实时的任务信息,摆脱 History Server 的限制,弥补 deploy 的集群作业失败后信息难查询的不足,用户随时随地都可追溯历史作业的执行信息与异常。
一站式的开发运维
Dinky 提供了一站式的开发运维能力,从 FlinkSQL 开发调试到作业上线下线的运维监控,再到数据源的 OLAP 及普通查询能力等,使得数仓建设或数据治理过程中所有的工作均可以在 Dinky 上完成。
易扩展的代码实现
Dinky 非常注重代码的扩展能力,在源码中大量使用了 SPI 机制来支持用户低成本地自定义扩展新功能,比如数据源、报警方式、自定义语法等扩展。
Dinky 的功能体验也十分注重扩展能力,在功能设计上尽可能地开放了最大的配置能力,如自定义提示与补全语法、自定义数据源的Flink 配置与生成规则、自定义全局变量、自定义Flink执行环境、自定义集群配置的各种配置项等等。
Dinky 的外部对接也很注重扩展能力,基于 SpringBoot 的代码的高内聚和低耦合设计以及提供多种规范的 OpenAPI 使其可以很方便地扩展第三方生态、微服务或者平台,例如海豚调度等。
小而美的产品形态
常规的大数据平台或者开源项目一般是十分庞大的,维护成本较高。
正如 Dinky 本名所释,小巧而精美,一直是开源项目建设的首要目标。小巧具体指易搭建、不绑定任何外部中间件或文件系统、代码简洁易维护;精美则指沉浸式的页面、经过打磨的各种功能等。
六、近期计划
多租户及命名空间
Dinky 目前需要一个多租户的能力来分离业务数据及资源队列,需要命名空间来增强和约束业务权限的实现与扩展。
全局血缘与影响分析
Dinky 目前需要将所有的字段级血缘进行存储,以构建全局的血缘和影响分析,方便用户更容易地追溯数据问题。
统一元数据管理
Dinky 目前需要统一的元数据中心来管理外部数据源元数据,使其可以自动同步数据库物理模型与平台逻辑模型之间的结构,增强平台一站式的开发能力。
Flink 元数据持久化
Dinky 目前需要持久化 Flink Catalog,使作业开发时不再需要编写 CREATE TABLE 等语句,转变为可视化的元数据管理功能。
多版本 Flink-Client Server
Dinky 目前的 Flink 多版本支持需要启动多个不同版本的实例来支持。未来需要实现客户端与服务端分离,单独实现多版本的 Server。
整库同步
数据库的整库同步是一个常见的场景,Dinky 未来将提供一个简短的 FlinkSQL 实现整库同步任务构建的能力。
七、感谢
站在巨人的肩膀上,Dinky 才得以诞生。对此我们对使用的所有开源软件及其社区表示衷心的感谢!我们也希望自己不仅是开源的受益者,也能成为开源的贡献者,也希望对开源有同样热情和信念的伙伴加入进来,一起为开源献出一份力!致谢列表如下:
Apache Flink
Apache Dolphinscheduler
Ant-Design-Pro
Mybatis Plus
Monaco Editor
SpringBoot








 京公网安备 11010802041100号
京公网安备 11010802041100号