作者:天生笑丷丶话 | 来源:互联网 | 2023-08-25 13:44
一、爬虫简介日常需求:1)抢火车票2)在某个商城里买到质量,口碑,性价比好的商品3)考试或面试的时候,想看一些针对性的面试题4)批量下载图片、mp3、电影保存到本地5)在某个商城里
一、爬虫简介
日常需求:
1)抢火车票
2)在某个商城里买到质量,口碑,性价比好的商品
3)考试或面试的时候,想看一些针对性的面试题
4)批量下载图片、mp3、电影保存到本地
5)在某个商城里买到质量,口碑,性价比好的商品
6)找工作的时候,看看哪个地区某个工作岗位的招聘数量比较多
什么是爬虫?
通过编写程序,模拟浏览器上网,让其去互联网上抓取数据的过程。
网络爬虫(也叫作网页蜘蛛,网络机器人),就是模拟客户端主要是浏览器发送请求,接收请求响应,按照一定的规则,自动抓取互联网信息的程序。
原则上: 只要客户端浏览器你鞥做的事情,爬虫都能够做,但是一般只能获取浏览器展示的数据。
爬虫的作用
1)数据采集:
① 抓取微博评论(机器学习舆情监控)
② 抓取招聘网站的招聘信息(数据分析、挖掘)
③ 抓取新闻,例如百度新闻
④ 抓取房产信息
2)软件测试
① selenium爬虫自动化测试
3) 投票,短信轰炸

1.爬虫的价值?
我们现在是大数据的时代,可以通过爬虫去互联网上抓取大量的数据,然后通过大数据相关技术进行统计和分析。
求职网站搜索:爬虫,有爬虫工程师相关职位
2.爬虫究竟是合法还是违法的?
从入门到入狱,从同学到狱友,师傅领进门,判刑看个人
1)在法律中是不被禁止的,具有违法风险,例如菜刀
2)善意爬虫,恶意爬虫,抢票爬虫,每秒向12306发送几万次请求
爬虫的风险可以体现在:
1)爬虫干扰了被访问网站的正常运营
2)爬虫抓取了受到法律保护的特性类型的数据或信息
!!!编写爬虫注意事项
1)不爬用户的私人信息
2)不要过度爬取某个网站的内容:把别人网站搞宕机
时常优化自己的程序,避免干扰被访问网站的正常运行
3) 爬取的内容不要损害别人的商业利益,遵守Robots协议(尽量遵守)
robots.txt协议:君子协议,明确规定网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取,全靠自觉。
4)在使用传播爬取到的数据时,需要审查抓取到的内容,如果发现了涉及到用户隐私或者商业机密等敏感内容,就需要及时停止爬取或传播
爬虫在使用场景中的分类
1) 通用爬虫
抓取系统的重要组成部分。抓取的是互联网中一整张页面数据。例如百度,谷歌,搜狗等搜索引擎
2) 聚焦爬虫
建立在通用爬虫的基础之上,抓取的是页面中特定的局部内容。定向抓取网页资源。
3) 增量式爬虫
监测网站中数据更新的情况,只会抓取网站中最新更新的数据
4) 深层网络爬虫
大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。 例如用户登录或者注册才能访问的页面。
爬虫的名词反爬机制:
门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:
爬虫程序可以通过制定相关的策略和技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
二、爬虫的结构
通用的爬虫结构:
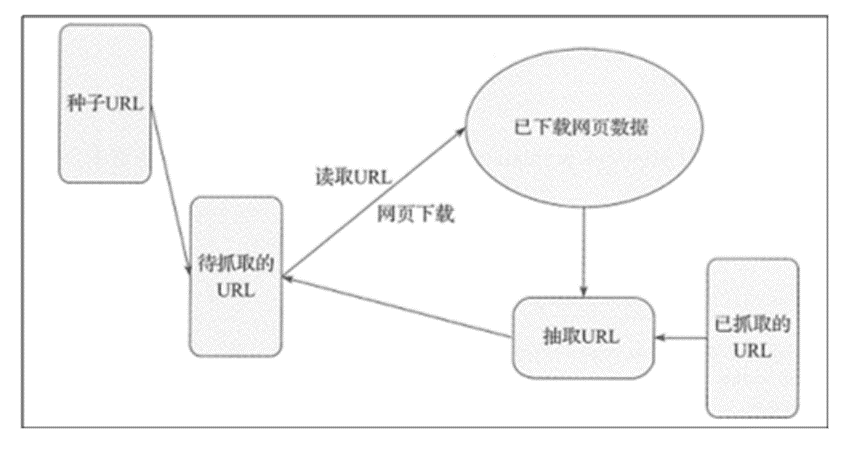
爬虫的工作原理其实和使用浏览器访问网页的工作原理是完全一样的,都是根据HTTP来获取网页的内容。爬虫的工作流程:
1) 首先选取一部分种子 URL。
URL : 统一资源定位符(URL,英语Uniform Resource Locator的缩写)也被称为网页地址,是因特网上标准的资源的地址。
URL的样子:
https://www.galayun.com/home/course?typeId=1
URL的组成部分
协议部分: https://、http://、ftp://
域名部分: www.galayun.com
域名:域名就是IP地址的别名,它是用点进行分割使用英文字母和数字组成的名字,使用域名目的就是方便的记住某台主机IP地址。
资源路径部分: /home/coursel
URL的扩展:
https://www.galayun.com/home/course?typeId=1
查询参数部分: ?typeId=1
参数说明:? 后面的typeId 表示参数,如果有多个参数使用 & 进行连接
2) 然后将这些 URL 放入待抓取 URL 队列。
3) 从待抓取 URL 队列中读取待抓取队列的 URL,解析 DNS, 并且得到主机的 IP, 并将 URL 对应的网页 下载下来,存储进已下载网页库中。此外将这些 URL 放进已抓取 URL 队列。
4) 分析已抓取 URL 队列中的 URL,从已下载的网页数据中分析出其他 URL, 并和已抓取的 URL 进行 比较去重,最后将去重过的 URL 放人待抓取 URL 队列,从而进人下一个循环。 这是一个基础网络爬虫结构及其工作流程,在之后的章节会使用 Python 实现这种网络爬虫结构。









 京公网安备 11010802041100号
京公网安备 11010802041100号