▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
摘要:第三届 Apache Flink 极客挑战赛正在火热进行中,Cluster Serving 是 Analytics Zoo/BigDL 的分布式推理解决方案,可以部署在 Apache Flink 集群上进行分布式运算。本文整理自英特尔机器学习工程师宋佳明在 Flink Forward Asia 2020 分享的议题《Cluster Serving:Distributed and Automated Model Inference on Big Data Streaming Frameworks》。内容包括:
Cluster Serving 概况
AI 产品化面临的挑战
可扩展的在线推理服务
使用案例
Flink 社区的一些集成
Tips:点击「阅读原文」即可回顾第三届极客挑战赛解读视频~
 GitHub 地址
GitHub 地址 
欢迎大家给 Flink 点赞送 star~

一、Cluster Serving 概况
Cluster Serving 是一个集成的深度学习分布式大数据框架的在线推理器,它的全称是 Analytics Zoo Cluster Serving,是 Intel 开发的一个开源项目,Cluster Serving 是其中的一个模块。
二、AI 产品化面临的挑战
下图中展示了关于机器学习和深度学习的性能表现和数据量,可以看到随着神经网络规模的扩大,它的模型表现性能越来越好。但是模型性能的上限和数据量是紧密相关的,也就是说需要很大的数据去支撑深度学习。

下图引用了 Google 一篇论文里的内容,在一个完整的深度学习的应用里,除了深度学习相关的代码,还包括一些其他相关部分,主要包含配置信息、数据的清理、数据预处理,还有监控等相关协调的部分。这些组件全部加起来才可以构成一个完整的深度学习的应用。也就是说,在完成深度学习的代码的同时,去完成一个完整的深度学习应用仍然面临比较大的挑战。
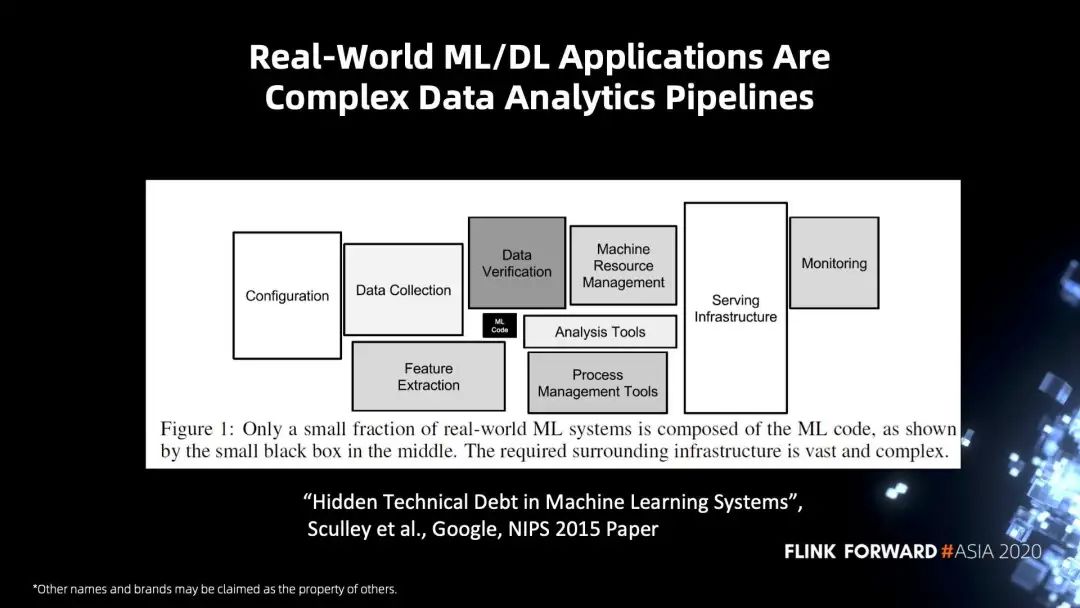
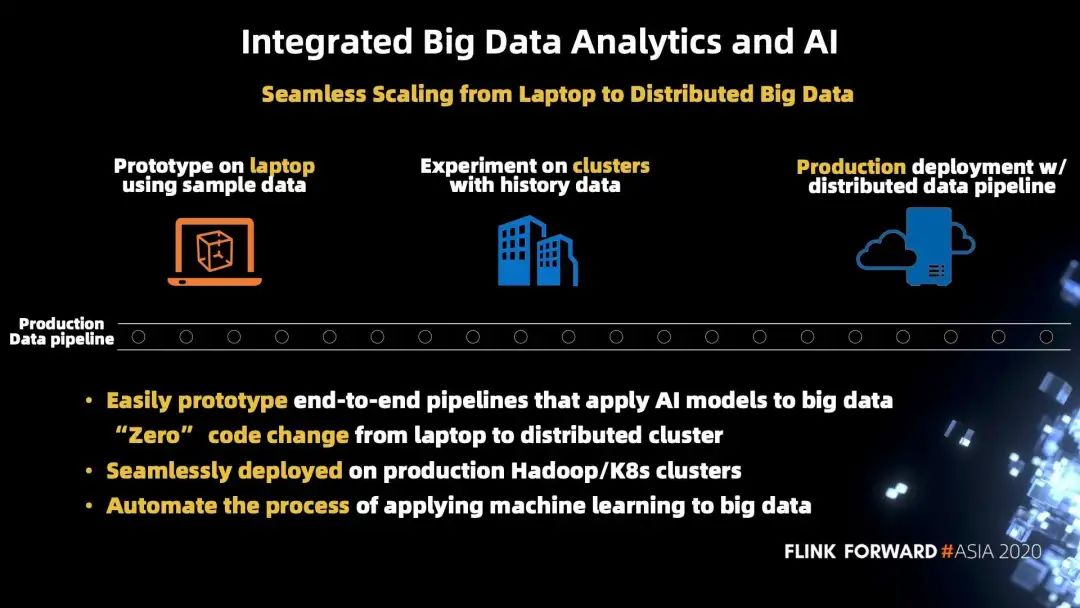
给出的解决方案是 Integrated Big Data Analytics and AI,通过一个集成的框架把深度学习应用的相关内容都组合起来。框架能够满足这四个特性:
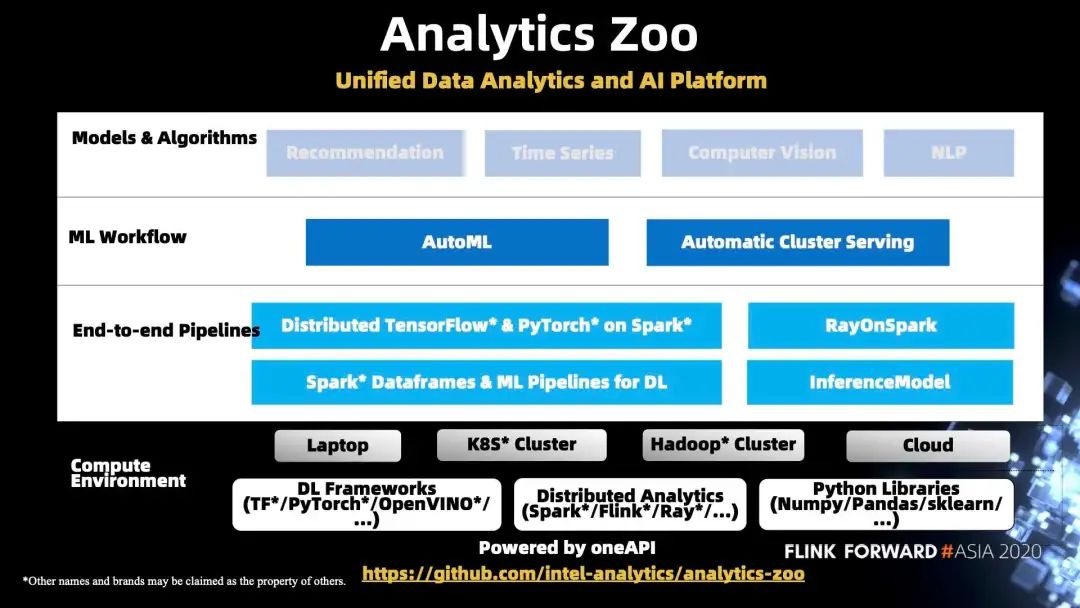
简单介绍一下 Analytic Zoo 架构:
三、可扩展的在线推理服务
这里通过一张 TensorFlow 的图来说明在线推理的大致流程。tf-serving 是 TensorFlow 在线推理的 Serving,大致流程就是数据输入,经过数据预处理,然后到已经训练好的模型,去做一个推理,之后再把结果返回回来。这是一条完整的 workflow,这里称之为 Serving。

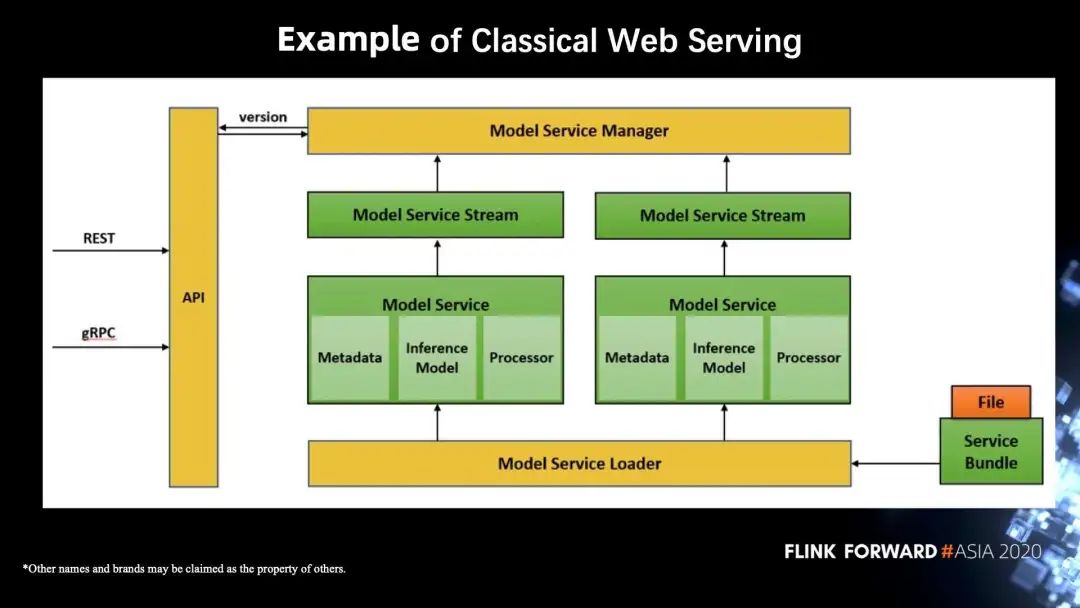
下图是一个简单的 web 推理服务的案例图,右下角是模型文件。系统会把模型文件储存起来,把相关信息保存到元数据里面,通过一个模型的管理组件管理元数据,然后用模型 service Loader 来加载模型。左边是一个 API,API 可以通过 http 或者 grpc 远程调用。它可以访问到 Model service Manager,得到正确的模型的对应版本,然后去完成 service 的过程。
上图和 tf-serving 都是一个单机版的推理服务。在大数据的情况下,能否把数据并行处理,把它部署到多节点的集群上,是目前 intel 实现的一个可扩展性分布式推荐服务架构图。

下图左边使用的是 Redis,把它作为一个输入和输出的数据管道数据库,右边为主要部分,是基于 Flink 实现的一个分布式的推理。Flink 的 source 会通过 Redis 拿到输入数据,然后通过 Analytics Zoo 里面的一个底层组件去进行推理。当推理结束后,会通过 data sink 写回到 Redis。
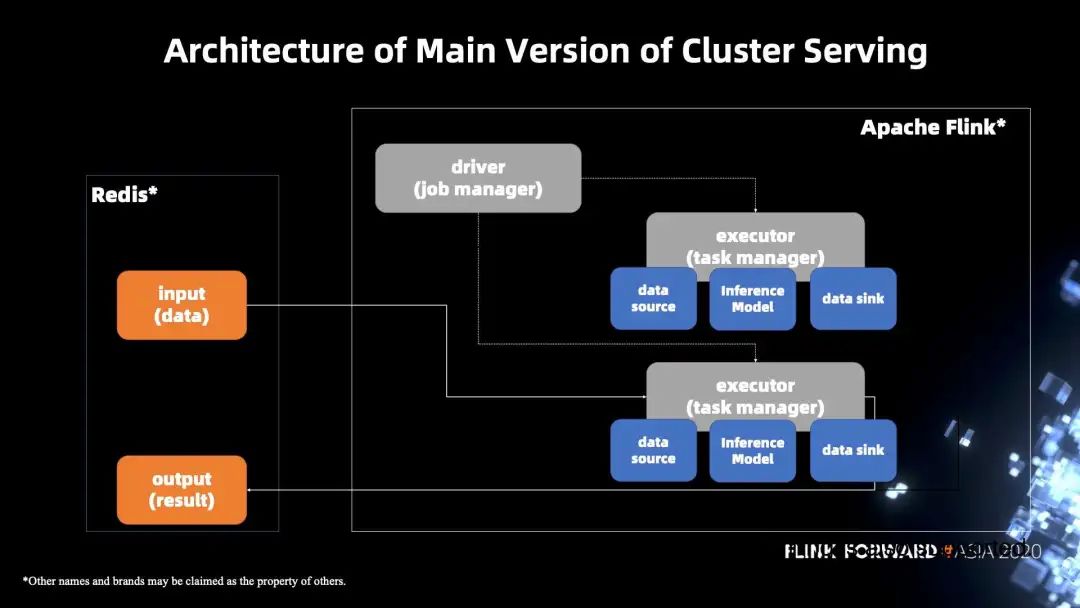
架构的优势:
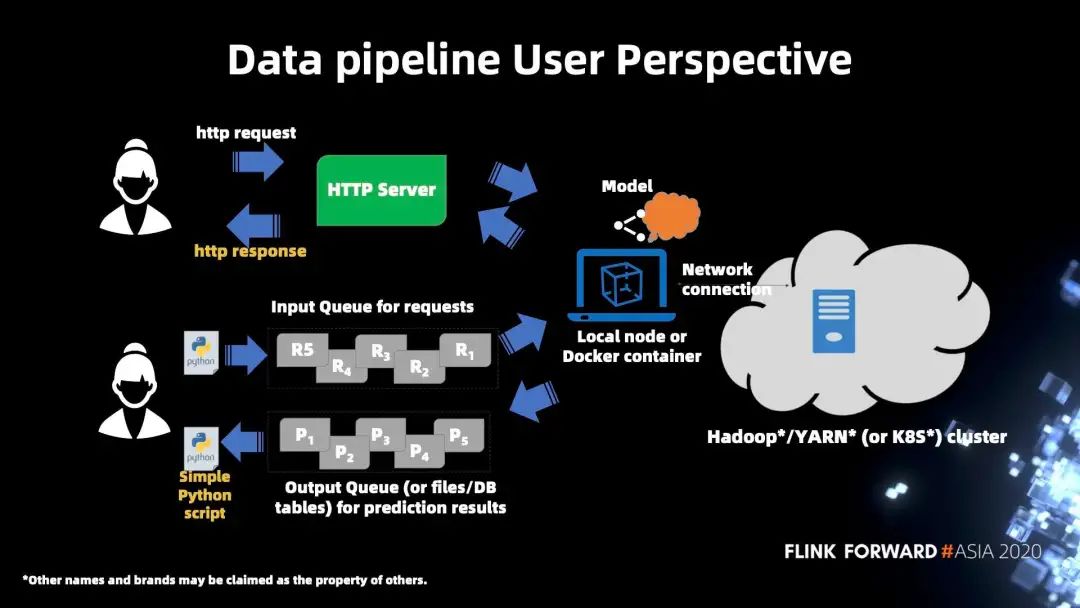
下图展示了从用户的角度来看整个系统是怎么样运行的:
Cluster Serving 启动的方法:
环境安装好之后,一般 docker 是最简单的方式,安装好之后就可以直接启动,启动之后就相当于服务端已经准备好。
调用之前所提到的 http 或者 python 的 API,往服务发送一个数据请求,完成一个客户端的操作。
按照下面的步骤运行快速入门示例。有关详细说明,请参阅 Analytics Zoo Cluster Serving 编程指南。
启动 Analytics Zoo docker。
#docker run -itd --name cluster -serving --net=host intelanalytics/zoo-cluster-serving:0.7.0bash
登录 container 并转到准备好的工作目录。
#docker exec -it cluster-serving bash
#cd cluster-serving
在 container 内启动 Cluster Serving。
#cluster-serving-start
两种类型的 API:
下图是一个 API 样例,这是一个 http 的 API,包含各种各样的数据类型,目前可以支持普通常数、tensor、sparse tensor、image encoding 等类型。应该是包含了目前在实际使用中遇到的所有数据类型。这些数据类型都包括在一个 json 的 string 里面。可以通过发送一个 curl 命令,去直接拿到结果。

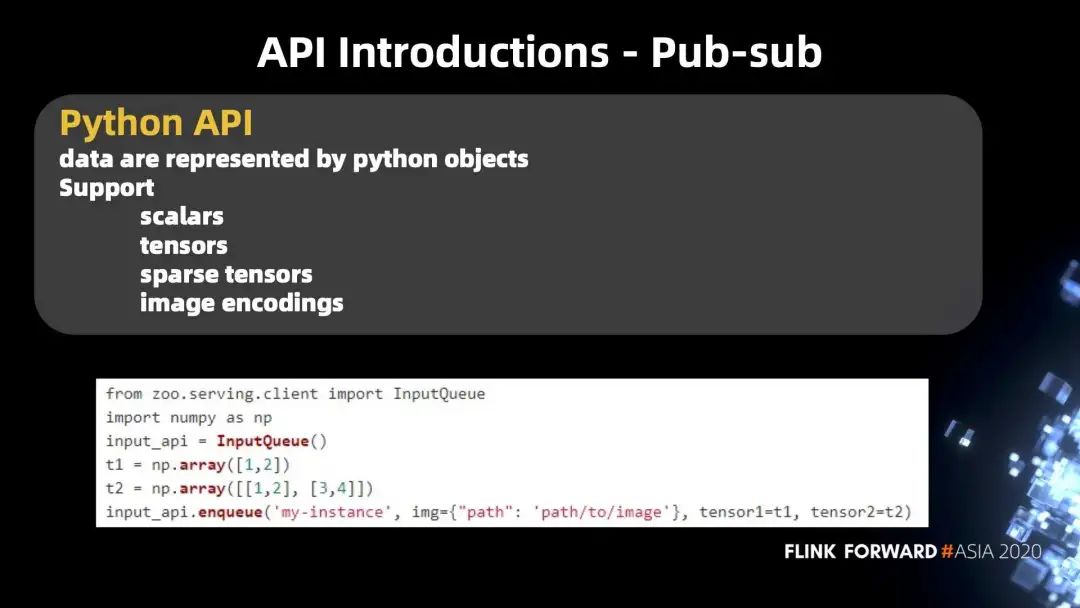
下图是 python 的 pub-sub 的 API。可以看到大体上支持的数据类型和使用方法,与 http 的 API 是差不多的,只是数据的表示有一些区别,也有两个 API。通过随便生成的 2 个 ndarry,然后调用了一个 API,就可以把数据放进 Cluster Serving,并调用一个 API 去把数据取回来。
四、使用案例
医学影像的推理是一个比较常见的能体现 Cluster Serving 价值的使用案例。含有数量巨大的 x 光胸片,且医学影像中图片的像素点也很多,对实时推理要求很高。在普通的单机情况下,需要做预处理、推理等所有的操作,耗时一般都是要小时级的,但是为了达到对实时性的要求,会通过分布式的框架把耗时缩短到分钟级。

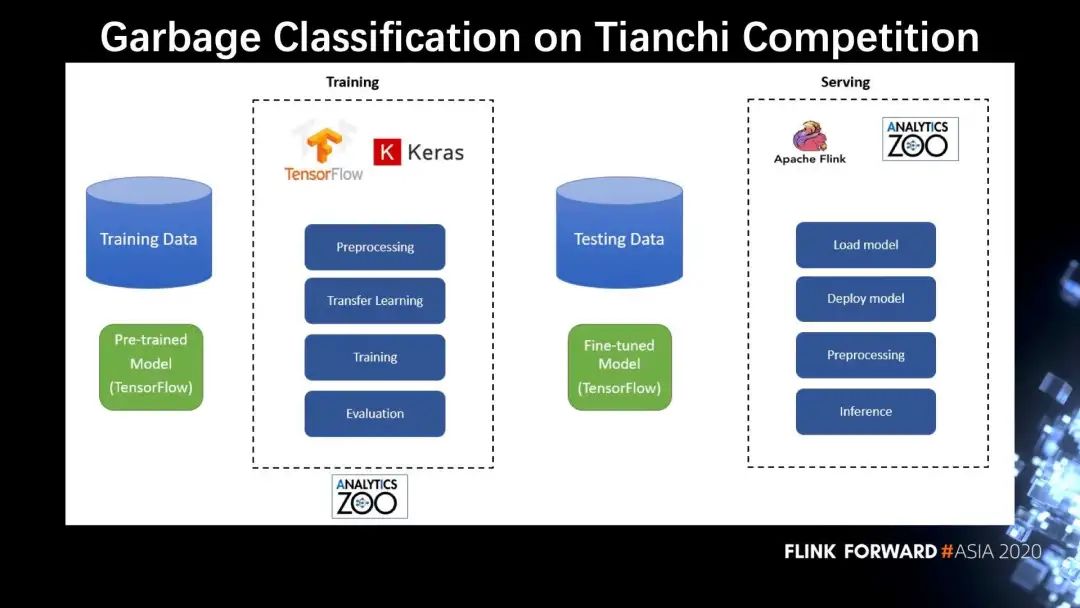
接下来介绍跟天池平台合作的一个垃圾分类的比赛,左边是训练过程,通常使用的是 TensorFlow 和 Keras,或者是经过 Analytics Zoo 封装后的 TensorFlow,把一个预训练的模型,进行一个微调 (finetune)。微调之后,拿到测试数据,使用 Flink 在分布式的集群上去调用推理接口,集群的每个节点都部署好了 Analytics Zoo 的模型。实时图片的推理是用分布式的 Cluster Serving 来实现的,通过横向扩展的方式来提高效率。
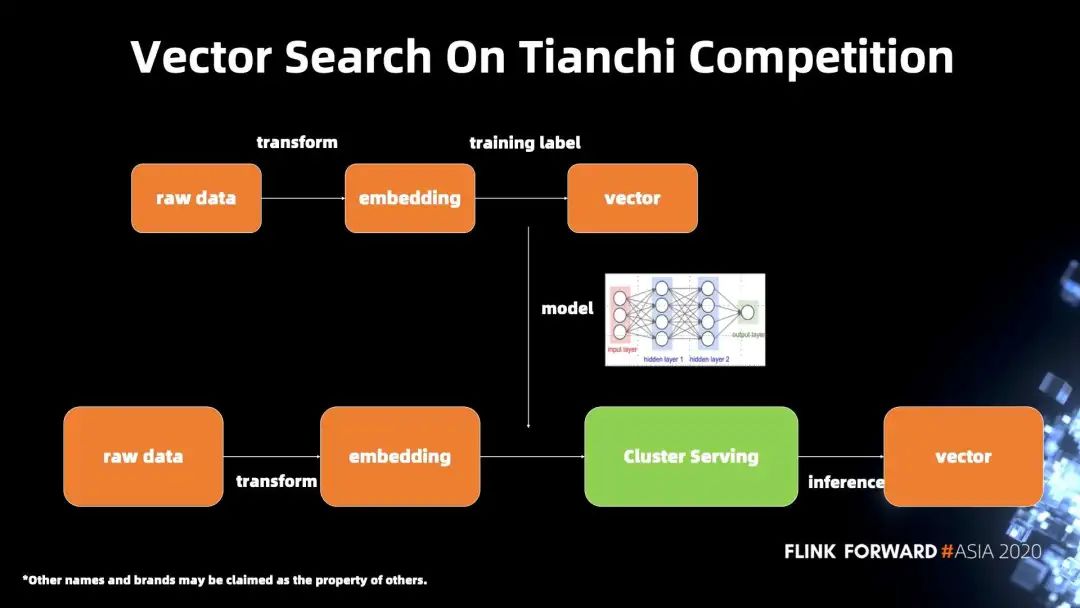
下图是跟天池合作的另一个比赛,这是一个基于流行病学的向量搜索。在比赛里面的模型是一个 autoencode。原始数据经过数据预处理成为了一个词嵌入,然后经过训练得到 vector,在推理阶段使用 Cluster Serving 进行推理。autoencode 模型相比之前的图片模型 resnet50 或者 inception,算是小很多的模型。也就是说,吞吐量本来就已经很高了,在本案例里面,横向扩展的意义并不是明显,但是这次比赛是 Cluster Serving 在第一次在发布后,能够完整的作为一个服务在天池比赛中被应用起来。
五、Flink 社区的一些集成
下图中的案例提供了一个把 Cluster Serving 的主要功能,即分布式推理和多模型的支持,包装成为了一个在 Flink 的 Table 上面的 UDF。这是一个简单的例子,可以看到创建了一个 Envirement,然后数据在 csv 里面,通过一个简单 SQL 语法的语句,去做了一个端到端的训练,然后把结果直接打印出来。SQL 运行之后,实际上就是可以直接去把那个 csv 里面的原数据去进行一个分布式的推理,最后输出出来。

最后,Flink 2.0 有一个新的特性是 StateFun 函数。这张架构图和之前 Cluster Serving 的主要架构图没有很大的区别。唯一的区别在于数据源 (data source),现在只用了一个单节点的数据源。而之前版本是一个模型只能去启动一个 Flink job,一一对应。现在有了 StateFun 函数的新特性,可以通过一个数据源在拿到数据的时候,进行一个路由 (routing),在路由之后,就可以用一个 Flink job 管理多个模型的分布式推理。

热点推荐
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,回顾极客挑战赛解读视频!
戳我,回顾极客挑战赛解读视频!










 京公网安备 11010802041100号
京公网安备 11010802041100号