目录第三方模块的下载pip工具简介pip使用注意pip位置和环境变量设置pip安装第三方模块使用pip下载可能会遇到的问题pycharm的第三方模块下载功能request模块req
目录
- 第三方模块的下载
- pip工具
- 简介
- pip使用注意
- pip位置和环境变量设置
- pip安装第三方模块
- 使用pip下载可能会遇到的问题
- pycharm的第三方模块下载功能
- request模块
- request基本使用
- 请求超时 timeout
- 忽略ssl证书 verify=False
- Session维持
- 办公自动化 openpyxl模块
- 操作excel前言
- create_sheet 创建工作簿
- 写入数据的三种方法
- 工作簿的append方法(重要)
- 链家二手房爬虫
第三方模块的下载
pip工具
简介
pip 是一个现代的,通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能。
注:pip 已内置于 Python 3.4 和 2.7 及以上版本,其他版本需另行安装。
pip使用注意
每个python解释器都有pip工具 如果我们的电脑上有多个版本的解释器那么我们在使用pip的时候一定要注意到底用的是哪一个 否则极其任意出现使用的是A版本解释器然后用B版本的pip下载模块。
pip位置和环境变量设置
pip工具在python/Scripts目录下:

Scripts目录下存在pip文件:

如果想在命令行窗口下使用pip,需要将这个目录添加到系统的环境变量中。

python多版本添加pip路径:

为了避免pip冲突 我们在使用的时候可以添加对应的版本号:
python27 pip2.7
python36 pip3.6
python38 pip3.8
在命令行查看pip版本:

pip安装第三方模块
下载第三方模块的句式:
pip install 模块名
下载第三方模块临时切换仓库
pip install 模块名 -i 仓库地址
下载第三方模块指定版本(不指定默认是最新版)
pip install 模块名==版本号 -i 仓库地址
下载模块:

指定仓库:(清华大学镜像仓库)

指定版本号:(默认是装最新版本 我们指定版本号3.0.5)

使用pip下载可能会遇到的问题
下载第三方模块可能会出现的问题
1.报错并有警告信息
WARNING: You are using pip version 20.2.1;
原因在于pip版本过低 只需要拷贝后面的命令执行更新操作即可
d:\python38\python.exe -m pip install --upgrade pip
更新完成后再次执行下载第三方模块的命令即可
2.报错并含有Timeout关键字
说明当前计算机网络不稳定 只需要换网或者重新执行几次即可
3.报错并没有关键字
面向百度搜索
pip下载XXX报错:拷贝错误信息
通常都是需要用户提前准备好一些环境才可以顺利下载
4.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多 百度查询即可
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:https://pypi.hustunique.com/
豆瓣源:https://pypi.douban.com/simple/
腾讯源:https://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
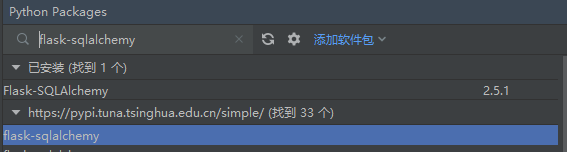
pycharm的第三方模块下载功能
pycharm提供更方便、更直观的下载第三方模块的方式,并且不需要输入命令。
打开settings:

点击加号:

下载第三方模块:

镜像仓库设置:

request模块
request基本使用
import requests
url = 'https://www.baidu.com'
headers = {
'User-Agent': ''
}
r = requests.get(url=url,headers=headers)
print(type(r)) #
r.encoding = 'utf8' # 指定编码
print(type(r.text),type(r.content)) # content是转换为二进制码 注意text、content都是request包内的方法
print(type(r.status_code),r.status_code) # 状态码
print(type(r.COOKIEs),r.COOKIEs) # 获取COOKIEs
print(type(r.history),r.history) # 请求历史
请求超时 timeout
time = requests.get('www.baidu.com',timeout=1) # 1秒内不响应 就抛出异常
time2 = requests.get('www.baidu.com',timeout=(5,30)) # 请求的两个阶段 连接和读取 我们分别设置这两个阶段的timeout 超过就报错
忽略ssl证书 verify=False
# 忽略ssl证书 SSLerror
respOned= requests.get('www.xxx.com',verify=False) # 参数verify控制不验证 HTTPS HTTP
Session维持
# Session维持 模拟同一个会话 不用担心COOKIEs
s = requests.Session() # 创建session对象
s.get('www.xxx.com', COOKIEs='') # 设置好COOKIEs
r = s.get('www.xxx.com/xxx.html') # 再次使用get时,这个COOKIEs状态依旧保持
办公自动化 openpyxl模块
操作excel前言
# 1.excel文件的后缀名问题
03版本之前
.xls
03版本之后
.xlsx
# 2.操作excel表格的第三方模块
xlwt往表格中写入数据、wlrd从表格中读取数据
兼容所有版本的excel文件
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
ps:还有很多操作excel表格的模块 甚至涵盖了上述的模块>>>:pandas
# 3.openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandas
import pandas
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
'''将字典转换成pandas里面的DataFrame数据结构'''
df = pandas.DataFrame(data_dict)
'''直接保存成excel文件'''
df.to_excel(r'pd_comp_info.xlsx')
# 4.excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作几乎无效
需要使用代码操作>>>:pandas模块
create_sheet 创建工作簿
from openpyxl import Workbook
wb = Workbook()
print(wb) # 创建一个workbook对象 #
# 创建工作簿对象 worksheet
wb1 = wb.create_sheet('学生名单')
wb2 = wb.create_sheet('舔狗名单')
wb3 = wb.create_sheet('海王名单')
print(wb1) #
# 修改默认的工作簿位置
wb4 = wb.create_sheet('富婆名单', 0) # 将其修改为第一个工作簿
# 还可以二次修改工作簿名称
wb4.title = '高富帅名单'
# 修改工作簿的颜色
wb4.sheet_properties.tabColor = "1072BA"
# 保存该excel文件
wb.save(r'black.xlsx')
写入数据的三种方法
# 填写数据的方式1
wb4['F4'] = 666 # 将F4单元格写入666
# 填写数据的方式2
wb4.cell(row=3, column=1, value='miku') # row行 column列
工作簿的append方法(重要)
# 填写数据的方式3 (重要)
# 首先这是写入wb4 对应的工作簿内
# 一个append对应excel中的一行,会将列表元素一个一个放入这一行的单元格内。
wb4.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb4.append([1, 'mike', 18, 'read'])
wb4.append([2, 'kevin', 28, 'music'])
wb4.append([3, 'tony', 58, 'play'])
wb4.append([4, 'oscar', 38, 'ball'])
wb4.append([5, 'jerry', 'ball'])
wb4.append([6, 'tom', 88,'ball','哈哈哈'])
输出结果:

链家二手房爬虫
import requests
import re
import time
from openpyxl import Workbook
TIME = time.strftime('%Yy_%mm_%dd_%H%p_%Mm_%Ss') # 定义时间
KEY_WORD = '浦东新区' # 搜索关键字
PAGE_NUM = 10 # 定义一共爬多少页 上限100页
URL_TITLE = 'sh' # sh表示上海
HOUSE_SELECT = 'ershoufang' # 表示二手房
house_massage_big_list = [] # 最大的列表 所有的数据都会放入这个列表
if PAGE_NUM > 101:
raise Exception('数字过大 =。=')
# 1.创建100个url
for page in range(1, PAGE_NUM + 1):
url = f'https://{URL_TITLE}.lianjia.com/{HOUSE_SELECT}/pg{page}rs{KEY_WORD}/'
print(url)
try:
res = requests.get(url=url)
except requests.exceptions.ConnectionError:
raise requests.exceptions.ConnectionError('网络抽风了 =。=')
except Exception as massage:
print(massage, '未知异常')
else:
print()
print(f'网络状态码:{res.status_code}')
time.sleep(1)
text = res.text
# 2.获取各种信息 放入不同的列表 一个列表30个数据 也就是一页30个数据
title_list = re.findall('(?P.*?)', text, re.S) # 修饰符匹配空白字符
house_url_list = re.findall('.*?', text, re.S)
site_list = re.findall(
'', text, re.S)
house_massage_list = re.findall('(.*?)
', text, re.S)
house_price_list = re.findall(
' (.*?).*?
'
, text, re.S)
house_m2_price_list = re.findall(
'(.*?) 'n>
', text, re.S)
people_star_list = re.findall('(.*?)
', text, re.S)
# 3. 处理一下存放位置数据的列表 (龙柏二村, 龙柏) ————> 龙柏 龙柏二村
new_site_list = []
for house_site in site_list:
house, location = house_site
new_site = f'{location} {house}'
new_site_list.append(new_site)
site_list = new_site_list
# print(len(title_list)) # 标题
# print(len(house_url_list)) # url
# print(len(site_list)) # 位置
# print(len(house_massage_list)) # 信息
# print(len(house_price_list)) # 总价
# print(len(house_m2_price_list)) # m2单价
# print(len(people_star_list)) # 关注
# 4.放入小列表
one_house_all_massage = list(
zip(title_list, house_url_list, site_list, house_massage_list, house_price_list, house_m2_price_list,
people_star_list))
print(f'数据量:{len(one_house_all_massage)}', '小列表') # 查看长度
print(one_house_all_massage)
# 5.放入大列表
house_massage_big_list.extend(one_house_all_massage)
print(f'数据量:{len(house_massage_big_list)}', '大列表')
print(house_massage_big_list)
# 保存数据到excel
excel_obj = Workbook() # 创建excel文件
# 1.创建工作簿
wb = excel_obj.create_sheet(f'{KEY_WORD}', 0)
# 2.添加表头
wb.append(['标题', 'url链接', '位置', '信息', '总价/万', '每平米的价格/元', '热度'])
# 3.将每个数据存入excel
for i in house_massage_big_list:
wb.append(i)
# 4.保存excel
excel_obj.save(f'{KEY_WORD}_{TIME}.xlsx')







 京公网安备 11010802041100号
京公网安备 11010802041100号