原本这些文字是为了我方便,临时记录的,所以整体逻辑可能不清晰,留坑以后再梳理的更好。
总的来说:
文件结构:
项目P:
项目Q:
oss
1——环境搭建:
2——数据准备:
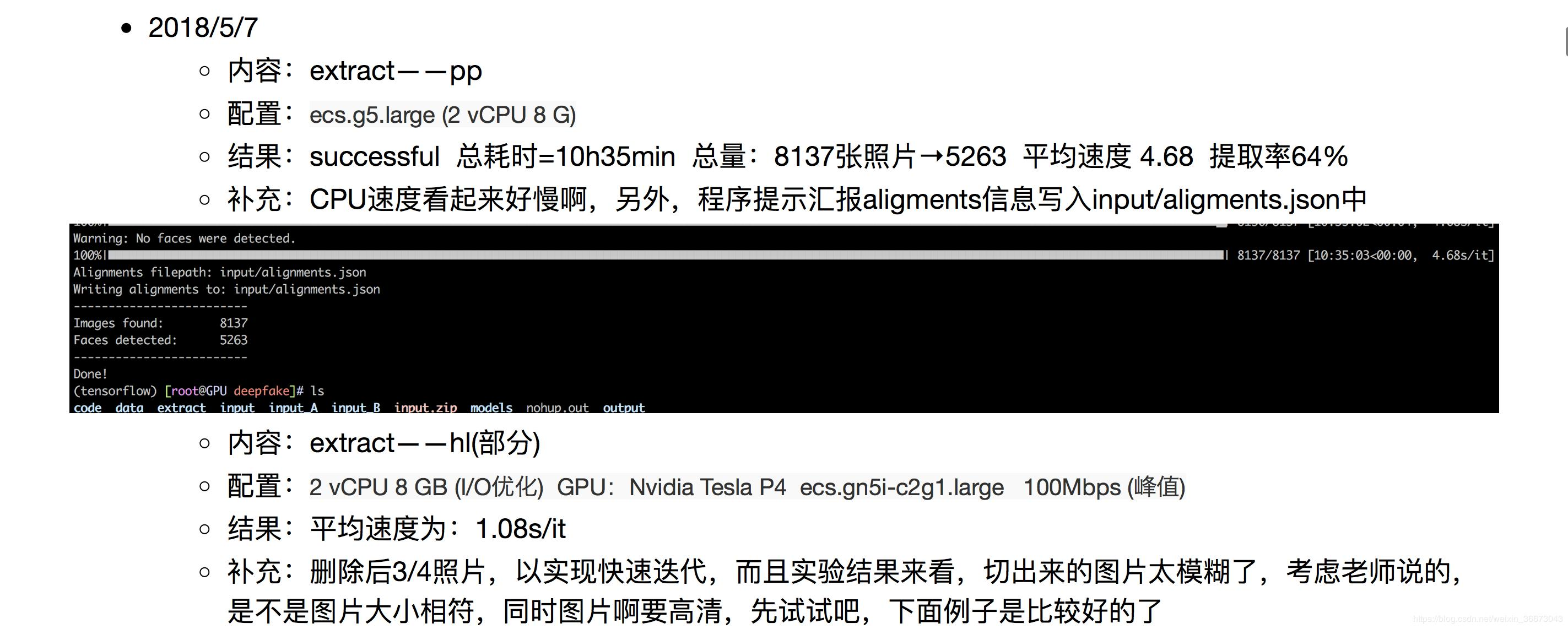
3——人脸提取:extract
4——模型训练:train
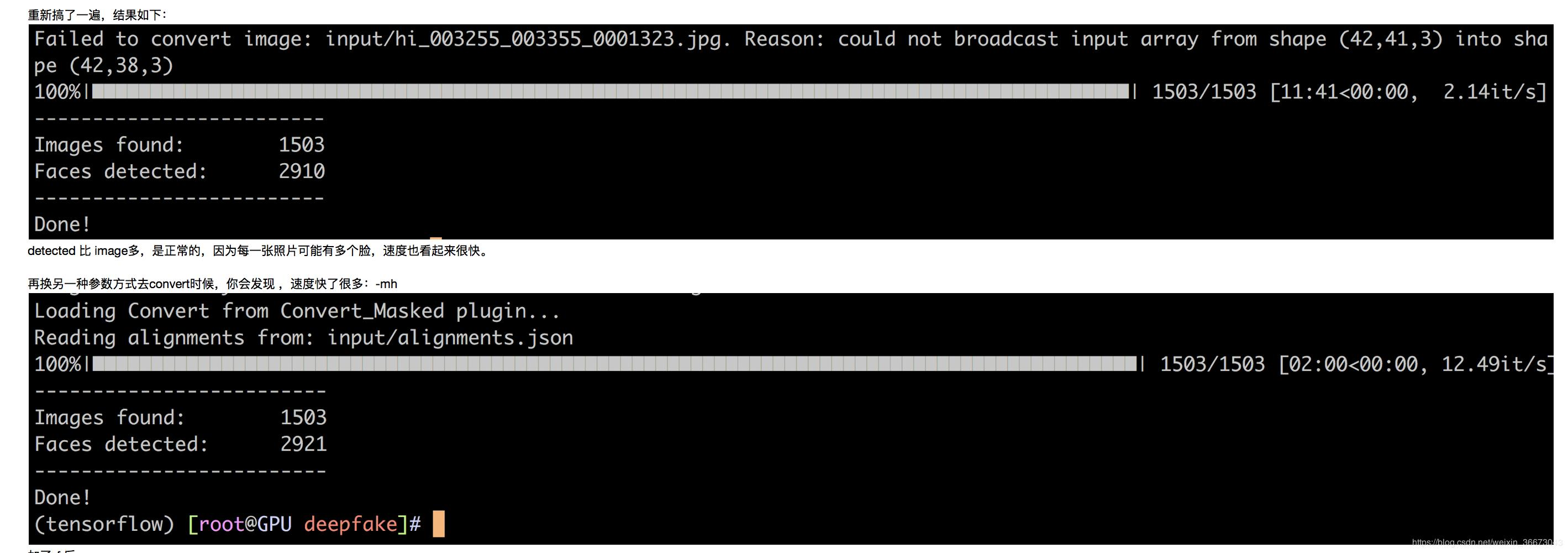
5——照片转换:convert
* 最必要的一个参数就是在convert时候的-f fi
* 其他的参数基本上用处不大(-v 可以展现详细的信息)
* train中的部分参数,可能要启动图形界面相关的东西,在云端无GUI的命令行界面下简单调用可能会出错。
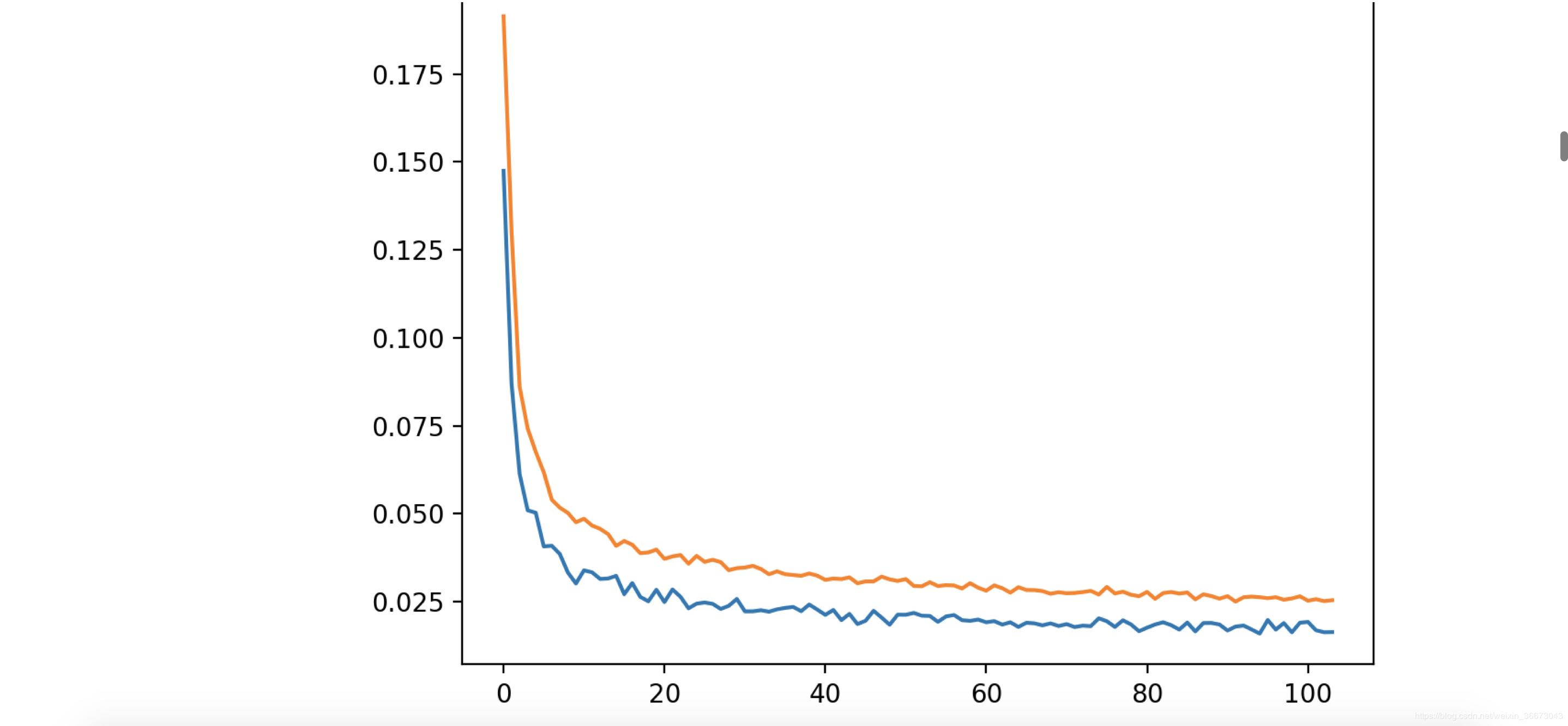
* 训练的时候:input_A是吴京的大头照,input_B是你的大头照(假设你想验一下战狼2),如果反了,在convert中有一个参数可以调整,我的经验下来,感觉,loss_B 的训练似乎非常重要,因为如果视频同一画面中有多张人人脸的时候(例如吴京、达康书记、张翰等等),你会发现你的脸会出现他们每个明星的脸上,而且有时候效果也差不多。
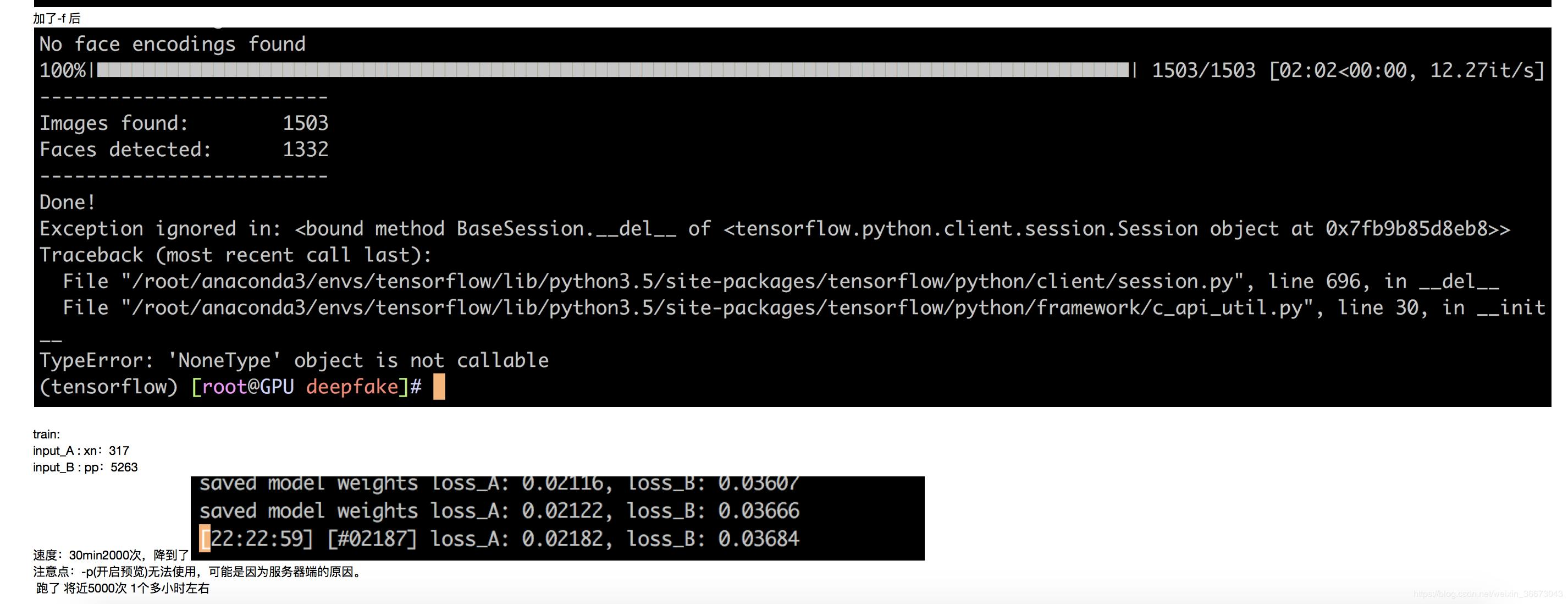
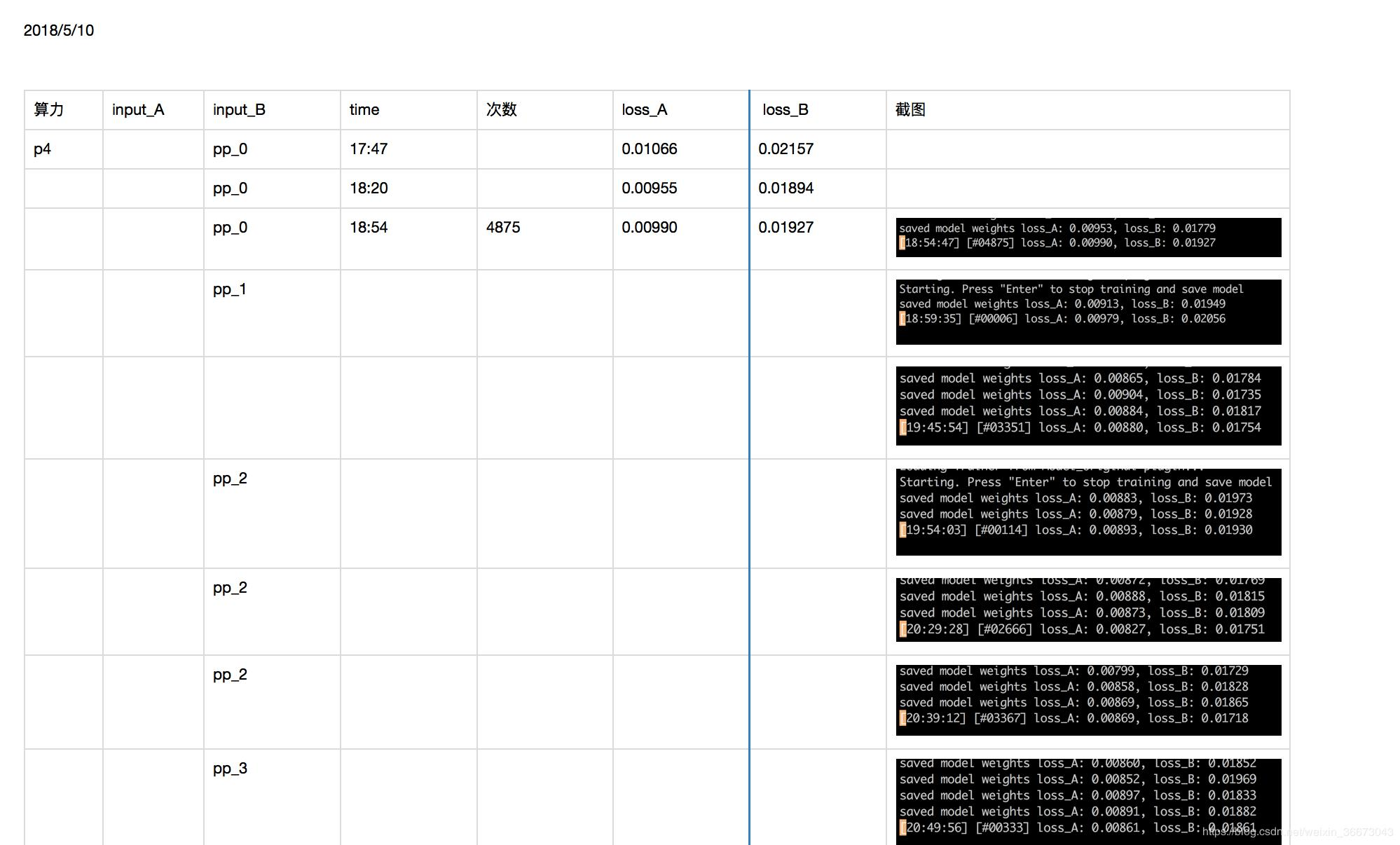
* 如果input_A、input_B文件数比较多,例如5000以上,可以考虑把样本拆分成10 份(等距随机抽样),然后一份一份的训练,先用第一份把loss训练到0.3左右,再在这个基础上,继续训练原有模型,用第二份训练到0.2左右。这样可能比直接用5000份样本来训练,要快一些。
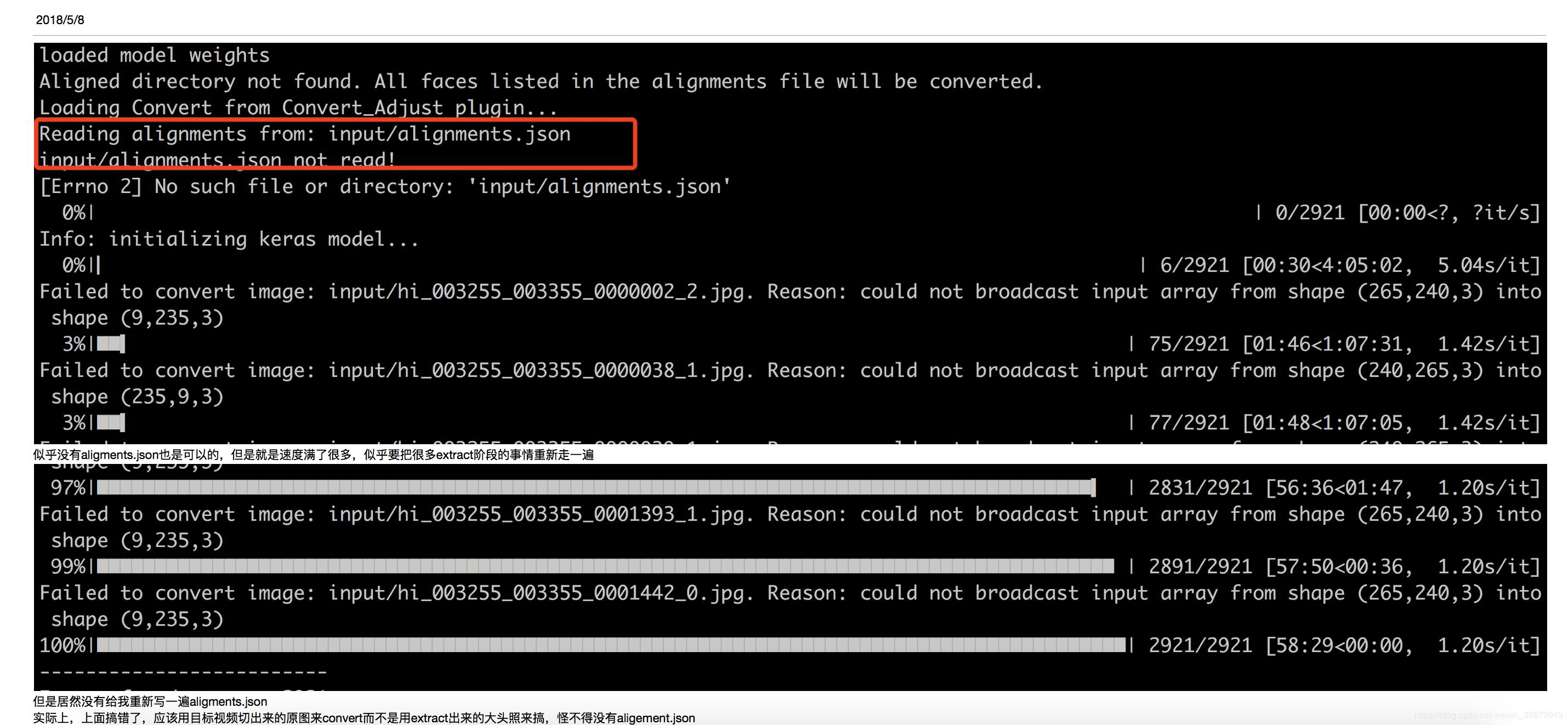
* 注意aligment.json这个文件,这个文件在extract过程中,在input文件里产生的,里面保存的应该是人脸识别的一些结果,例如68个关键点的坐标等等。如果你仍然用这个input文件去convert,会自动调取aligment.json文件的结果,而不是在convert过程再去识别一次。如果input里的这个文件不小心被你删掉了,那么程序就会从新去识别一次人脸,找出关键点等等,这样convert过程就会很慢,很慢。
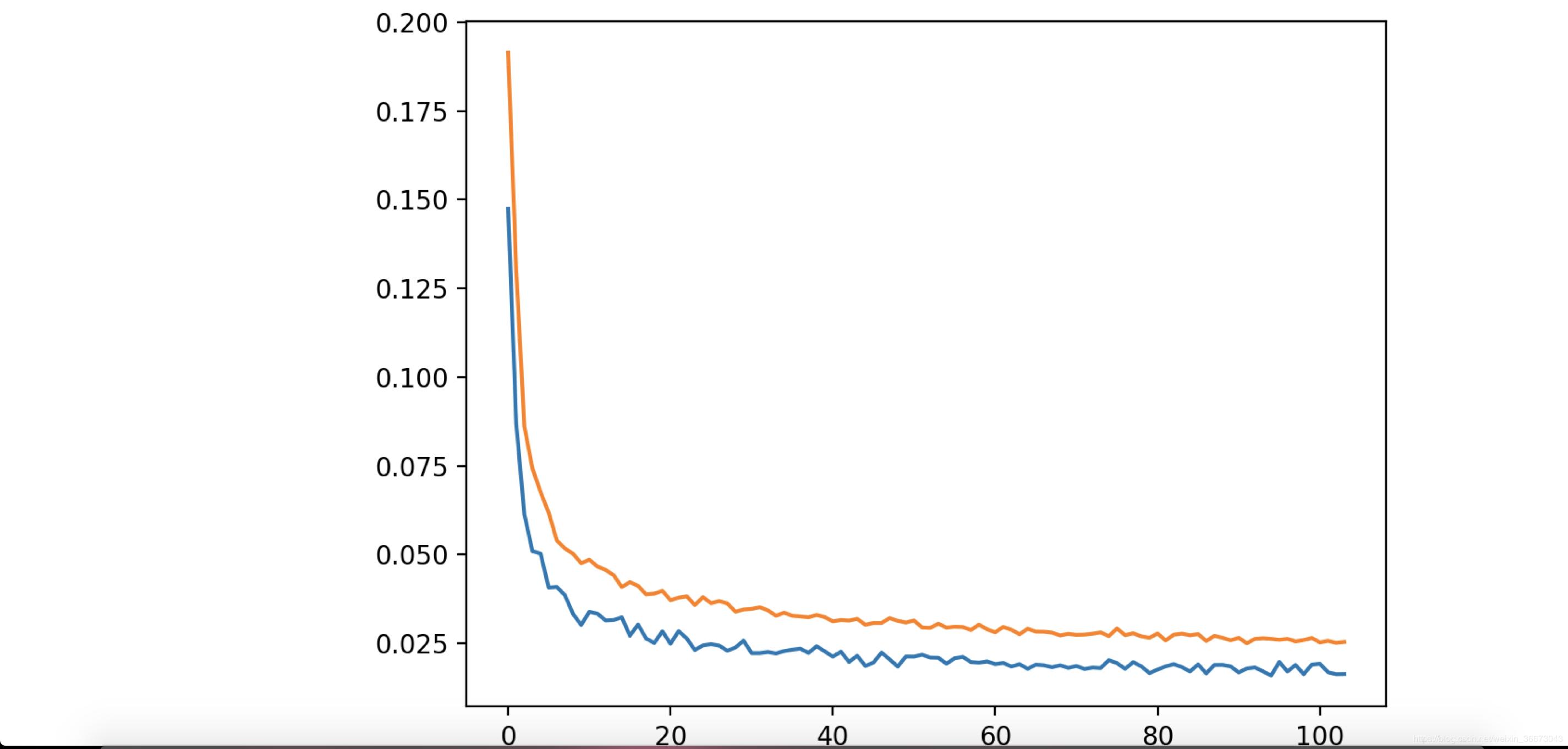
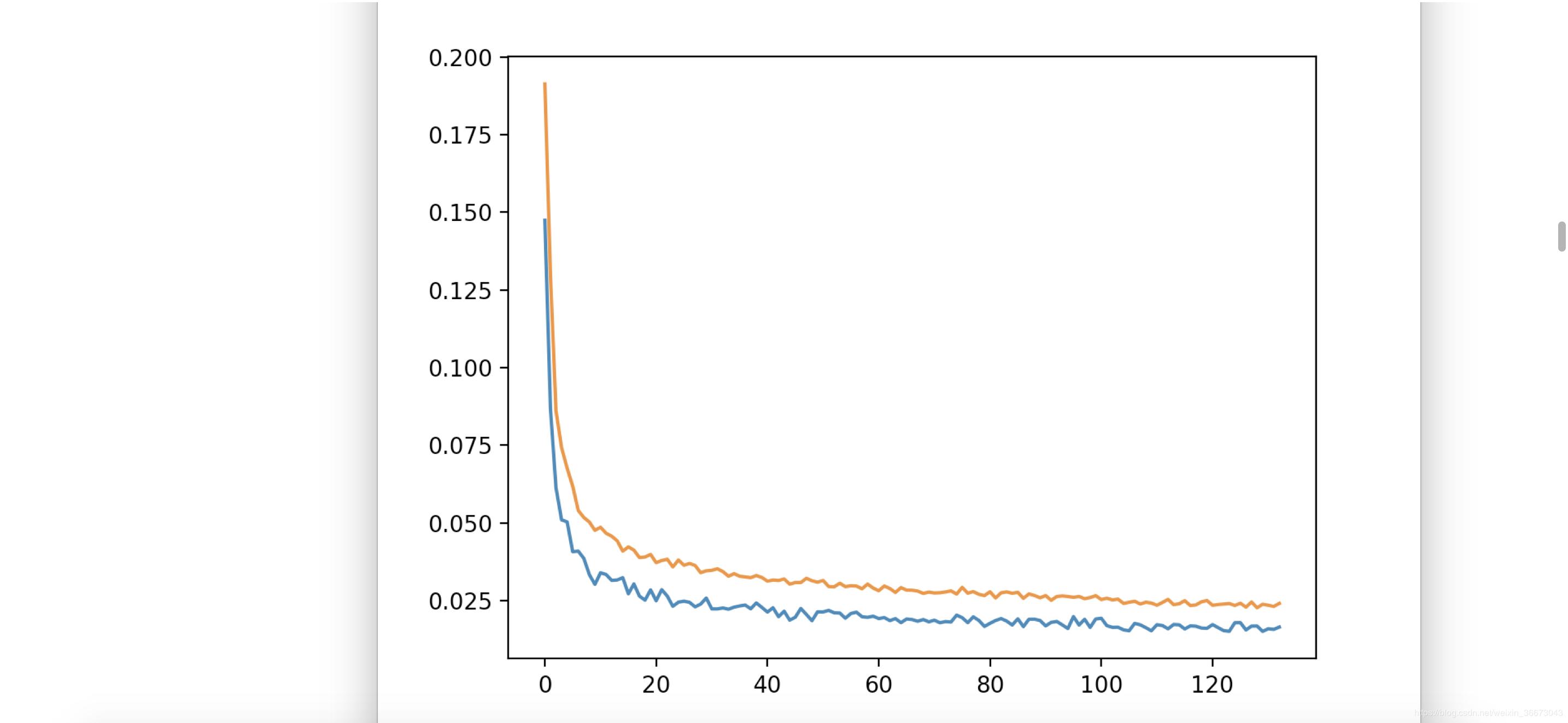
* 从耗时角度来看:最耗时的是train过程,要想把loss降到0.15以下,可能花费数个小时的GPU时间,下来是extract过程,稍微会花一些时间,十几分钟到几十分钟不等,取决文件数量。convert非常快,前提是aligment.json文件正确且完好。当然以上都是PGU环境下,CPU环境下,会非常慢,train过程更是无法想象。
* models 是可以借力训练的:* 训练一半,按下enter键退出训练(千万不要Ctrl+C)并保存结果后,可以再次启动训练,程序会默认加载已有的models继续训练(除非没有models)。* 利用上面这个特性,你可以在你替换吴京的models基础上训练你替换钢铁侠。
* 整个过程,难点是环境搭建和效果优化两个层面* 环境搭建:建议用anaconda建立虚拟环境,借用阿里云镜像市场的深度学习镜像,配合镜像保存环境,具体内容见环境配置。* 效果优化:主要牵扯到效果优化和速度提升。* 效果优化:低级层面能操作的就只有优化样本,和调整参数* 速度提升:低级层面能操作就只有优化样本了。
* 省钱策略:* 充分利用阿里云OSS:可以更加快速传输文件,更加廉价的保存文件* 镜像:基本环境搭建好了,就可以利用镜像保存环境了。* 其他:利用其他云端平台,还未尝试。
ffmpeg
* 用%4d这样方便排列顺序
更多高质量人脸
* CPU跑提取过程:* 速度太慢,3~4s一个,1万张需要 需要8个小时 如果是晚上自己去跑还是可以考虑的* 建议直接上GPU,不要浪费时间,除非能够利用上睡觉时间。
* 尝试多线程:=cpu数量时,差异不大,但是>CPU数量,就变慢了
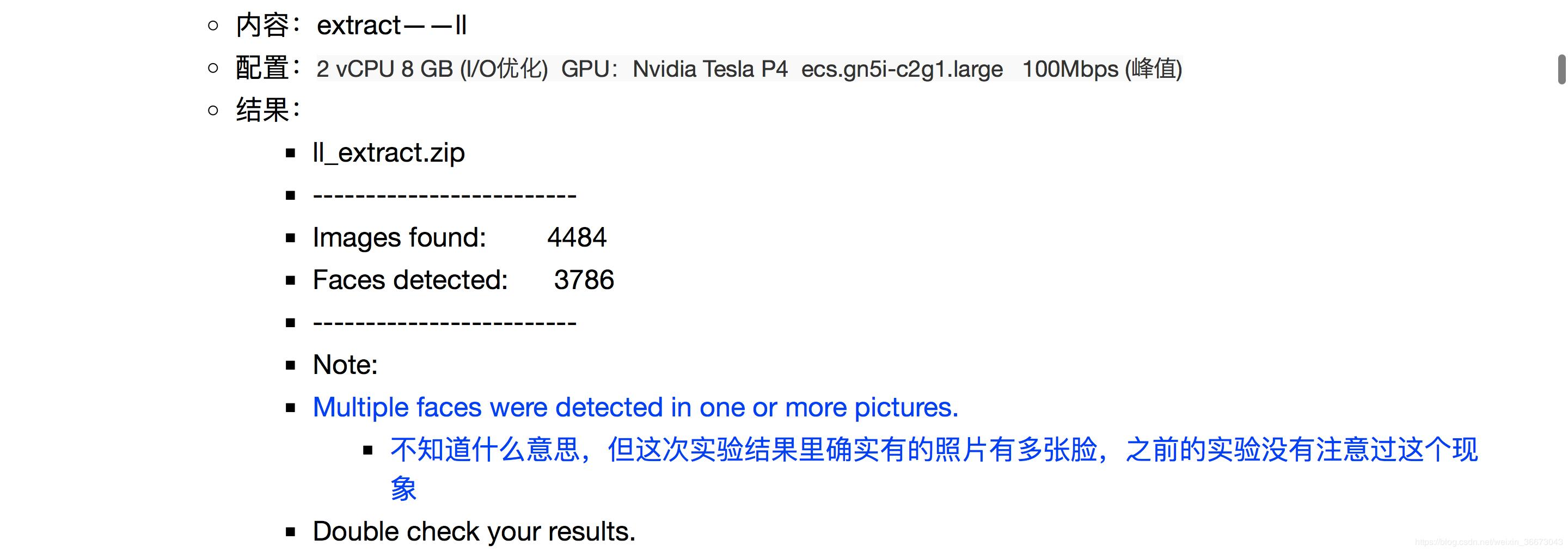
* 提取的时候,加上人脸选择功能:-f 目标人脸 -n 删除掉不是目标人脸的人脸。* 初次尝试,发现加上-f 虽然没有报错,但是也没有work.* 第二次尝试,改变参数的输入方式,由多个照片到一个照片(且照片中仅有一张脸),由字符串到直接输入。依然是没有报错,也没有work。* 第三次尝试,换成输入extract的结果,即大头照,并且cp到当前目录,试试。有效果,但是准确率似乎并不好,很多漏掉的,很多错的也加进来来了。后续可以优化的方法:加上旋转功能或者改变阈值。我决定不在这个方向继续优化,理由是,宁愿多花一点时间,手动过滤,保证数据集的质量,也不在这个上面浪费时间。* -n 第一次尝试,似乎没有任何效果.* 反向使用(-f 非目标人脸jpg),似乎效果挺好的,哈哈,基本上目标人脸都没有是识别出来。指的注意一点是,0405照片似乎是识别出来了(=非目标人脸jpg),但是为什么-n使用的时候,这张照片没有过滤掉呢?* 决定不再继续在这个点上进行优化,因为虽然对速度没有多大改进,但是完全无法保证正确率,所以还是手动筛选吧,以保证数据集的质量。
* 旋转人脸:* 例: python3 code/faceswap-master/faceswap.py extract -r 30* 的确多检查出了一些,但是速度满了6倍,而且还有多了一些不是的,不值得。
* 调价阈值:* 没有尝试,但是不是很建议,可以尝试设置的更高一些,以提高人脸质量,但是相信默认值是作者验证过的最优值。
* 模糊检测:* 不试了,没有必要,速度第一位,其他人来搞。
* 尝试CNN检测器:* python3 faceswap.py extract -D "cnn"* 同样也是慢了很多
* 对其人眼:* python3 code/faceswap-master/faceswap.py extract -ae * 速度正常,可以使用
* 预处理:* 视频预处理:尽量找仅有目标人脸的,尽量把没有目标人脸的视频剪切掉* 图片预处理:原始切出
* 展示更为详细的输出 -v:* python3 code/faceswap-master/faceswap.py extract -v * 实测,可行,可以用来比对速度
* 画出脸部标记:* python3 code/faceswap-master/faceswap.py extract -dl* 没有必要,而且不知道会不会影响后面算法训练过程。
* 多终端一起跑:* 当然首先把数据集进行切分,一起跑,首先可以先手动删掉一些图片,然后再跑。
* 长时间运行,可能会导致速度变慢* 猜测是因为没有做内存优化,导致内存膨胀原因导致。* 解决:停掉进程,同时再次运行时,先检测运行结果 加上-s
* alignments.json 是在extract这一步写到input里的,在后面convert时候会用到,这个只要在目标视频的extract过程注意好就行了,即为目标视频,你必须这样切一下。别忘了在extract后,把json文件加到原文件当中。* 记得在多次对同一个input进行尝试时候,每次尝试都要删除一下 input里的alignments.json文件
* 模糊提出;* 并不是真正剔除,会放到output/blur文件夹内* 操作形式为 -bt 参数int 或者 --blur-threshold 参数int * 参数取值建议我3比较理想
* 做一个人脸识别系统,把阈值大于一定值的人脸全部跳出来,删除掉* 可以先把阈值设的高一点,把一定不是的删掉,然后再阈值降低,再删除* 当然每一波都得要人眼过滤一遍* 最终结果也要人眼过滤一下
* 视频* 尽量找只有目标人物的。* 在切出照片前可以提前剪辑,去掉没有大段没有目标任务的片段。
* 照片:* 爬虫百度图片* 爬虫其他明星照片网站
* 使用OSS作为数据中转站:
* 做一个表格辅助多线程操作(记录操作步骤和关键信息)
* 服务器端用本地磁盘,加快下载复制速度:没有必要,已经很快了,而且用本地磁盘成本陡升,用ssd盘就好了

* 而数据B包含想要插入到数据中的人的面孔
* 拼接时:转换出的人脸比较小的话,拼接时,拉伸到比较大时,就会导致比较模糊
* 拼接时:脸的外侧有一个模糊的区间,也会产生问题。
* 选择人脸的区域:完全整个人脸都选中了,还是选了一部分呢,也会影响最终效果
* 两个人脸的相似度,会影响。
* 既用视频中的人脸,也用外部的人脸,这样效果会好一些(防止过拟合或欠拟合xs)
* 侧脸也会影响。
* 通用模型:别人训练好,直接用就好,例如dlib。非通用模型: 每次应用时候,都需要全部或部分单独训练,例如AB人脸替换。AB替换时,如果你用奥巴马的脸替换川普的模型训练好了,再制作奥巴马替换普京的时候,可以用之前的模型直接继续training,会省时间。
* deepfake 版本选择:选deepfake-fakeswap
* shuffle 优化:把原始图片扭曲后送入encoding,因为图片扭曲了,更容易学到共性。
* 边缘拼接:
* 训练集:并非图像越多越好,最好找一些多角度的高质量的图片训练集
* 难度在于配置,想办法在iCloud跑通。
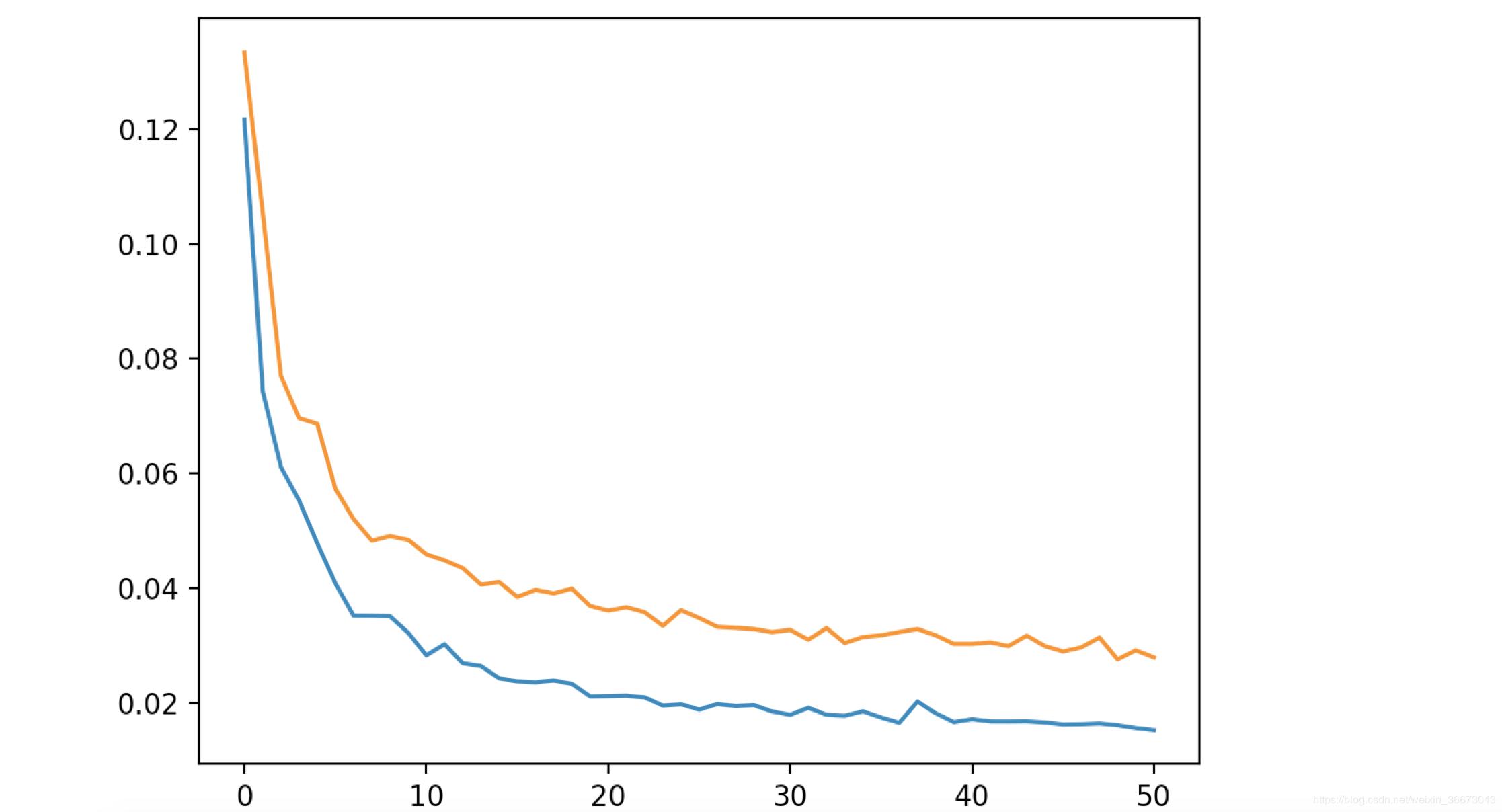
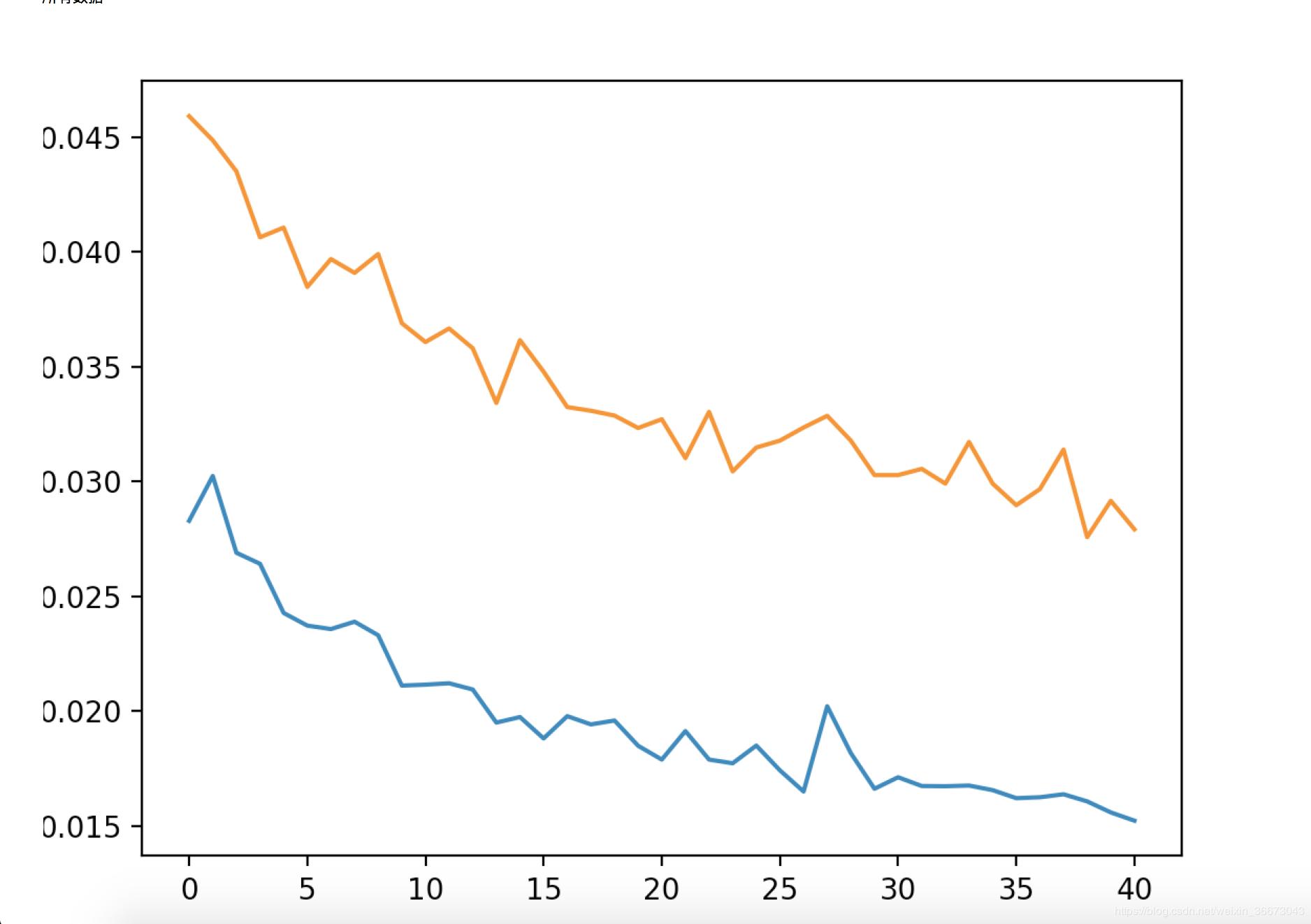
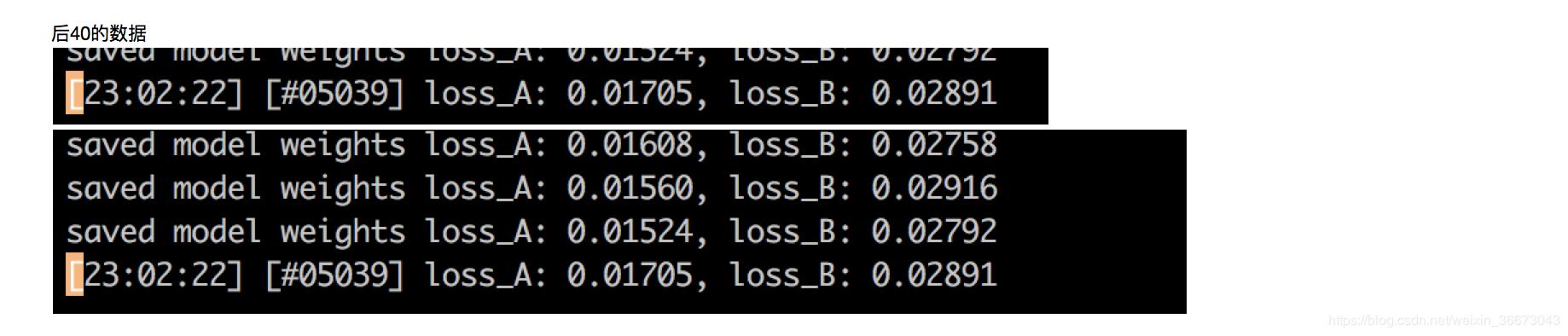
* loss 降到0.015以内
I trained a video of Katy Perry with many different scenes, that caused the 20 days delay. Since the scenes had different positions on the faces, I had to take lots of pictures of mine. I realized that it's faster if you train each separate scene. Now that I have 20 days of training, I spend about 30 minutes on new scenes using the previous training.
源代码使用教程:
github.com/Fabsqrt/BitTigerLab
https://github.com/Fabsqrt/BitTigerLab/blob/master/SystemDesign/DeepFake/README.md
python环境变量的修改:
https://blog.csdn.net/qw_xingzhe/article/details/52695486
深度学习环境配置:
http://www.52nlp.cn/深度学习主机环境配置-ubuntu-16-04-nvidia-gtx-1080-cuda-8
GPU计算能力查询表:
https://blog.csdn.net/JiaJunLee/article/details/52067962
https://blog.csdn.net/allyli0022/article/details/54628987
cudnn下载:但是这个cudnn不知道怎样用,怎样解压
https://developer.nvidia.com/rdp/cudnn-archive
如何让linux程序在ssh shell关闭后继续运行?
https://blog.csdn.net/u012973744/article/details/37659551
https://blog.csdn.net/laven54/article/details/45569617
统计文件数
https://www.cnblogs.com/uzipi/p/6100790.html
图片体积,图片分辨率,图片尺寸之间是啥关系?
https://www.zhihu.com/question/19617114
创建镜像
https://help.aliyun.com/document_detail/25460.html?spm=5176.11065259.1996646101.searchclickresult.261b66d0mZJyAI 链接。
linux操作
查看文件夹下文件个数: ls -l |grep “^-”|wc -l



放大100倍后的图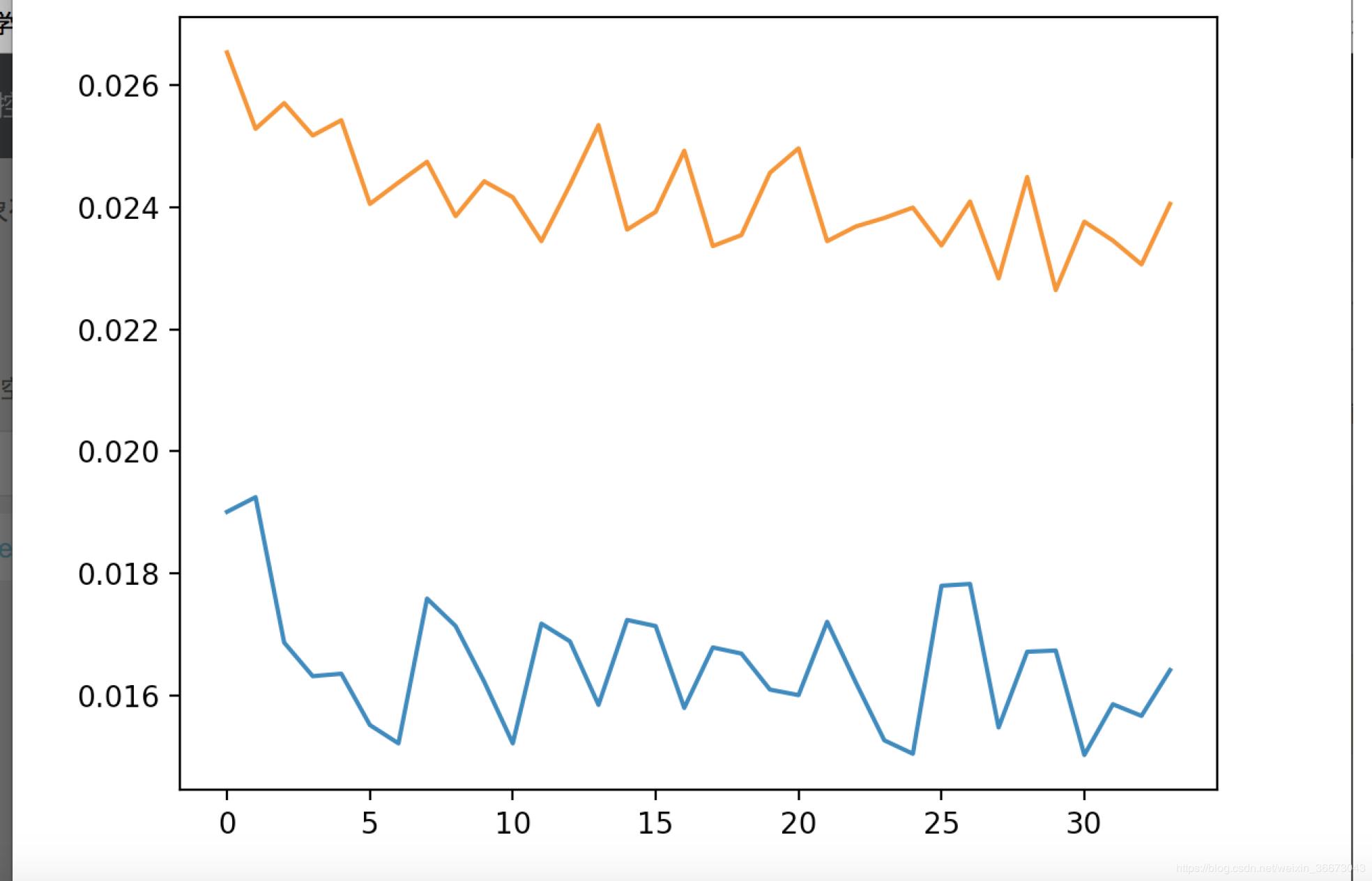


apt-get 源更新:
https://www.cnblogs.com/gabin/p/6519352.html
数据源是视频,所以免不了用ffmpeg进行一顿操作。
ffmpeg安装:可用anaconda一键安装
ffmpeg操作:
必要库安装:其他的都问题不大,直接用pip或者是conda安装即可,主要是下面三个比较难搞
TensorFlow:
dlib:
同时安装 face_recognition,dlib
综合下面两个教程:
OpenCV:如果普通的pip、conda方法不行,尝试下面的方法:
pip:
安装结果检查:基本上直接用Python import一下就好了。
tensorflow检查:
import tensorflow as tf
检查版本:tf.version
安装路径: tf.path
安装TensorFlow:http://wiki.jikexueyuan.com/project/tensorflow-zh/get_started/os_setup.html
软件:配色、wget、anaconda、zip、unzip、scp、ssh
ssh
ssh -i fenneishi_personal_1.pem root@47.100.229.181 —— 绑定秘钥
ssh root@47.100.229.181 ——————————————–没有绑定
配色方案
anaconda
scp
scp -r root@101.132.150.5:/root/tiger/congcongphoto congcongphoto
wget:
oss:
https://help.aliyun.com/product/31815.html?spm=a2c4g.11186623.3.1.1YQRqF
Mac文件上传到OSS:直接拖拽即可
服务器从OSS下载文件:wget -c 即可(速度要求不高时)
工具下载地址:建议把名字改成oss
本地化调用配置:把oss 放到PATH变量支持的路径或者修改PATH也行(echo $PATH 查看PATH变量 )
先修改权限:chmod 755 ossutilmac64
配置文件配置:
02Z5bGk3YstFfWqf4VGoCfJ36OIBPD
迁移CUDNN:
你还需要设置 LD_LIBRARY_PATH 和 CUDA_HOME 环境变量. 可以考虑将下面的命令 添加到 ~/.bash_profile 文件中, 这样每次登陆后自动生效. 注意, 下面的命令 假定 CUDA 安装目录为 /usr/local/cuda:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64"
export CUDA_HOME=/usr/local/cuda
linux 检查nvdia驱动
https://zhidao.baidu.com/question/91751639.html
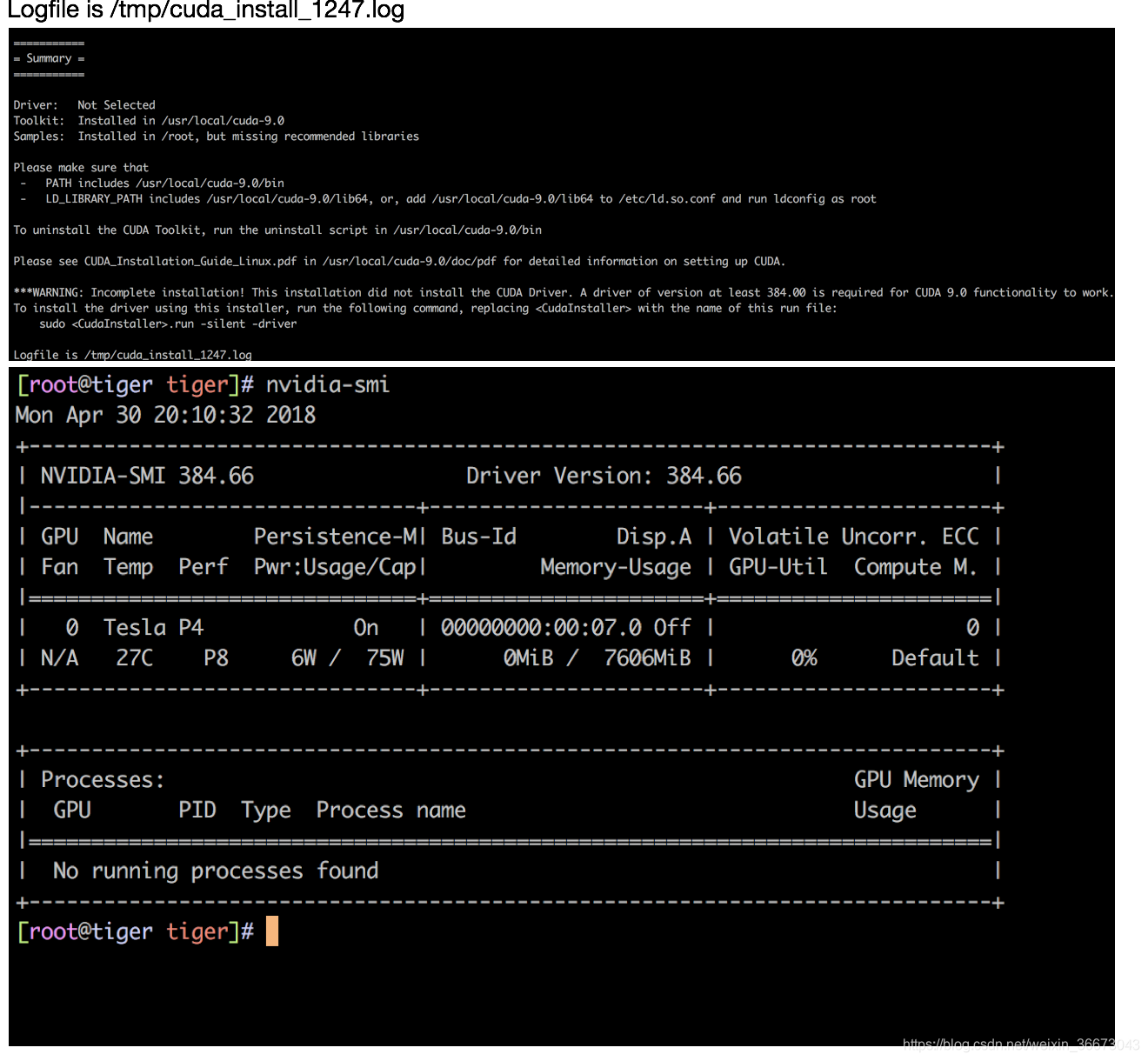
查看nvdia 信息:nvidia-smi
命令行下执行:$ lshw -c video看configurure字段有没有driver字样,若有内容,则显卡驱动装好了。
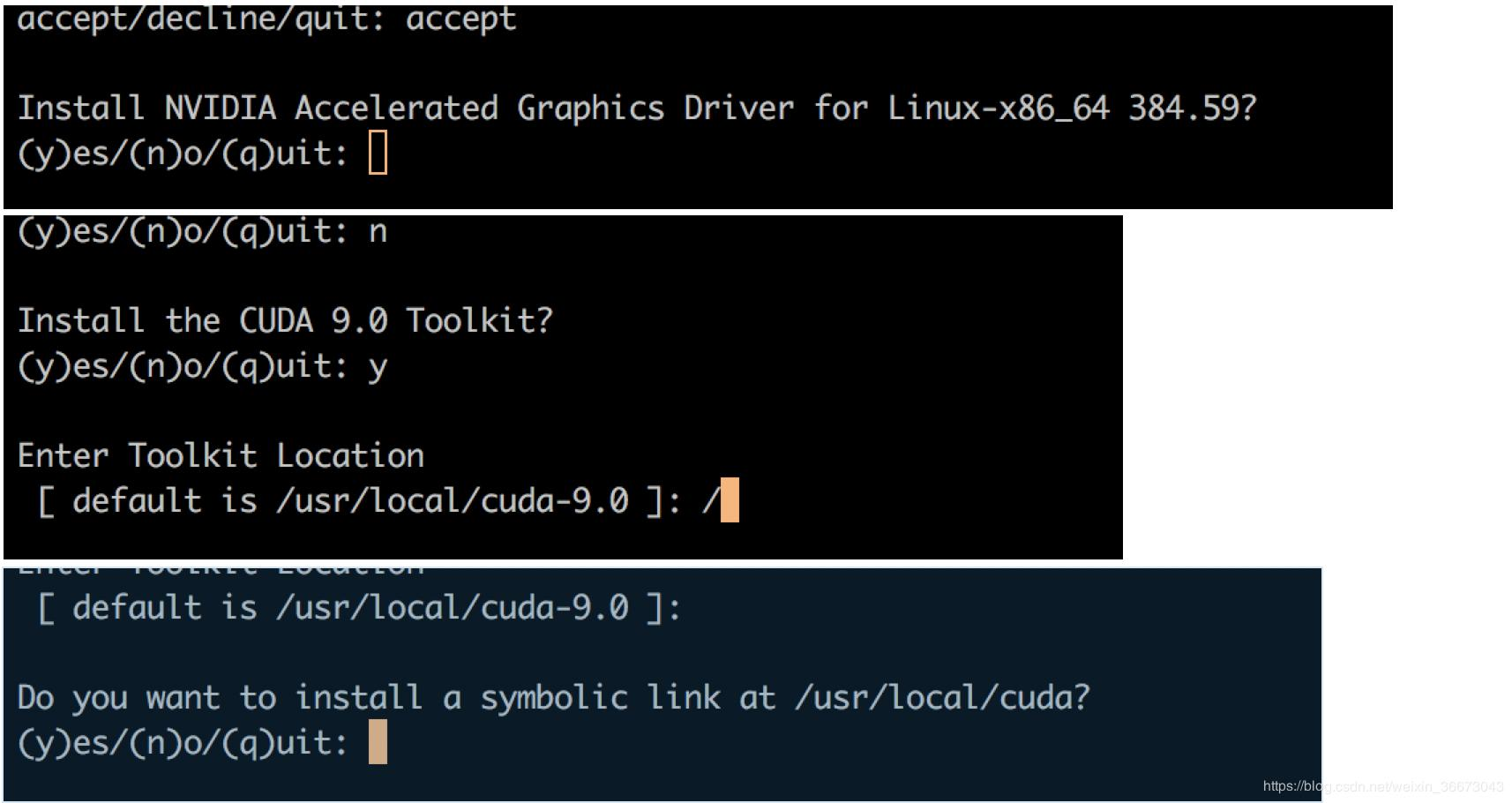
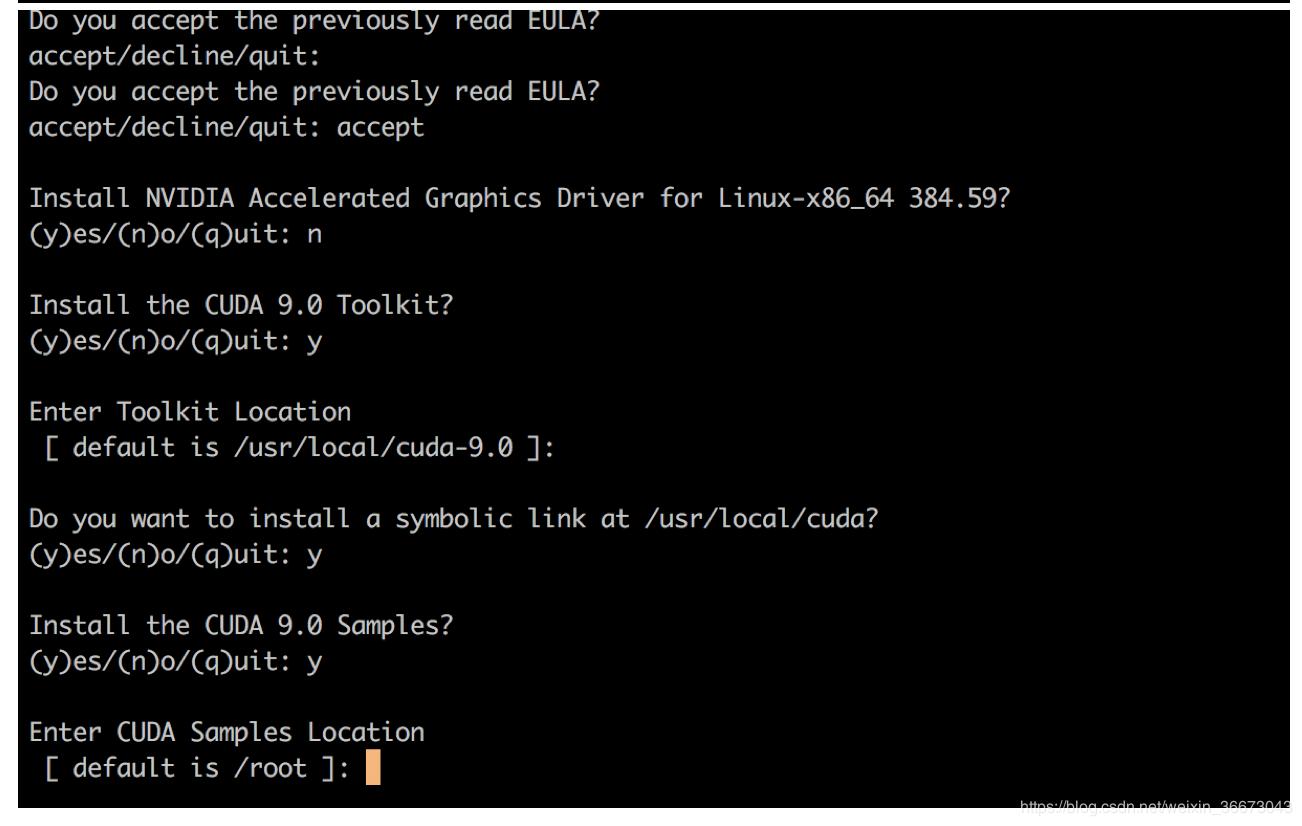
直接安装CUDA 会有相应的驱动自动安装的
GPU驱动安装:
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-9.0
Samples: Installed in /root, but missing recommended librariesPlease make sure that- PATH includes /usr/local/cuda-9.0/bin- LD_LIBRARY_PATH includes /usr/local/cuda-9.0/lib64, or, add /usr/local/cuda-9.0/lib64 to /etc/ld.so.conf and run ldconfig as rootTo uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-9.0/binPlease see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-9.0/doc/pdf for detailed information on setting up CUDA.***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 9.0 functionality to work.
To install the driver using this installer, run the following command, replacing

1、input/alignments.json not read!
解决:在用ffmpeg从视频中提取图片集时,会出现这个/alignments.json。另外,最终用来转换的是原始照片集,不是用deepfake.py extract 出来的大头照。
2、源码参数不调节会把照片中所有人脸全部替换掉,而不是只替换目标人脸。
解决:只出现目标人脸
3、ImportError: libiomp5.so: cannot open shared object file: No such file or directory
解决:猜测是因为云端的英特尔芯片驱动问题,所以直接上了GPU的实例+搭建好的深度学习unbuntu框架.
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_36673043/article/details/86594786










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 