作者:nowemf | 来源:互联网 | 2023-08-18 19:10
在大数据Hadoop组件中,有MapReduce、Spark,但基于实时的流式计算,Hadoop体系外的Storm有着不可替代的快速的优势。那Storm的作用是什么呢?
一、Storm的应用场景
主要用于基于网络的快速小数据处理。比如用户在淘宝网站上点击了什么链接、最新的订单从哪个地方产生。这些数据信息量其实不大,但要求进行快速的处理实时处理,以便于实时的呈现。
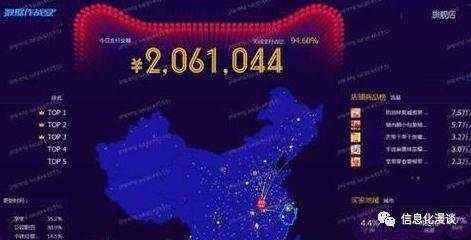
例如下图,阿里的实时订单数据,我们可以进行成交金额的快速获知
二、Storm与MapReduce的区别
1、Storm特点:基于内存计算、基于网络数据来源、用于实时计算
2、MapReduce特点:基于磁盘计算、数据来源于磁盘、用于批量非实时计算。
大家觉得Storm很有优势,但实际天生我才必有用,MapReduce的作用也很大。我们将所有的数据都存放到HDFS中,一般数据可为PB级别,采用MapReduce可充分发挥分布式计算的特点,得到区间段的数据分析结果。例如,运营商可以基于MapReudce可以分析所有网络用户访问互联网网站的Top10记录,以便于进行针对性的网站服务保障。
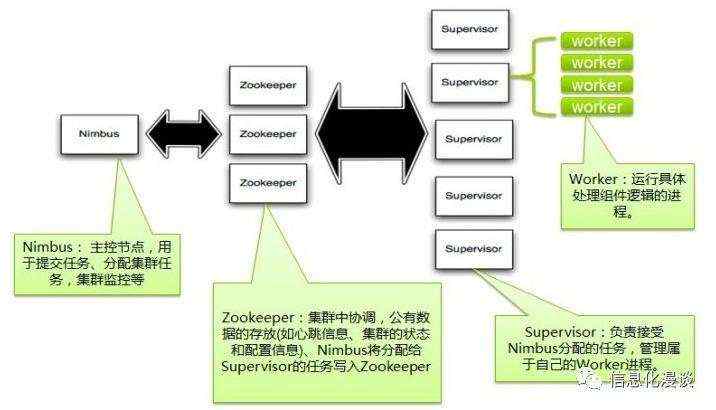
三、Storm的重要组件
1、主节点Nimbus,进行计算任务的分配,提交具体任务
2、Zookeeper,用于Nimbus与Supervisor的任务调度。Nimbus将任务写到Zookeeper中,Supervisor通过ZookeeperClient至Zookeeper的INI中取到具体的任务。同时,Nimbus通过Zookeeper感知到哪台工作机无法工作,将不再把任务分配给该故障工作机。
3、Supervisor中运行worker进行,运行具体的计算任务。
四、Storm的工作流程

Storm在运行中可分为spout与bolt两个组件,其中,数据源从spout开始,数据以tuple的方式发送到bolt,多个bolt可以串连起来,一个bolt也可以接入多个spot/bolt。
Topology:Storm中运行的一个实时应用程序的名称。将 Spout、 Bolt整合起来的拓扑图。定义了 Spout和 Bolt的结合关系、并发数量、配置等等。
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:Tuple的集合。表示数据的流向。
五、Topology的运行
在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapReduce任务相似。但是有一点不同的是:在Hadoop中,MapReduce任务最终会执行完成后结束;而在Storm中,Topology任务一旦提交后永远不会结束,除非你显示去停止任务。










 京公网安备 11010802041100号
京公网安备 11010802041100号