作者:mobiledu2502878157 | 来源:互联网 | 2023-06-08 12:21

Hadoop概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
分布式存储
在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,
文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。
分布式计算
把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计
算结果综合起来得到最终的结果。
Hadoop关联项目
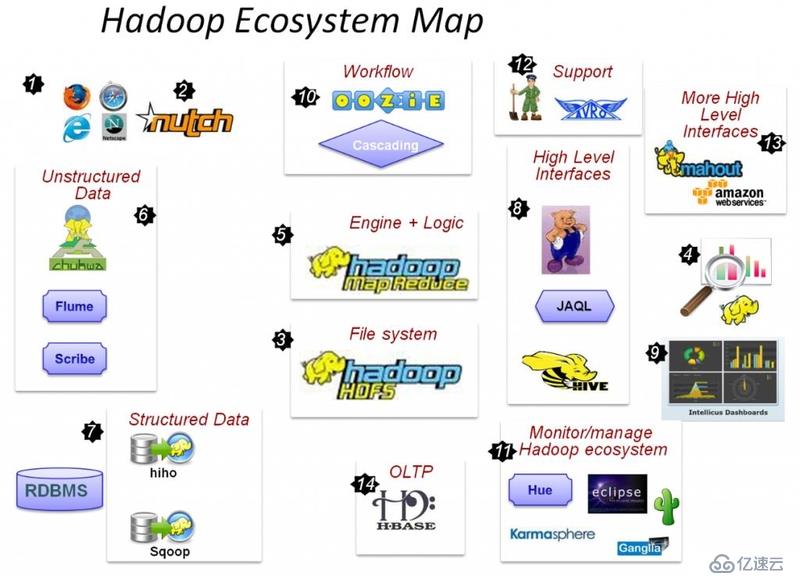
AmbariTM:基于web能够提供资源、监控、管理Hadoop集群的操作工具。
AvroTM:数据序列化系统。
HBaseTM:能支持结构化数据大表存储的可扩展的、分布式的数据库。
HiveTM:能够支持数据的汇总和临时查询的数据仓库基础框架。
MahoutTM:一个可扩展的机器学习和数据挖掘库。
PigTM:高级数据流语言和并行计算执行框架
SparkTM:一个快速和通用的计算Hadoop数据引擎。
TezTM:一个通用的数据流编程框架。
ZooKeeperTM:一个分布式应用的高性能协调的服务。
Hadoop版本
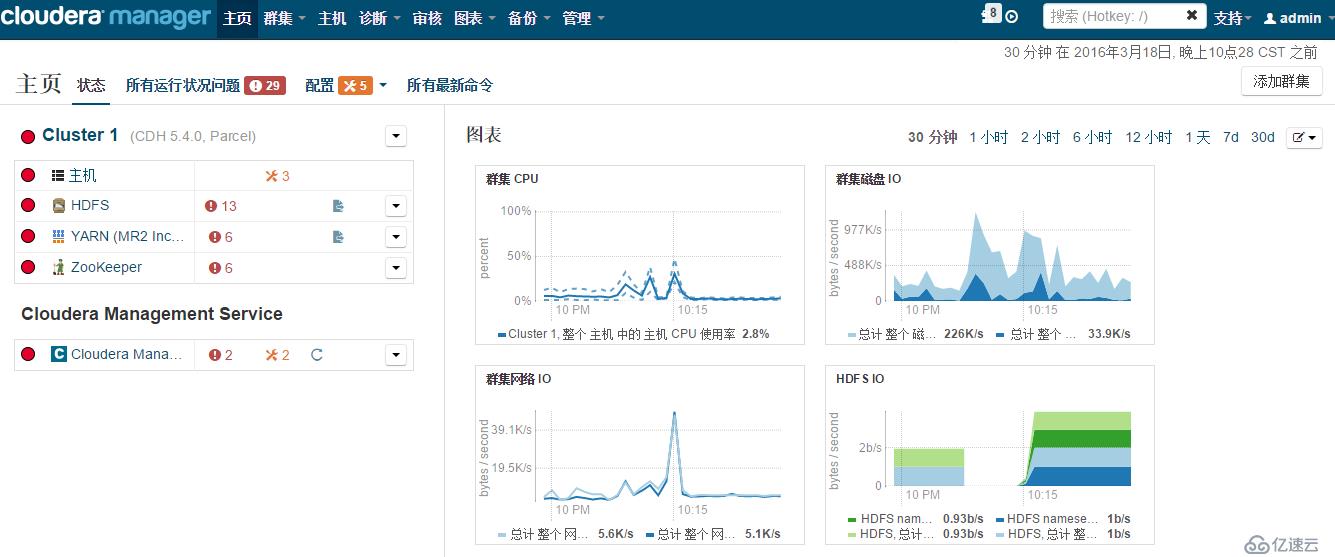
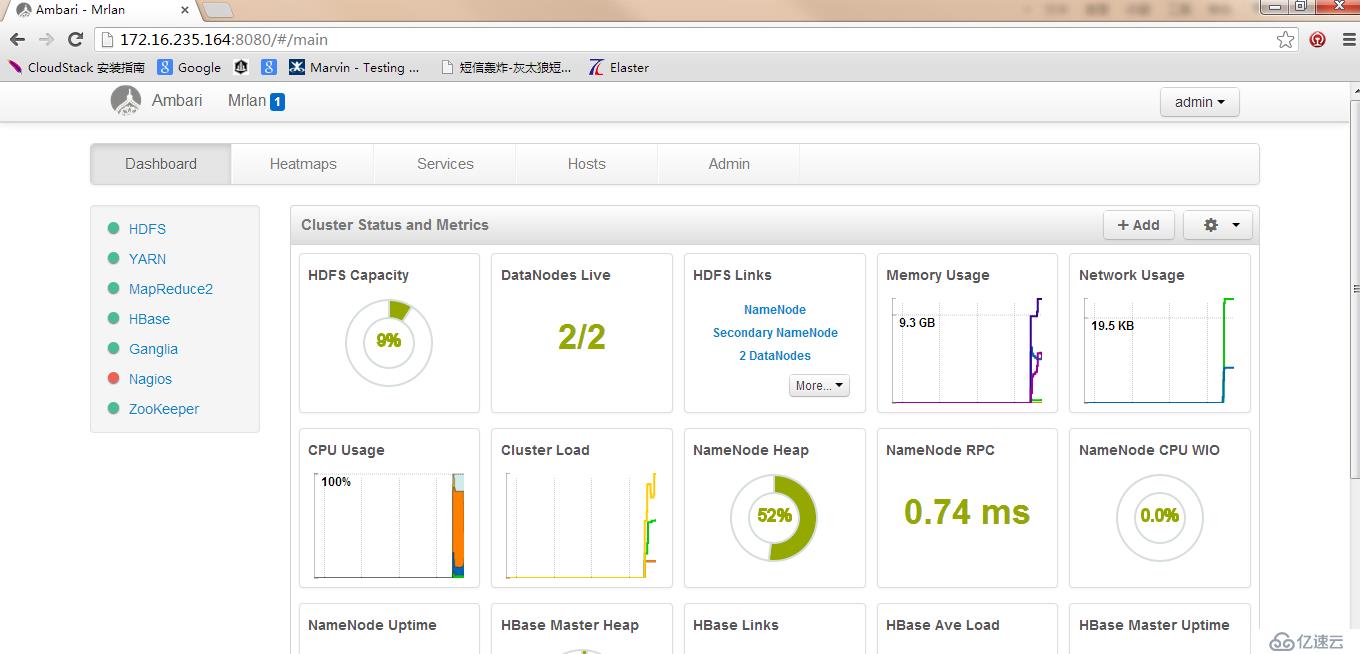
Hadoop的版本大致分为以下:
Apache
官方版本
Cloudera(CDH)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些补丁。推荐使用。
HortonWorks(HDP)
基于Apache的版本进行了集成。
MapR
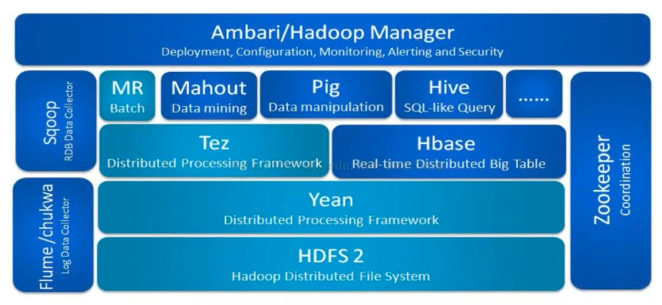
Hadoop模块构成
Hadoop2包括4个模块
Hadoop Common
The common utilities that support the other Hadoop modules.
Hadoop Distributed File System(HDFSTM)
A distributed file system that provides high-throughput access to application data.
Hadoop Yarn
A framework for job scheduling and cluster resource management.
Hadoop MapReduce
A YARN-based system for parallel processing of large data sets.
Hadoop1和Hadoop2简介
Hadoop1
HDFS:Hadoop Distributed File System 分布式文件系统
MapReduce:分布式计算模型
Hadoop2
HDFS2: Hadoop Distributed File System 分布式文件系统
Yarn:资源管理平台,在上面运行分布式计算,典型的计算模型有
MapReduce、Storm、Spark等。

详细可参考http://hadoop.apache.org











 京公网安备 11010802041100号
京公网安备 11010802041100号