数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
数据仓库是出于分析报告和决策支持目的而创建的,为需要业务智能的企业,提供指导业务流程改进、监控时间、成本、质量以及控制。
1)技术选型
2)流程设计
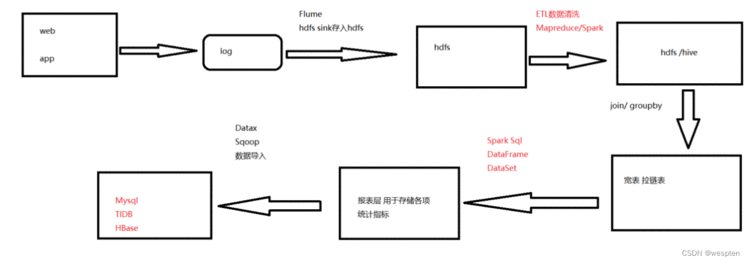
框架版本选型:
如何选择Apache/CDH/HDP版本?
Apache∶运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)。
CDH∶国内使用最多的版本,但CM不开源,但其实对中、小公司使用来说没有影响(建议使用)。









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 