▪ 文档建模:包括内容提取、停用词去除、词频统计、文档频率统计
▪ 命名实体识别
▪ 分布式检索,即输入一个单词,返回包含该单词的所有文档
▪ 高级检索,即在分布式检索的基础上添加正则表达式检索功能
▪ 分类检索,即在分布式检索的基础上对其得到的结果进行聚类,便于用户浏览查看
Ubuntu16.04
Hadoop2.10.0
Python3.5.2
alembic==0.9.8
click==6.7
Flask==0.12.2
Flask-Migrate==2.1.1
Flask-Script==2.0.6
Flask-SQLAlchemy==2.3.2
Flask-WTF==0.14.2
itsdangerous==0.24
Jinja2==2.10
Mako==1.0.7
MarkupSafe==1.0
PyMySQL==0.8.0
python-dateutil==2.6.1
python-editor==1.0.3
six==1.11.0
SQLAlchemy==1.2.4
Werkzeug==0.14.1
WTForms==2.1
jieba==0.42.1
spacy==2.2.0
hdfs==2.5.8
Java1.8.0_181
mysql
以上库均在vs.code的命令行中输入 pip install -r requirements.txt -i
https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host
pypi.tuna.tsinghua.edu.cn 即可一键安装
以及hadoop所需的相对应的环境
Firefox浏览器
运行方式:将sql文件导入mysql,进入travel文件夹,输入命令:python manage.py runserver
可视化界面展示
1、首页

图4.1.1 Twitter展示的首页
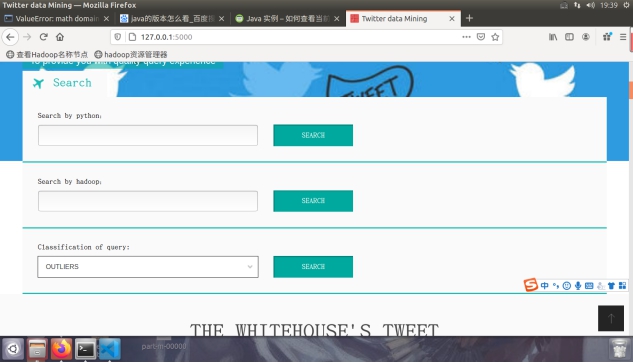
图4.1.2 三种搜索引擎(分别对应了Python检索本地的倒排索引,hadoop进行分布式正则匹配,分类检索)
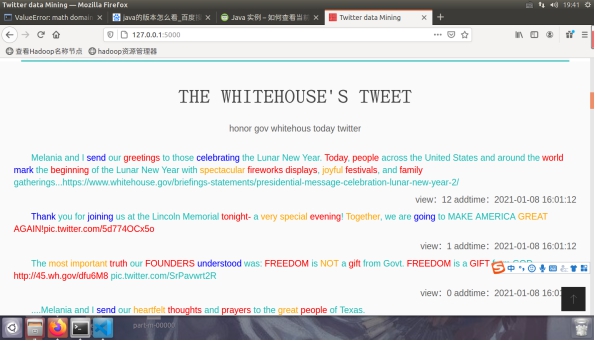
图4.1.3分类展示
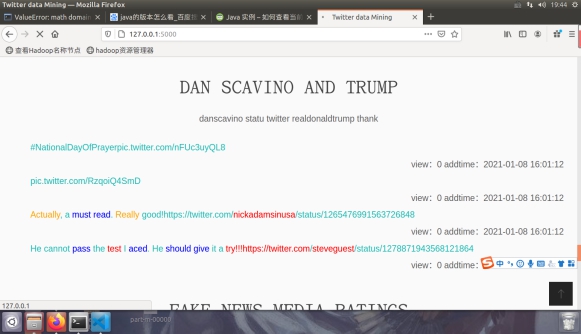
图4.1.4另一个类别,总计有十个类别

图4.1.5尾页
2.查询框
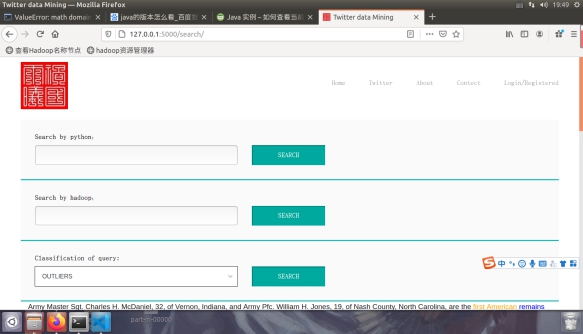
图4.2.1检索页弹框
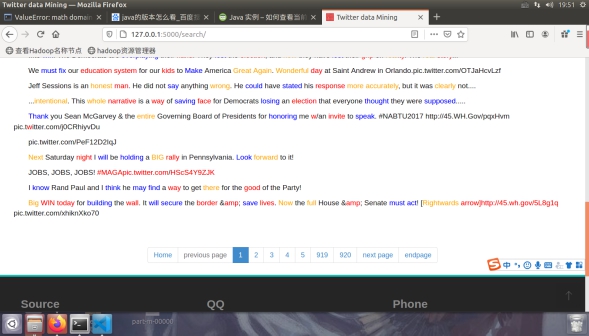
图4.2.2 默认展示条目数位920*20=1840条(全部为1836条Twitter)
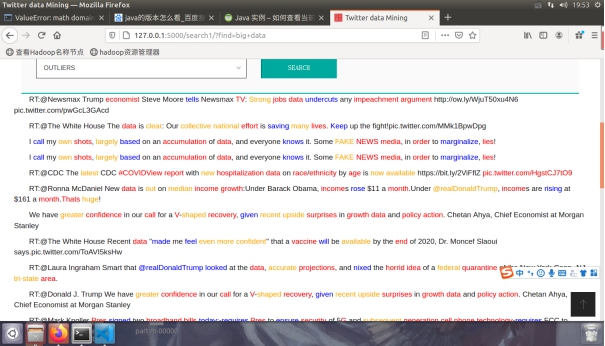
图4.2.3 使用Python访问倒排索引检索big data
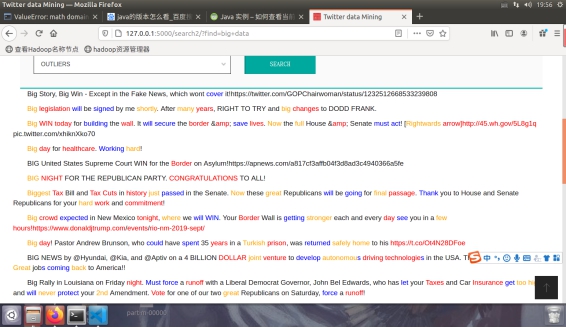
图4.2.4 hadoop分布式检索检索big data
图4.2.5 hadoop分布式检索检索big data的后台生成日志
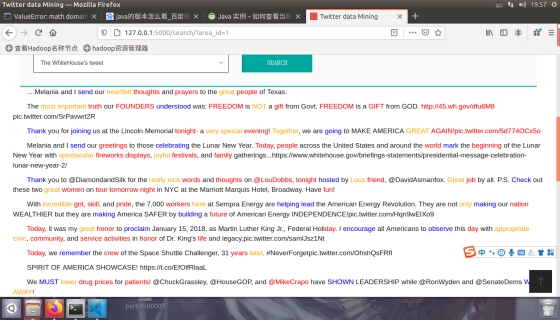
图4.2.6 分类检索结果
3.数据呈现
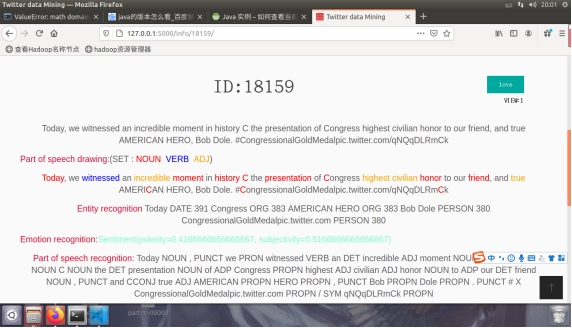
图4.3.1 具体的结果展示
4.其他功能
图4.4.1 用户登录与管理员后台管理
其他功能不是重点后面也不会涉及,还包括一些基本的的收藏功能,数据的增删改查,数据加密功能,登陆ip记录,操作日志记录等。
▪项目简述
可视化界面主要是通过Python的flask框架做的,数据主要存在mysql中,mysql是可以做成分布式的,只需要连接局域网通过访问不同的端口就好,及修改下图的localhost(这个默认是127.0.0.1)

图5.1.1 mysql连接
打开Travel的文件在命令行里输入python manage.py runserver即可出现网页

图5.1.1 项目入口
点击http:// 127.0.0.1: 5000/即可访问网页(后台的入口http:// 127.0.0.1: 5000/admin)
基本思路:
这是最开始的一些思路,算是我整个大作业的指导思想,一些在实际的操作中进行了一定的合并处理;
分词(stopword清洗,分词原理空格)
(偏移,文章)->(词,偏移)->(词,词频度+(文件数+偏移+出现数))+总词数+总文档数)
(偏移,文章)->(偏移,词)->(偏移,总词数+(词+频度))
tf(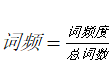
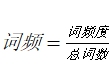 )
)
(偏移,总词数+(词+频度))->(偏移,(词+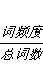
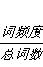 ))
))
idf(逆文档频率=
 )
)
(偏移,词+词频度+(文件数+偏移+出现数))->(词,n)->(词,
 )
)
tf-idf建模(导入idf用’,‘分词)
(偏移,(词+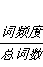
 ))->(null,(
))->(null,(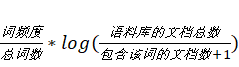
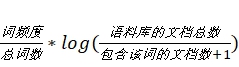 ))
))
kmeans
向量->(向量+簇)
knn整数(需要kmeans的结果)
向量->(向量+簇)
倒排索引(不清洗)
(偏移,文章)->(词,偏移)->(词,(n+偏移))
▪ 文档建模_内容提取:
这个主要是使用python的spacy库做词性的提取,用textblob库做词干提取,首先用并行化脚本跑出词性加标签,并用textblob库的词干提取制作隐射关系写到隐射表里,并且将所有的命名实体识别的内容写到文件里,并用其自带的情感分析库计算出对应的情感分析而后存档,就形成了现在的文章,例如;
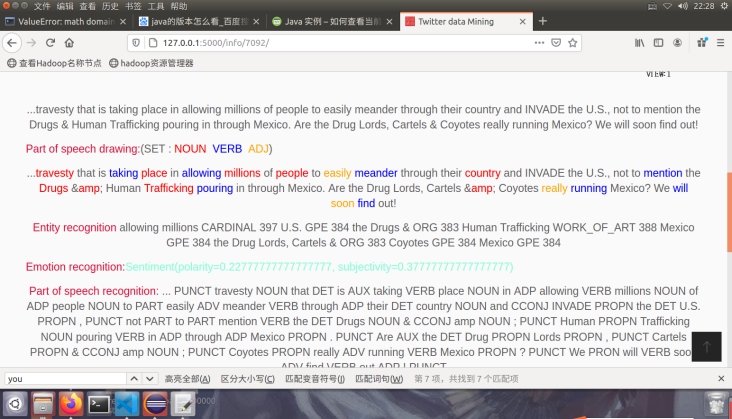
图5.2.1内容展示
ID:7092//行号
view:1//浏览量,用代码实现每次访问加一
...travesty that is taking place in allowing millions of people to easily meander through their country and INVADE the U.S., not to mention the Drugs & Human Trafficking pouring in through Mexico. Are the Drug Lords, Cartels & Coyotes really running Mexico? We will soon find out!原文
Part of speech drawing:(SET : NOUN VERB ADJ)//上色将名词转化为红色,将动词转化为蓝色,将形容词转化为蓝色
...travesty that is taking place in allowing millions of people to easily meander through their country and INVADE the U.S., not to mention the Drugs & Human Trafficking pouring in through Mexico. Are the Drug Lords, Cartels & Coyotes really running Mexico? We will soon find out!//颜色无法复制
Entity recognition allowing millions CARDINAL 397 U.S. GPE 384 the Drugs & ORG 383 Human Trafficking WORK_OF_ART 388 Mexico GPE 384 the Drug Lords, Cartels & ORG 383 Coyotes GPE 384 Mexico GPE 384//命名实体识别的结果
Emotion recognition:Sentiment(polarity=0.22777777777777777, subjectivity=0.37777777777777777)//情感分析polarity极性 subjectivity主观性
Part of speech recognition: ... PUNCT travesty NOUN that DET is AUX taking VERB place NOUN in ADP allowing VERB millions NOUN of ADP people NOUN to PART easily ADV meander VERB through ADP their DET country NOUN and CCONJ INVADE PROPN the DET U.S. PROPN , PUNCT not PART to PART mention VERB the DET Drugs NOUN & CCONJ amp NOUN ; PUNCT Human PROPN Trafficking NOUN pouring VERB in ADP through ADP Mexico PROPN . PUNCT Are AUX the DET Drug PROPN Lords PROPN , PUNCT Cartels PROPN & CCONJ amp NOUN ; PUNCT Coyotes PROPN really ADV running VERB Mexico PROPN ? PUNCT We PRON will VERB soon ADV find VERB out ADP ! PUNCT//词性识别
Find IP:NULL//ip查找
▪ 文档建模_停用词去除:
停用词直接使用教员给的停用词词典,在setup中读取分布式缓存中上传的文件,而后构建集合用contains判断是否包含目标单词,如果不包含则生成键值对,分布式缓存的基本代码为:
DistributedCache.addCacheFile(stopword.toUri(), conf);
stopwords = *new* TreeSet
Configuration cOnf= context.getConfiguration();
localFiles = DistributedCache.getLocalCacheFiles(conf);
即可完成对停用词的提取
▪ 文档建模_词频统计:
直接使用传统的wordcount代码,生成wordcount的结果,不过多加了一步,就是在setup中读取词干映射表,生成hashmap,在map里当读到的单词在hashmap里存在的时候,才输出单词的词干,即可完成相应的词频统计。(这个主要是为了相应的词向量的构建)具体的流程如下:(偏移量,文本)->(词干,1)-> (词干,frequence)
注意到这里不需要进行低频词过滤,因为可能某个低频词在后续的计算中会有更高的idf,至此wordcount执行完毕。
▪ 文档建模_频率统计:
修改传统的wordcount代码,在setup中读取词干映射表,生成hashmap,在map里当读到的单词在hashmap里存在的时候,才输出单词的词干,和文本的id号可完成相应的词频统计。(这个主要是为了相应的词向量的构建)具体的流程如下:(偏移量,文本)->(词干,id)->( 词干,sum)
因为只需要统计出现在了多少个id,因此构造集合hashset,然后读取集合的长度而后用 计算出对应的idf
计算出对应的idf
▪ 文档建模_词向量构建:
最开始我统计了全部的词作为词向量,得到了一个1万5千多的词向量,这个聚类的时长超出了我的想象,于是我采用了教员的建议,只生成形容词,动词,形容词的词向量,并且我在其中又加了一些词干提取,进一步减少了向量的长度,最后的总长度为5000多,每个向量值的计算方案为:(偏移,(词+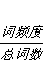
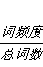 ))->(null,(
))->(null,(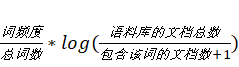
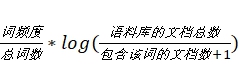 ))****完成词向量的构建
))****完成词向量的构建
▪ 分布式检索:输入一个句子,返回包括该句子中单词的所有文档
Python的分布式检索是基于倒排索引和tf-idf进行查询和排序的搜索引擎,搜索引擎采用的是网上BM25算法
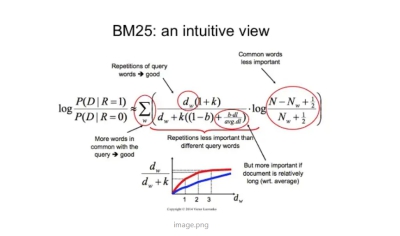
图5.2.2 BM25算法
BM25算法通过加入文档权值和查询权值,拓展了二元独立模型的得分函数。这种拓展是基于概率论和实验验证的,并不是一个正式的模型。BM25模型在二元独立模型的基础上,考虑了单词在查询中的权值以及单词在文档中的权值,拟合综合上述考虑的公式,并通过实验引入经验参数。
BM25的原始公式为: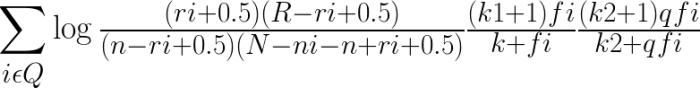
图5.2.3 BM25算法公式
log后有三部分组成,其中,第一部分是二元独立模型的计算得分
具体的初始参数如下所示
doc_encoding = utf-8
stop_words_path = engine/stop_words.txt
stop_words_encoding = utf-8
idf_path = engine/idf.txt
k1 = 1.5
b = 0.75
n = 788
avg_l = 358.19162436548226
hot_k1 = 1.0
hot_k2 = 1.0
这些参数都是基于网上得到的参考值具体的实现过程如下

图5.2.4 BM25算法实现
构建倒排索引使用hadoop进行构建,而后导入数据库
具体的构建方法如下:
读入推特文档,在mapper里设置intwritable变量累加得到twitter的编号作为id,然后将value用空格分开,将分开的词当做键,将文本的id加空格加上列表的序号作为值,在reducer里直接将值用“\n”分割开即可,同时用int型变量计数,插在最后,至此倒排索引构建完毕
(偏移量,文本)->(单词,id+” ”+词位置)-> (单词,{id+” ”+词位置}+”\t”+总数)
在界面中输入的数据经过空格分词为列表,而后放入bm25算法中求解运算,bm25算法访问倒排索引和初始文件参数进行公式计算,最后累加作为该id号的最后得分,而后按得分从高到低每20个一组进行分页展示即可,至此倒排索引检索单词完毕,我们来看看效果,搜索someone like you

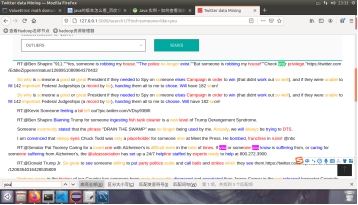
图5.2.5 检索关键字someone like you
我们可以看到url里的关键字信息已经改为someone+like+you,可以清楚的看到这种方法必须要出现确定的单词才行。这里的倒排索引还有改进的空间,就是将空格分词后加入词根转换,就可以增大搜索范围提高搜索精度
▪ 高级检索:分布式检索的基础上添加正则表达式检索功能
需要进行正则匹配,如果只是在本地调用文件正则匹配就不能叫做分布式检索,我想到的是调用hadoop写的正则匹配搜索引擎,因为我的前后台是通过python写的,而我的电脑上又没有相应python版hadoop接口,这里我采用的方法是用Python调用hadoop写好的封装后的搜索引擎。
先分析搜索引擎,搜索引擎采用硬编码的方式将输入输出路径写入代码,同时写入自动删除输出路径的代码,这样就可以做到多次搜索而不用删除文件输出的文件夹
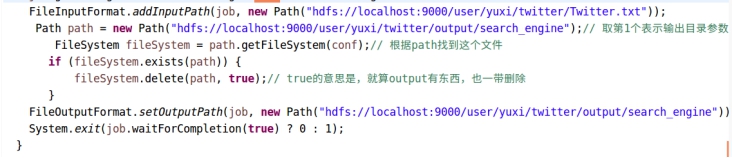
图5.2.6 删除文件路径
我们常见的输入一句话是采用空格割开,而在java的输入中空格默认是分开两个参数的分隔符,因此我们需要完成将多个初始的参数拼接成一个长的字符串,并定义该字符串为全局参数,在map中的setup读取


图5.2.7 检索关键字someone like you
我们在setup中取出该字符串,然后通过空格将其分开,而后在map中匹配所有的单词,正则匹配的方式是:String pattern =find[i].toLowerCase()+".*";
即必须头相同后面可变,这样就可以主要匹配到该单词的变形式子了。具体的键值对设计为(偏移量,文本)->(id,出现位置)-> (id,价值),需要注意到因为采用了正则匹配,所以传统的bm25已经不再适用,因为该算法需要确切单词的tf值,而正则匹配有可能会导致一个单词匹配到多个pattern,例如interrest会和I,in,rest等词相匹配,所以我们需要重新定义一个热度的算法。
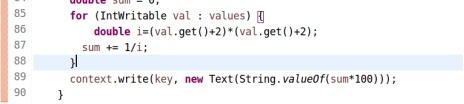
图5.2.8 热度算法
这是我自定义的热度计算排名算法,基于的是y=1/x^2从1积分到无穷得到的是1,而且x越小,即越接近文章头就权值越大,但是这个需要去重,所以我重写了combiner,建立一个hashset来去重,然后在reduce里计算热度
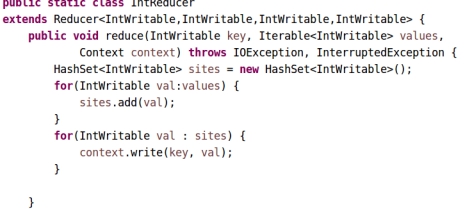
图5.2.9 hashset去重
计算完热度输出每个id号对应的热度,然后再用Python调用,这种搜索方式没有上一种精确,且速度更慢但是搜到的范围会打的多。Python具体的调用方案是先将这个搜索引擎打成jar包,把他放在某个位置,而后调用os,让其运行

图5.2.10 调用jar包
这句话的意思是在terminal上运行hadoop jar /home/hadoop/eclipse-workspace-yuxi/engine.jar search_engine/search_engine XXXX
调用成功的标志是输出日志信息
图5.2.11 日志信息
我们可以看到现在已经使可以成功调用了,但是生成的文件还在hdfs里我们无法查看,需要建立一个连接去访问生成的文件。这里调用了python库hdfs

图5.2.12 查看hdfs文件
先是用client与我的端口建立连接,而后查询这个文件夹是否生成了,这一步很关键,因为我的虚拟机经常报内存不足的问题,一旦报错那么下一步读文件就会报错,导致整个网站停止服务,因而需要确定这次搜索是否完成,以增大服务器的容错率
图5.2.13 报错
图5.2.14 运行成功
▪ 分类检索:对twitter进行聚类,便于用户浏览查看
网上虽然有一些对于如何确定k值的计算方法,但是过于复杂且计算量巨大,对于我这个聚类10次九次内存分配不足的虚拟机来说就不奢求了,这个k值我是经过khcode软件进行处理后感觉当k=10 的时候结果应该是不错的,但是我并不知道khcode背后的机理,所以只是将其作为一个指导的一个方法,接下来就是求解。我们采用的是kmeans聚类,聚类簇为10个中心,对于后续可能会生成的新的加入文件,我写了对应的knn进行分类,这样就可以确保当有新的文件进来时,可以保证其分类内容的不缺失
首先看kmeans算法,我们将初始的词向量输入进去,先随机的选择10个向量作为类的中心,注意到我们这里用的是余弦距离,这是因为我们在研究文本时,对象的特征维度往往很高,余弦相似度在高维情况下依然褒词相同时为1,正交时为0,相反时未-1的特性,而欧氏距离的数值则受维度的影响,范围不确定,并且含义也比较模糊。
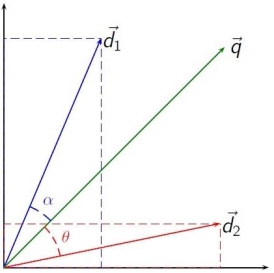
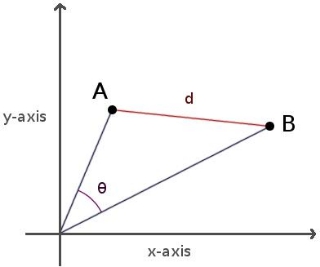
图5.2.15 余弦距离
所以我们就选择余弦距离,而不是欧氏距离。同时选择欧式距离还有一个好处就是,中心节点可以作为整个文本簇的中心,以此为目标生成文本摘要,欧氏距离具体的计算过程如下
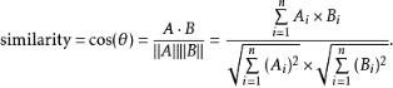
图5.2.15 余弦距离公式
在hadoop中的具体计算方法为:

图5.2.16 余弦距离计算
实际上需要先对文本的余弦向量进行归一化否则在聚类的时候过于长的词向量会被赋予更高的权值,这违反了我们每个文本等价的原则,所以需要让向量的长度单位化:
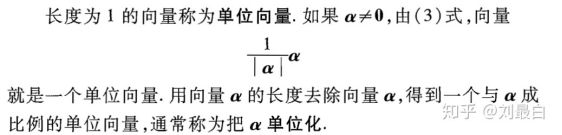
图5.2.17 向量单位化
在hadoop的具体体现如下;
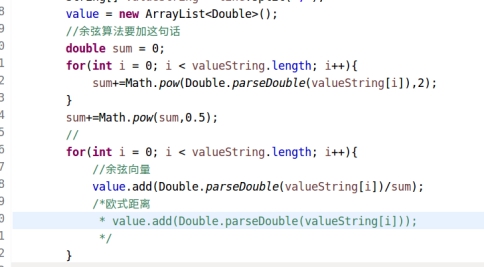
图5.2.18 向量单位化代码
聚类的方法是将每次生成的聚类中心输出出来直到循环到所需要的次数,当循环停止后按顺序输出所有向量的对应的标签
图5.2.19 聚类中心代码
聚完类后,我们还需要重新的定义类名,这里注意一个细节,因为采用的是余弦距离,每个维度是相互独立的,所以余弦的中心可以近似当做是整个类的一个词向量,我们只需要读取这些词向量的值,在map的setup里读取对应的向量,而后选择最高的几个值所对应的向量单词就可以生成我们所需的关键词,生成的关键词如下:
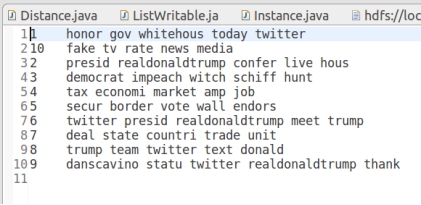
图5.2.20摘要生成信息

图5.2.21摘要翻译
从分类的关键词的提取上可以近似的看出分类的效果还算不错,但是有一些并没有分的太清楚,有很多相似的类是可以合并的,同时因为词向量的构建原因,有一些是无法生成词向量的即0向量,我们只能将他们单独自成一类
The WhiteHouse's tweet 白宫的推特
President Donald Trump live 唐纳德·特朗普总统现场直播
Democrats impeach 民主党人弹劾
The market situation 市场情况
Border security 边境安全
President Trump's meeting 特朗普总统的会议
Countries trade 国家贸易
Twitter President Twitter总统
Dan Scavino and Trump 丹·斯卡维诺和特朗普
Fake news media ratings 虚假新闻媒体收视率
OUTLIERS 离群值
Scavino是白宫社交媒体主管,同时也是美国总统特朗普的社交网络助理
OUTLIERS是一些无法构建词向量的句子,我们把它归为离群点,即词向量长度为0的点,这些点无法带入kmeans计算,因为他们无法进行标准化

图5.2.22离群点
对于新的数据想要加入这个系统,只需要进行tf-idf求得词向量的值而后放入即可,knn采用的也是余弦距离,来保证归类的同一性,具体的距离计算方式如下:

图5.2.23余弦距离计算公式
最后knn算法会输出各个文章所对应的类别编号

图5.2.24 knn输出结果
完成分类
最后的搜索流程是在搜索框里选择对应的类名,服务器会按照id号返回所有的twitter信息,前端调用分页代码,每20个分为一页,排序按照id号升序
图5.2.25摘要翻译
▪ 本地检索:使用sql语句检索
Sql语句自带了正则匹配的即select* from table where content like 正则语句;这种方案实现起来只需要一句代码,相当简单。但是时间代价过大,其检索的时间甚至比在hadoop中检索还要慢,因而我抛弃了这种查询方式,没有在项目中体现。
▪ 域名识别
作为网络安全的学生,我发现推特中含有很多的域名信息,于是我写了一个正则匹配来匹配出所有的顶级域名;
Pattern p = Pattern.compile("(?i)^https?










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有