Flink介绍:
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
2015年升级为Apache的顶级项目,然后突然爆发,之后被阿里收购。
基本上国内说得出名字的大厂都在用flink。

Flink特点: 1,事件驱动:
根据数据的到来触发一系列的计算,输出等。
2,流处理和批处理
批处理的特点就是 有界,持久,量大,非常适合做离线计算
流处理的特点就是 无界,实时,无需针对整个数据集执行操作,而是对传输过来的
每个数据项执行操作,一般用户实时计算
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
Flink分层api
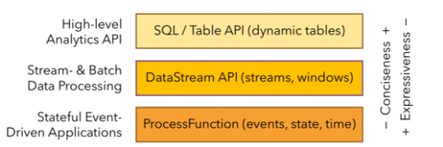
分别是ProcessFunction,DataStream Api,SQL/Table Api,
最底层的是ProcessFunction,功能最强大,但也最复杂。
一般我们操作的都是DataStream这一层来处理数据,实在不行就嵌入ProcessFunction层。
DataStream Api提供了很多模块因子,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)
像阿里Flink的分支 blink 就是往这方面发展,Blink比起Flink的优势就是对SQL语法的更完善的支持以及执行SQL的性能提升。
未来以后可能大量的开发就落在Table API 这层咯。
支持exactly-once语义
这个特性就是确保一条数据,收并且只能收到一次。这个就能保证结果的准确性。
Flink架构组成
Flink其实跟flume差不多,主要是是3部分,flume是 source -> channal -> sink
flink 也是 source -> operator -> sick
flink通过source 接受数据,source 可以是配多种多样,不过生成上大部分都是用kafka.
因为前面说了,flink是事件驱动型,当source监听kafka的数据后,会向flink的jobManager
提交job,jobManage会根据job等资源优化后就会分配Taskmanager,Taskmanager是真正计算的地方,它会通过一系列的
计算因子,最后将结果返回给jobManage,再返回给flink客户端。

Worker与Slots
每一个worker(TaskManager)是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask。为了控制一个worker能接收多少个task,worker通过task slot来进行控制(一个worker至少有一个task slot)。·
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个subtask将不需要跟来自其他job的subtask竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存。
通过调整task slot的数量,允许用户定义subtask之间如何互相隔离。如果一个TaskManager一个slot,那将意味着每个task group运行在独立的JVM中(该JVM可能是通过一个特定的容器启动的),而一个TaskManager多个slot意味着更多的subtask可以共享同一个JVM。而在同一个JVM进程中的task将共享TCP连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构,因此这减少了每个task的负载。

图 TaskManager与Slot
Task Slot是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置,而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
也就是说,假设一共有3个TaskManager,每一个TaskManager中的分配3个TaskSlot,也就是每个TaskManager可以接收3个task,一共9个TaskSlot,如果我们设置parallelism.default=1,即运行程序默认的并行度为1,9个TaskSlot只用了1个,有8个空闲,因此,设置合适的并行度才能提高效率







 京公网安备 11010802041100号
京公网安备 11010802041100号