说起大数据,估计大家都觉得只听过概念,但是具体是什么东西,怎么定义,没有一个标准的东西.因为在我们的印象中好像很多公司都叫大数据公司,业务形态则有几百种,感觉不是很好理解,所以我建
说起大数据,估计大家都觉得只听过概念,但是具体是什么东西,怎么定义,没有一个标准的东西.
因为在我们的印象中好像很多公司都叫大数据公司,业务形态则有几百种,感觉不是很好理解,所以我建议还是从字面上来理解大数据,在维克托迈尔-舍恩伯格及肯尼斯库克耶编写的《大数据时代》提到了大数据的4个特征:

1.大量
大数据的特征首先就体现为“大”.从先Map3时代,一个小小的MB级别的Map3就可以满足很多人的需求,然而随着时间的推移,存储单位从过去的GB到TB,乃至现在的PB、EB级别。只有数据体量达到了PB级别以上,才能被称为大数据。
1PB等于1024TB,1TB等于1024G,那么1PB等于1024*1024个G的数据。随着信息技术的高速发展,数据开始爆发性增长。社交网络(微博、推特、脸书)、移动网络、各种智能工具,服务工具等,都成为数据的来源。
淘宝网近4亿的会员每天产生的商品交易数据约20TB;脸书约10亿的用户每天产生的日志数据超过300TB。迫切需要智能的算法、强大的数据处理平台和新的数据处理技术,来统计、分析、预测和实时处理如此大规模的数据。
2.高速
就是通过算法对数据的逻辑处理速度非常快,1秒定律,可从各种类型的数据中快速获得高价值的信息,这一点也是和传统的数据挖掘技术有着本质的不同。
大数据的产生非常迅速,主要通过互联网传输。生活中每个人都离不开互联网,也就是说每天个人每天都在向大数据提供大量的资料。并且这些数据是需要及时处理的,因为花费大量资本去存储作用较小的历史数据是非常不划算的,对于一个平台而言,也许保存的数据只有过去几天或者一个月之内,再远的数据就要及时清理,不然代价太大。
基于这种情况,大数据对处理速度有非常严格的要求,服务器中大量的资源都用于处理和计算数据,很多平台都需要做到实时分析。数据无时无刻不在产生,谁的速度更快,谁就有优势。
3.多样
如果只有单一的数据,那么这些数据就没有了价值,比如只有单一的个人数据,或者单一的用户提交数据,这些数据还不能称为大数据。
广泛的数据来源,决定了大数据形式的多样性。比如当前的上网用户中,年龄,学历,爱好,性格等等每个人的特征都不一样,这个也就是大数据的多样性.
当然了如果扩展到全国,那么数据的多样性会更强,每个地区,每个时间段,都会存在各种各样的数据多样性。任何形式的数据都可以产生作用,目前应用最广泛的就是推荐系统,如淘宝,网易云音乐、今日头条等,这些平台都会通过对用户的日志数据进行分析,从而进一步推荐用户喜欢的东西。
日志数据是结构化明显的数据,还有一些数据结构化不明显,例如图片、音频、视频等,这些数据因果关系弱,就需要人工对其进行标注。
在这里我还是要推荐下我自己建的大数据学习交流qq裙:522189307 , 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。
4.价值
这也是大数据的核心特征。据羿戓产品设计所了解,现实世界所产生的数据中,有价值的数据所占比例很小。
相比于传统的小数据,大数据最大的价值在于通过从大量不相关的各种类型的数据中,挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,发现新规律和新知识。
你如果有1PB以上的全国所有20-35年轻人的上网数据的时候,那么它自然就有了商业价值,比如通过分析这些数据,我们就知道这些人的爱好,进而指导产品的发展方向等等。
如果有了全国几百万病人的数据,根据这些数据进行分析就能预测疾病的发生,这些都是大数据的价值。大数据运用之广泛,如运用于农业、金融、医疗等各个领域,从而最终达到改善社会治理、提高生产效率、推进科学研究的效果。

大数据已经成为过去几年中大部分行业的游戏规则,行业领袖,学者和其他知名的利益相关者都同意这一点,随着大数据继续渗透到我们的日常生活中,围绕大数据的炒作正在转向实际使用中的真正价值。
当今的大型企业,内部分工日趋细化,采购、服务、市场、销售、开发、支持、物流、财务、人力等各个环节,无不每时每刻产生着大量的数据。数据的格式也越来越多样化,包括IT系统里存储的结构化、非结构化数据,各样电子文档数据等。与此同时,企业管理者对数据的困惑也与日俱增,这些数据从哪里来?我们能相信这些数据吗?数据之间有什么样的关系?谁能理解这些数据?
零散化存放是数据问题根源
造成上述情况最根本的原因是:数据零散化存放。大型企业在不同发展阶段,会根据业务需求建设很多内部IT支撑系统,比如ERP(企业资源计划)系统、CRM(客户服务管理)系统、财务管理系统等,这些系统的分散建设,数据割裂,造成了数据零散化存放的现状。
基于数据作分析,首先需要数据的聚合,但由于生产系统和数据的离散化,造成了数据标准、数据模型不统一,因而企业最需要做的就是对数据整合和标准化。
大数据治理带来全面解决之道
大数据治理是诸多数据问题的全面解决之道。根据DAMA(国际数据管理协会)的定义,数据治理(DG,Data Governance)是指对数据资产的管理活动行使权力和控制的活动集合(规划、监控和执行)。作为DAMA数据管理职能框架(图1)的10项职能之一,起着指导其他数据管理职能如何执行的作用,它通过制定正确的政策、操作规程,确保以正确的方式对数据和信息进行管理。
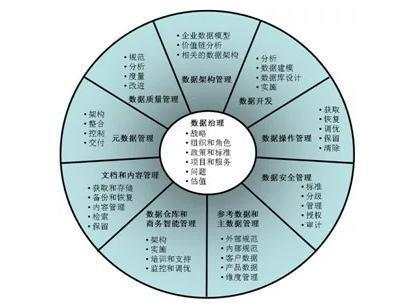
大数据治理,即基于大数据的数据治理。大数据,一般指符合4V特征的数据,包括社交数据、机器数据等,大数据对传统数据治理工作带来很多的扩展,在政策/流程上,大数据治理应覆盖大数据的获取、处理、存储、安全等环节,需要为大数据设置数据管理专员制度;
需考虑大数据与主数据管理能力的集成,需要对大数据做定义,统一主数据标准;在数据生命周期管理各阶段,如数据存储、保留、归档、处置时,要考虑大数据保存时间与存储空间的平衡,大数据量大,因此应识别对业务有关键影响的数据元素,检查和保证数据质量。此外,在隐私方面,应考虑社交数据的隐私保护需求,制定相应政策,还要将大数据治理与企业内外部风险管控需求建立联系。
大数据治理的商业价值
企业只有建立了完整的大数据治理体系,保证数据的质量,才能够真正有效地挖掘企业内部的数据价值,对外提高竞争力。
首先,高质量数据是企业业务创新、管理决策的基础。随着互联网企业对其他各行业的冲击,加剧了市场的竞争,许多企业面临收入增速放缓、利润空间逐步缩小的局面,过去单纯的外延式增长已经难以为继。
因此,必须向外延与内涵相结合的增长方式转变,未来效益的提升很大程度上要依靠企业的内部挖潜实现,这从客观上对企业的创新能力提出了更高的要求,而提升企业内部数据管理的精细化水平,是企业开展业务创新和管理决策的重要基础,能够为企业创造巨大效益。
其次,标准化的数据是优化商业模式、指导生产经营的前提。许多企业的 IT 系统经历了数据量高速膨胀的时期,这些海量的、分散在不同角落的数据导致了数据资源利用的复杂性和管理的高难度,形成了一个个系统竖井。
系统之间的关系、标准化数据从哪里获取都无从知晓,通过数据治理工作,可以对分散在各系统中的数据提供一套统一的数据命名、数据定义、数据类型、赋值规则等的定义基准,通过数据标准化可以防止数据的混乱使用,确保数据的正确性及质量,并可以优化商业模式,指导企业生产经营工作。
最后,多角度、全方位的数据是企业开展市场营销、争夺客户资源的关键。数据已成为企业最核心的隐形财富,谁掌握了准确的数据谁就能获得先机,在当前竞争日益激烈的市场上,企业如何在不同的细分市场构建客户画像、开展精准营销,如何选择竞争策略、进行经营管理决策,都必须基于360度全方位、准确的客户数据加以分析判断才能得出。
明确数据治理责任,建立数据治理组织
数据出了问题,到底是谁的责任?因为数据主要是IT系统产生的,所以一直以来,解决数据问题都被认为是IT部门的职责。
而IT部门也饱受其苦,数据定义和业务规则,业务部门最清楚;
数据录入,业务人员负责;数据使用,业务人员是用户;
数据考核,业务部门有权力……但实际上,要切实解决数据问题,开展数据治理工作,就必须先清楚一点:
数据治理,是业务部门和IT部门共同的职责。
图2是典型的中国式数据治理组织架构,数据治理/管理领导小组设在信息化领导小组之下,可以单设,也可以是信息化领导小组的一个职责,而虚框中的数据治理部门可能是实体部门,也可能是由牵头业务部门和IT部门联合组成的虚拟团队。
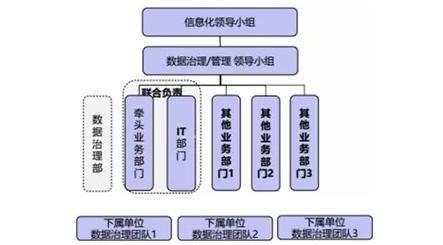
值得一提的是,越来越多的企业开始重视数据治理工作,一些企业高管团队中也产生了一个全新的职位——首席数据官(CDO),是组织内大数据战略的制定者和推动者,负责组织内数据资产的开发和利用,通过数据推动组织业务的创新和发展,通常直接汇报给CEO或CIO。
管理出成效,制度是保障
大数据治理需要管理和制度的有力支撑,可结合企业的现状,制定相应的管理办法、管理流程、认责体系、人员角色和岗位职责等,颁布相关的数据治理的企业规章制度等。
举个例子,在笔者负责过的一个数据治理项目中,为了加强数据保密管理,根据重要程度、公开范围、数据使用频次和数据安全要求,针对数据制定了四个重要级别:极敏感级、敏感级、较敏感级、低敏感级,并根据不同级别实施相应的管理举措,级别越高,数据管理的要求越高。
数据规范:没有规矩,不成方圆
数据规范是指对企业核心数据进行有关存在性、完整性、质量及归档的测量标准,为评估企业数据质量,并且为手动录入、设计数据加载程序、更新信息以及开发应用软件提供的约束性规则,数据规范一般包括数据标准、数据模型、业务规则、元数据、主数据和参考数据。
制定数据标准的目的是为了使业务人员、技术人员在提到同一个指标、名词、术语的时候有一致的含义。数据模型对企业运营过程中涉及的业务概念和逻辑规则进行统一定义。
业务规则是一种权威性原则或指导方针,用来描述业务交互,并建立行动和数据行为结果及完整性的规则。元数据能够帮助增强数据理解,可以架起企业内业务与 IT 部门之间的桥梁。主数据用来描述参与组织业务的人员、地点和事物。参考数据是系统、应用软件、数据库、流程、报告中及交易记录中用来参考的数值集合或分类表。
数据治理活动,理论结合实践
数据治理活动是指为实现数据资产价值的获取、控制、保护、交付以及提升,对数据规范所做的计划、执行和监督工作,一般包括以下活动。
数据架构管理,用于定义企业数据需求,设计实现数据需求的主要蓝图,通常包括数据标准管理、数据模型管理、数据集成架构等;数据质量管理,指通过计划、实施和控制活动,运用质量管理技术度量、评估、改进和保证数据的恰当使用;
元数据管理,指通过计划、实施和控制活动,以实现轻松访问高质量和整合的元数据;数据安全管理,指通过计划、制定并执行数据安全政策和措施,为数据和信息提供适当的认证、授权、访问和审计;参考数据和主数据管理,指通过计划、实施和控制活动,达到保证参考数据与主数据的一致性。
数据治理软件:工欲善其事,必先利其器
目前业界流行的数据治理软件,一般也称为数据资产管理产品、数据治理产品,主要包括的功能组件有元数据管理工具、数据标准管理工具、数据模型管理工具、数据质量管理工具、主数据管理工具、数据安全管理工具等。
利用数据治理软件主要解决企业不同来源数据集成过程中遇到的问题,需要数据治理软件能够为企业提供统一的元数据集成、数据标准管理、数据模型设计、数据质量稽核、数据资产目录、数据分析服务等能力。
基于大数据的人工智能时代的到来,为各行业带来基于数据资产进行业务创新、管理创新的契机,伴随着企业数字化转型过程,越来越多的数据被收集,大数据治理将为企业提供更全面更准确的数据,届时人类的大部分行为将可以被计算和预测,这种对社会成员的行为逻辑、社会事件的发展态势提前作出判断、预测和模拟,将使社会治理模式得到极大变革,从而极可能推动社会治理也由传统的人类精英经验治理向基于大数据的智能化治理转型。









 京公网安备 11010802041100号
京公网安备 11010802041100号