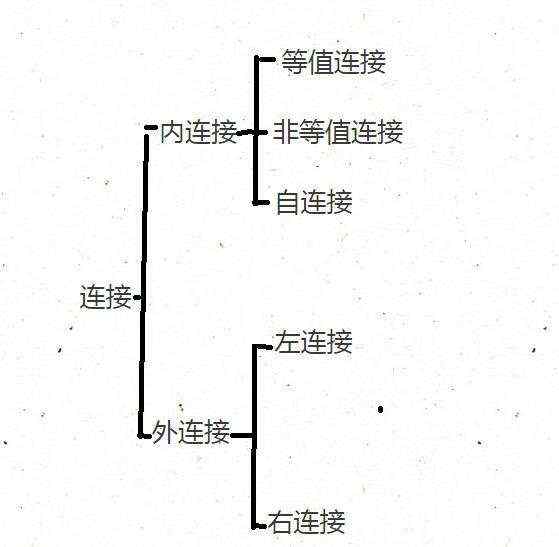
1、 多表查询(连接查询)
之前的一些查询都是在单表上进行的,使用起来比较简单,但是在实际情况中,大多数查询都是几张表联合起来查询的。把所有数据放在同一张表不好吗?当然不好,当把所有的数据都放到同一张表中,那么可想而知,那张表中的数据量得多大,而且其中有些字段的值也相同,都放在一张表会造成数据冗余,浪费存储空间,更重要的是不安全,万一这个表被删除了,那么数据就彻底没有了,会造成很大的损失,所以一般都会把数据放在不同的表中,这个时候可能就得使用外键了。
2、笛卡尔积现象
在进行多表连接时会产生笛卡尔积现象,所谓笛卡尔积现象是指两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X×Y,即第一张表中的每个字段都分别与第二张表中的每个字段相组合 。

这样的结果明显是错误的。
案例:查找EMP表中的员工名字和DEPT表中的部门名称。
mysql> select ename,dname from emp,dept;
+
| ename | dname |
+
| SMITH | ACCOUNTING |
| SMITH | RESEARCH |
| SMITH | SALES |
| SMITH | OPERATIONS |
| ALLEN | ACCOUNTING |
| ALLEN | RESEARCH |
| ALLEN | SALES |
| ALLEN | OPERATIONS |
| WARD | ACCOUNTING |
| WARD | RESEARCH |
| WARD | SALES |
| WARD | OPERATIONS |
| JONES | ACCOUNTING |
| JONES | RESEARCH |
| JONES | SALES |
| JONES | OPERATIONS |
| MARTIN | ACCOUNTING |
| MARTIN | RESEARCH |
| MARTIN | SALES |
| MARTIN | OPERATIONS |
| BLAKE | ACCOUNTING |
| BLAKE | RESEARCH |
| BLAKE | SALES |
| BLAKE | OPERATIONS |
| CLARK | ACCOUNTING |
| CLARK | RESEARCH |
| CLARK | SALES |
| CLARK | OPERATIONS |
| SCOTT | ACCOUNTING |
| SCOTT | RESEARCH |
| SCOTT | SALES |
| SCOTT | OPERATIONS |
| KING | ACCOUNTING |
| KING | RESEARCH |
| KING | SALES |
| KING | OPERATIONS |
| TURNER | ACCOUNTING |
| TURNER | RESEARCH |
| TURNER | SALES |
| TURNER | OPERATIONS |
| ADAMS | ACCOUNTING |
| ADAMS | RESEARCH |
| ADAMS | SALES |
| ADAMS | OPERATIONS |
| JAMES | ACCOUNTING |
| JAMES | RESEARCH |
| JAMES | SALES |
| JAMES | OPERATIONS |
| FORD | ACCOUNTING |
| FORD | RESEARCH |
| FORD | SALES |
| FORD | OPERATIONS |
| MILLER | ACCOUNTING |
| MILLER | RESEARCH |
| MILLER | SALES |
| MILLER | OPERATIONS |
+
56 rows in set
这样就产生了笛卡尔积现象,因为没有指明连接的条件,此时可以使用where限制条件来消除笛卡尔积现象。但是比较的次数不会减少,只是最终显示的结果会减少,索引查询效率没有得到提高,如果想提升可以使用索引等。
mysql> select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno;
+
| ename | dname |
+
| SMITH | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| JONES | RESEARCH |
| MARTIN | SALES |
| BLAKE | SALES |
| CLARK | ACCOUNTING |
| SCOTT | RESEARCH |
| KING | ACCOUNTING |
| TURNER | SALES |
| ADAMS | RESEARCH |
| JAMES | SALES |
| FORD | RESEARCH |
| MILLER | ACCOUNTING |
+
14 rows in set此时就要用到外键的约束了。
3、内连接查询
内连接主要分为两大类等值连接和非等值连接,在这两种连接中又分为隐式连接(SQL92语法)和显示连接(SQL99语法),显示连接一般要是用关键字 inner join on来表明,而隐式连接不用。内连接表与表之间是平等关系,没有需要主次之分,其中等值连接的条件是等量关系,而非等值连接相当于between … and…

具体语法:
1.隐式连接(SQL92语法)
SELECT table_name1.column_name,table_name2.column_nameFROM table_name1,table_name2WHERE table_name1.column_name = table_name2.column_nameGROUP BY column_name;HVING column_name;ORDER BY column_name ASC/DESC
2.显式连接(SQL99语法)
SELECT table_name1.column_name,table_name2.column_nameFROM table_name1inner join table_name2on table_name1.column_name = table_name2.column_name WHERE 表与表的连接条件GROUP BY column_name;HVING column_name;ORDER BY column_name ASC/DESC
3.1 等值连接
等值连接: 连接的条件是等量关系。
案例1:查找EMP表中薪水在2500到3000的员工信息,并显示所属的部门名称。
隐式连接即SQL92语法
mysql> select e.ename, e.sal, d.dname from emp e, dept d where e.deptno=d.deptno and e.sal between 2500 and 3000;
+
| ename | sal | dname |
+
| JONES | 2975 | RESEARCH |
| BLAKE | 2850 | SALES |
| SCOTT | 3000 | RESEARCH |
| FORD | 3000 | RESEARCH |
+
4 rows in set显式连接即SQL99语法,把条件分开,结构更加清晰, inner可以省略,但是带着可读性更好,查询效率更高
mysql> select e.ename, e.sal, d.dname from emp e inner join dept d on e.deptno=d.deptno where e.sal between 2500 and 3000;
+
| ename | sal | dname |
+
| JONES | 2975 | RESEARCH |
| BLAKE | 2850 | SALES |
| SCOTT | 3000 | RESEARCH |
| FORD | 3000 | RESEARCH |
+
4 rows in set
4、外连接查询
外连接表与表之间不平等,有一张主表,一张副表,副表的查询不能影响主表的查询,如果副表没有匹配的数据自动变成NULL
主要分为左外连接、右外连接、全连接。
4.1 左外连接(left outer join)
1.左外连接(left outer join): (任何一个左外连接都有一个右外连接) ,此时主表是左边的表即在from语句后的表,副表为join后面的表,前面的表起决定性作用。

具体语法:
SELECT table_name1.column_name,table_name2.column_nameFROM table_name1left outer join table_name2on table_name1.column_name = table_name2.column_name WHERE 条件通俗语法表示:select 查询字段 from 表1 left【outer】join 表2 on 连接条件 where 条件
案例1:显示员工信息,并显示所属的部门名称。
mysql> select e.ename, e.sal, d.dname from dept d left outer join emp e on e.deptno=d.deptno;
+
| ename | sal | dname |
+
| SMITH | 800 | RESEARCH |
| ALLEN | 1600 | SALES |
| WARD | 1250 | SALES |
| JONES | 2975 | RESEARCH |
| MARTIN | 1250 | SALES |
| BLAKE | 2850 | SALES |
| CLARK | 2450 | ACCOUNTING |
| SCOTT | 3000 | RESEARCH |
| KING | 5000 | ACCOUNTING |
| TURNER | 1500 | SALES |
| ADAMS | 1100 | RESEARCH |
| JAMES | 950 | SALES |
| FORD | 3000 | RESEARCH |
| MILLER | 1300 | ACCOUNTING |
| NULL | NULL | OPERATIONS |
+
15 rows in set
案例2:显示员工信息,并显示所属的部门名称。
mysql> select e.ename, e.sal, d.dname from emp e right outer join dept d on e.deptno=d.deptno;
+
| ename | sal | dname |
+
| SMITH | 800 | RESEARCH |
| ALLEN | 1600 | SALES |
| WARD | 1250 | SALES |
| JONES | 2975 | RESEARCH |
| MARTIN | 1250 | SALES |
| BLAKE | 2850 | SALES |
| CLARK | 2450 | ACCOUNTING |
| SCOTT | 3000 | RESEARCH |
| KING | 5000 | ACCOUNTING |
| TURNER | 1500 | SALES |
| ADAMS | 1100 | RESEARCH |
| JAMES | 950 | SALES |
| FORD | 3000 | RESEARCH |
| MILLER | 1300 | ACCOUNTING |
| NULL | NULL | OPERATIONS |
+
15 rows in set
4.2 右外连接(right outer join)
2.右外连接(right out join):(任何一个右外连接都有一个左外连接),此时主表是有边的表即在join语句后的表,副表为from后面的表,join后的表起决定性作用。

具体语法:
SELECT table_name1.column_name,table_name2.column_nameFROM table_name1right outer join table_name2on table_name1.column_name = table_name2.column_name WHERE 条件通俗语法表示:select 查询字段 from 表1 right【outer】join 表2 on 连接条件 where 条件
注: 区分左外连接还是右外连接主要看的是起主要作用的那张表在那边,也就是在左边还是右边
4.3 全连接(full outer join)
3.全连接(full outer join): 即有左表又有右表,左边不能影响右表的查询,右边不能影响左表的查询,一般不会使用。
SELECT table_name1.column_name,table_name2.column_nameFROM table_name1full outer join table_name2on table_name1.column_name = table_name2.column_name WHERE 条件通俗语法表示:select 查询字段 from 表1 right【outer】join 表2 on 连接条件 where 条件
5 、自然连接
自连接: 一张表看成两张表,相当于等值连接。
mysql> select e1.ename '第一张表',e2.ename '第二张表' from emp e1 ,emp e2 where e1.ename = e2.ename;
+
| 第一张表 | 第二张表 |
+
| SMITH | SMITH |
| ALLEN | ALLEN |
| WARD | WARD |
| JONES | JONES |
| MARTIN | MARTIN |
| BLAKE | BLAKE |
| CLARK | CLARK |
| SCOTT | SCOTT |
| KING | KING |
| TURNER | TURNER |
| ADAMS | ADAMS |
| JAMES | JAMES |
| FORD | FORD |
| MILLER | MILLER |
+
14 rows in set
6、Union合并查询
union操作符用于连接两个以上的 DQL语句的查询结果组合到一个结果集合中。多个 selcet语句会删除重复的数据。
集体语法:
SELECT column_name
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT] DISTINCT 可选 删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据.ALL: 可选,返回所有结果集,包含重复数据。
SELECT column_name
FROM tables
[WHERE conditions];
案例1:在EMP表中查询job为MANAGER和包含SALESMAN的员工,返回员工的名字和薪资。
原始sql语句:
mysql> select ename,sal from emp where job in('MANAGER','SALESMAN');
+
| ename | sal |
+
| ALLEN | 1600 |
| WARD | 1250 |
| JONES | 2975 |
| MARTIN | 1250 |
| BLAKE | 2850 |
| CLARK | 2450 |
| TURNER | 1500 |
+
7 rows in set使用union
mysql> select ename,sal from emp where job='MANAGER'
union all
select ename,sal from emp where job='SALESMAN';+
| ename | sal |
+
| JONES | 2975 |
| BLAKE | 2850 |
| CLARK | 2450 |
| ALLEN | 1600 |
| WARD | 1250 |
| MARTIN | 1250 |
| TURNER | 1500 |
+
7 rows in set
在使用union连接两个表时,两个表中的字段必须一样,否则会报错
mysql> select * from emp union select * from dept;
1222 - The used SELECT statements have a different number of columns
------------------------------------------------------------------------------END-----------------------------------------------------------------------------
------------------------------------------------------------>>>>>>>>>>加载完成<<<<<<<<<------------------------------------------------------



 京公网安备 11010802041100号
京公网安备 11010802041100号