作者:小程序员 | 来源:互联网 | 2023-10-12 14:21
如何用花盆摆放成国庆字,并且包围这两个字。 在DBSCAN中衡量密度主要使用的指标:半径、最少样本量 算法原理*直接密度可达如果一个点在核心对象的半径区域
如何用花盆摆放成国庆字,并且包围这两个字。
在DBSCAN中衡量密度主要使用的指标:半径、最少样本量
算法原理
*直接密度可达
如果一个点在核心对象的半径区域内,那么这个点和核心对象称为直接密度可达,比如A和B,B和C等

图1
*密度可达
如果有一系列点,都满足上一个点到这个点都是密度直达,那么这个系列中不相邻的点就称为密度可达,比如上图1中A和D。另外下图2也是有解释的
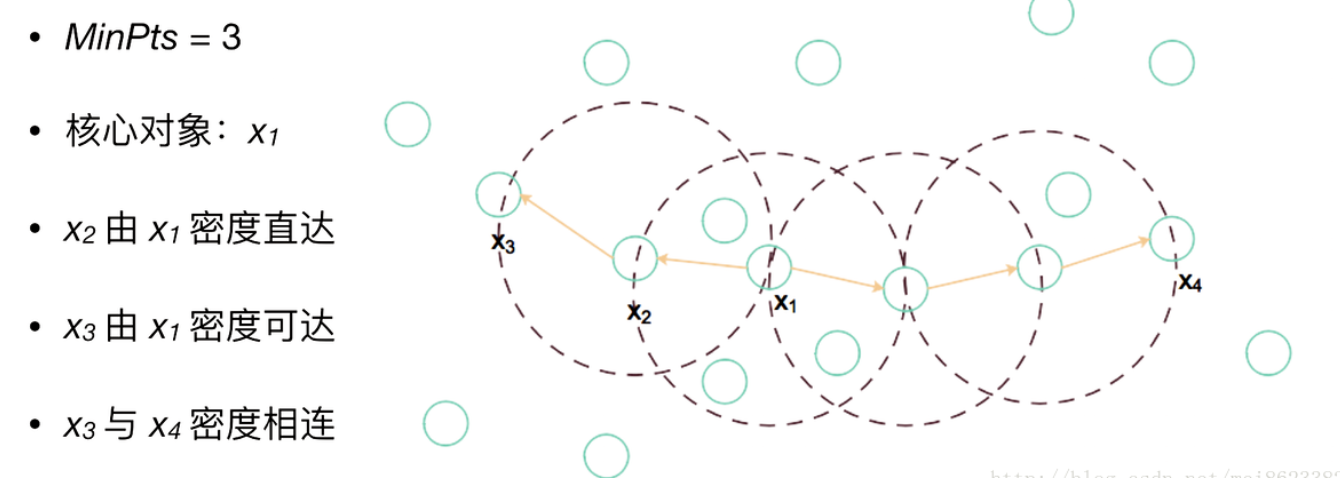
图2
*密度相连
如果通过一个核心对象出发,得到两个密度可达的点,那么这两个点称为密度相连,比如图1中E和F
经过初始化后,从整个样本集中去抽取样本点
如果这个样本点是核心对象,那么从这个点出发,找到所有密度可达的对象,构成一个簇
如果这个样本点不是核心对象,那么再重新找下一个点
算法优点
不需要划分个数(只需要计算)
可以处理噪点
可以处理任何形状的空间聚类问题
算法缺点
需要指定最小样本量和半径两个参数
数量大时开销也很大
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量比较差
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import dbscan
#生成500个点,噪声为0.1
X,_=datasets.make_moons(500,noise=0.1,random_state=1)
df=pd.DataFrame(X,columns=['x','y'])
df.plot.scatter('x','y',s=200,alpha=0.5,c="green",title='dataset by DBSCAN')
plt.show()

生成的绿色结果
#eps为邻域半径,min_samples为最少样本量
core_samples,cluster_ids=dbscan(X,eps=0.2,min_samples=20)
#cluster_ids中-1表示对应的点为噪声
df=pd.DtaFrame(np.c_[X,cluster_ids],columns=['x','y','cluster_id'])
df['cluster_id']=df['cluster_id'].astype('i2')
#绘制结果图像
df.plot.scatter('x','y',s=200,
c=list(df['scatter_id']),cmap='Reds',colorbar=False,
alpha=0.6,title='DBSCAN cluster result')
plt.show()









 京公网安备 11010802041100号
京公网安备 11010802041100号