Flink官方教程学习笔记
- 学习资源
- Scala相关
- Flink Exercises (强推)
- 配置Flink Tutorial所需的环境
- Flink Tutorial学习笔记
- 流式处理
- 并行的数据流
- 有状态的流处理
- 数据流API
- 执行环境
- Basic Stream functions
- ETL
学习资源
Scala相关
Scala Basics:https://docs.scala-lang.org/tour/basics.html // 已学习
Flink Exercises (强推)
教程:
- EG: https://github.com/apache/flink-training/blob/release-1.15/README.md
- CN: https://github.com/apache/flink-training/blob/release-1.15/README_zh.md
- Flink Chinese:https://flink.apachecn.org/#/
- Flink English: https://flink.apache.org/
数据集
- Data: https://github.com/apache/flink-training/blob/release-1.15/README.md#using-the-taxi-data-streams
- 数据介绍:
taxi event
rideId : Long // a unique id for each ride
taxiId : Long // a unique id for each taxi
driverId : Long // a unique id for each driver
isStart : Boolean // TRUE for ride start events, FALSE for ride end events
eventTime : Instant // the timestamp for this event
startLon : Float // the longitude of the ride start location
startLat : Float // the latitude of the ride start location
endLon : Float // the longitude of the ride end location
endLat : Float // the latitude of the ride end location
passengerCnt : Short // number of passengers on the ride
fare event
rideId : Long // a unique id for each ride
taxiId : Long // a unique id for each taxi
driverId : Long // a unique id for each driver
startTime : Instant // the start time for this ride
paymentType : String // CASH or CARD
tip : Float // tip for this ride
tolls : Float // tolls for this ride
totalFare : Float // total fare collected
配置Flink Tutorial所需的环境
- 安装Flink:
- 注意Java版本:必须在11以上
- 注意Flink版本:没有Web UI可能是Flink的版本太低(1.4没有,1.9实测可用)
- Windows下推荐使用cygdrive命令行环境
安装后界面:
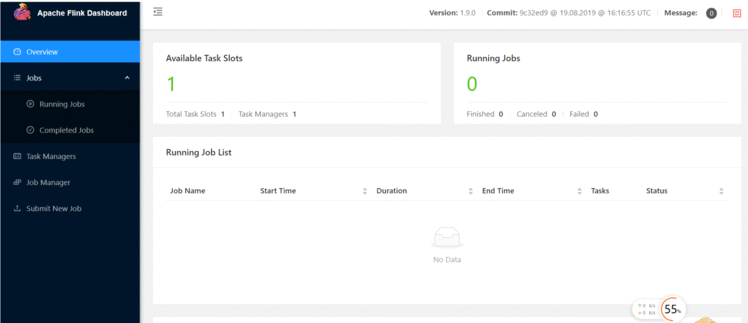
2.下载Flink Tutorial:
https://github.com/apache/flink-training/tree/release-1.15/
在Win界面下可能会报错【# \r‘:command not found】

修改换行方式:
https://blog.csdn.net/fangye945a/article/details/120660824
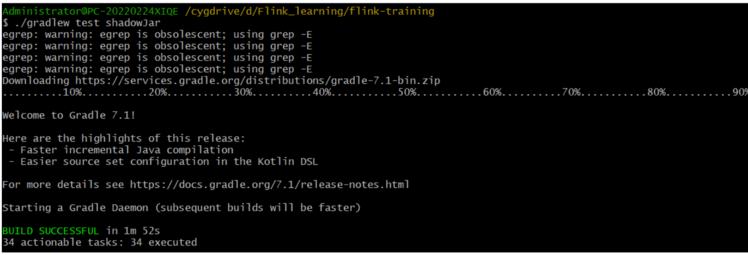
3. 完善Exercise.scala文件,运行test文件,即可看到结果。
Scala中也可以调用Java的函数:https://docs.scala-lang.org/scala3/book/interacting-with-java.html
Flink Tutorial学习笔记
流式处理
教程链接: https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/learn-flink/overview/
- Streams are data’s natural habitat.
- 批处理: ingest the entire dataset before producing any results
- 流处理:the input may never end, and so you are forced to continuously process the data as it arrives.
在Flink中,数据流从source中读入,被operator转换,最终流入sink. - 一次转换可能包含多个operator.
流可以从消息队列或分布式日志系统中读入,例如:Apache Kafka or Kinesis.但是Flink也可以读入bounded的数据来源。输出同理。
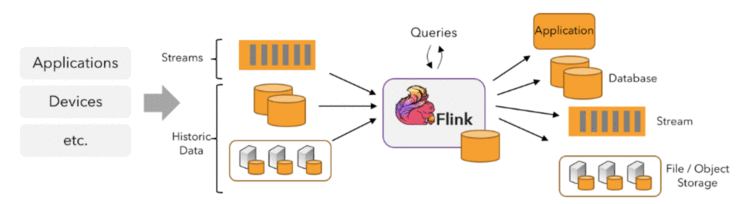
并行的数据流
Flink程序内在本身就是并行且分布式的。
-
每一个数据流都有多个stream partition.
-
每一个operator都有多个operator subtasks,不同操作符的并行级别不一样.
- The number of operator subtasks is the parallelism of that particular operator. Different operators of the same program may have different levels of parallelism.
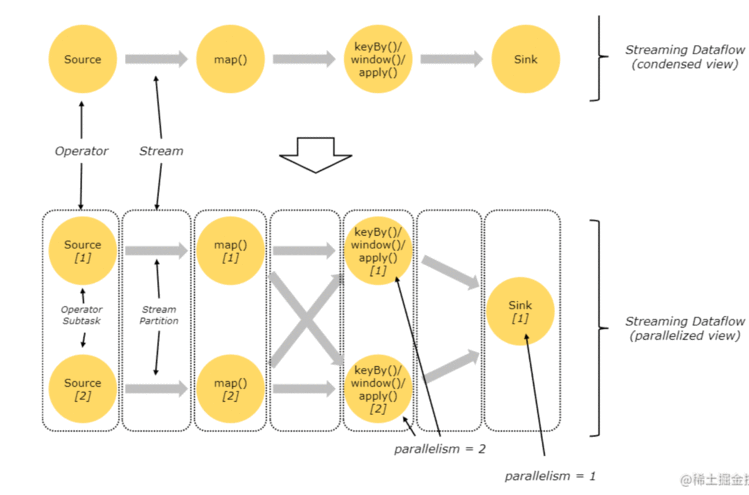
-
One-to-one streams:例如source和map
-
Redistributing streams:
- 改变了数据流的划分
- introduce non-determinism regarding the order in which the aggregated results for different keys arrive at the Sink
-
实时流:可以通过在数据中加入时间戳
有状态的流处理
-
Flink’s operations can be stateful. This means that how one event is handled can depend on the accumulated effect of all the events that came before it.
-
A Flink application is run in parallel on a distributed cluster. The various parallel instances of a given operator will execute independently,in separate threads, and in general will be running on different machines.
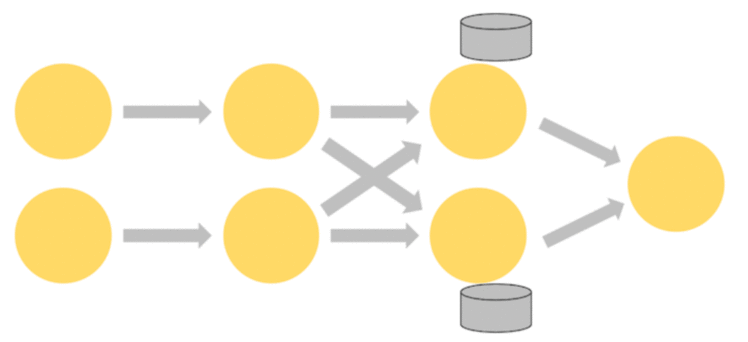
-
The 3rd operator is stateful.
-
A fully-connected network shuffle is occurring between the second and third operators.
-
This is being done to partition the stream by some key, so that all of the events that need to be processed together, will be.
数据流API
教程链接:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/learn-flink/datastream_api/
- 可以流式处理的:
- basic types, i.e., String, Long, Integer, Boolean, Array
- composite types: Tuples, POJOs, and Scala case classes
执行环境
- Streaming applications need to use a
StreamExecutionEnvironment. - When
env.execute() is called the job graph is packaged up and sent to the JobManager, which parallelizes the job and distributes slices of it to the Task Managers for execution. - Each parallel slice of your job will be executed in a task slot.
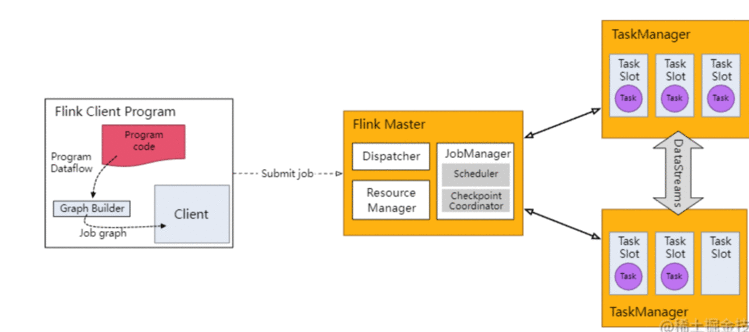
Basic Stream functions
1.env.fromCollections:从列表创建
List people = new ArrayList();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream flintstones = env.fromCollection(people);
2.env.socketTextStream/readTextfile 从远程/文件读取
DataStream lines = env.socketTextStream("localhost", 9999);
DataStream lines = env.readTextFile("file:///path");
小结:流主要通过env中的函数读取。
Streams could also be debugged by inserting local breakpoints,etc.
ETL
教程链接:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/learn-flink/etl/
Flink’s table API:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/overview/
map(): only suitable for one-to-one corespondence (全射)
- for each and every stream element coming in, map() will emit one transformed element.
flatmap(): otherwise cases





 京公网安备 11010802041100号
京公网安备 11010802041100号