ConfiguringHeterogeneousStorageinHDFS
作者:feify_fei512_478 | 来源:互联网 | 2023-08-31 15:20
Hadoop在2.6.0版本中引入了一个新特性异构存储.异构存储可以根据各个存储介质读写
超冷数据存储,非常低廉的硬盘存储 - 银行票据影像系统场景 默认存储类型 - 大规模部署场景,提供顺序读写IO SSD类型存储 - 高效数据查询可视化,对外数据共享,提升性能 RAM_DISK - 追求极致性能 混合盘 - 一块ssd/一块hdd + n sata/n sas HDFS Storage Typestorage types:
ARCHIVE - Archival storage is for very dense storage and is useful for rarely accessed data. This storage type is typically cheaper per TB than normal hard disks.
DISK - Hard disk drives are relatively inexpensive and provide sequential I/O performance. This is the default storage type.
SSD - Solid state drives are useful for storing hot data and I/O-intensive applications.
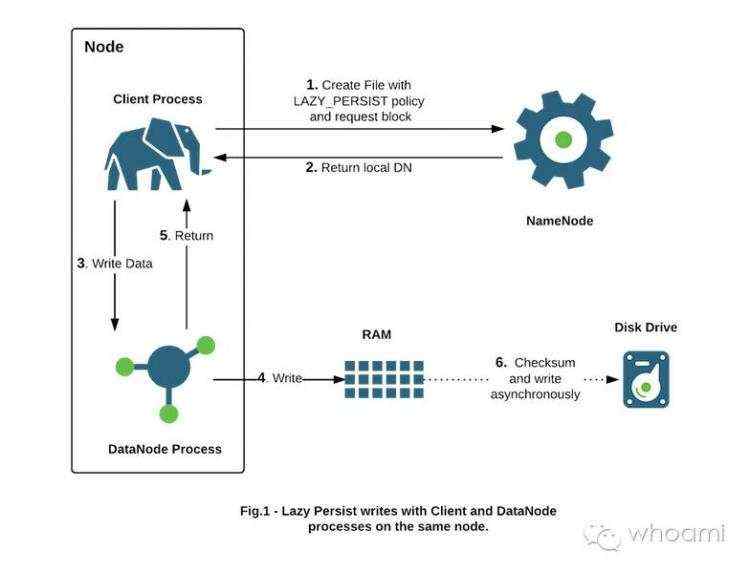
RAM_DISK - This special in-memory storage type is used to accelerate low-durability, single-replica writes.
Storage PoliciesSetting a Storage Policy for HDFSManaging Storage PoliciesTestiperf 检测主机间网络带宽
yum install http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
如下,在第一个机器启动一个监听,去另外一个服务器压测,网络带宽;可以看到网络带宽:10Gbits
[root@bigdata-server-1 ~]# iperf -s
hdfs NFSGateway
[root@bigdata-server-1 ~]# mkdir /hdfs
hdfs fuse
$ yum install hadoop_2_3_4_0_3485-hdfs-fuse.x86_64
单盘ssd,sata性能
[root@bigdata-server-1 ssd]# dd if=/dev/zero of=/data12/test004 bs=1M count=100000
iostat
iostat -d -k 1 5 查看磁盘吞吐量等信息。
DFSTestIO
SSD
$ time hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -Dtest.build.data=/ssd -write -nrFiles 4 -fileSize 50000
SATA
$ time hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -Dtest.build.data=/sata -write -nrFiles 4 -fileSize 50000
RAM
$ time hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -Dtest.build.data=/ram -write -nrFiles 4 -fileSize 50000
MapReduce Performance on SSDs/SATA/RAM/SSD-SATA 测试hdfs异构存储性能结果白皮书,后续内容发布…
FAQ1、ambari Version 2.2.2.0 和 HDP-2.4.2.0-258 版本,安装后配置多种异构存储类型,[RAM_DISK]方式ambari配置界面验证失败,无法通过!此为一个bug!详情访问:https://issues.apache.org/jira/browse/AMBARI-14605 参考:
Configuring Heterogeneous Storage in HDFS: https://www.cloudera.com/documentation/enterprise/latest/topics/admin_heterogeneous_storage_oview.html#admin_heterogeneous_storage_config
The Truth About MapReduce Performance on SSDs: http://blog.cloudera.com/blog/2014/03/the-truth-about-mapreduce-performance-on-ssds/
Memory Storage Support in HDFS: http://aajisaka.github.io/hadoop-project/hadoop-project-dist/hadoop-hdfs/MemoryStorage.html
Archival Storage, SSD & Memory: http://aajisaka.github.io/hadoop-project/hadoop-project-dist/hadoop-hdfs/ArchivalStorage.html
How to configure storage policy in Ambari?: https://community.hortonworks.com/questions/2288/how-to-configure-storage-policy-in-ambari.html
Using NFS with Ambari 2.1 and above: https://community.hortonworks.com/questions/301/using-nfs-with-ambari-21.html
Disaster recovery and Backup best practices in a typical Hadoop Cluster:https://community.hortonworks.com/articles/43575/disaster-recovery-and-backup-best-practices-in-a-t-1.html
原创文章,转载请注明: 转载自whoami的博客本博客的文章集合:
推荐阅读
本文详细介绍了优化DB2数据库性能的多种方法,涵盖统计信息更新、缓冲池调整、日志缓冲区配置、应用程序堆大小设置、排序堆参数调整、代理程序管理、锁机制优化、活动应用程序限制、页清除程序配置、I/O服务器数量设定以及编入组提交数调整等方面。通过这些技术手段,可以显著提升数据库的运行效率和响应速度。 ...
[详细]
蜡笔小新 2024-12-22 16:20:33
本文介绍了一段通用代码示例,该代码不仅能够操作 Azure Active Directory (AAD),还可以通过 Azure Service Principal 的授权访问和管理 Azure 订阅资源。Azure 的架构可以分为两个层级:AAD 和 Subscription。 ...
[详细]
蜡笔小新 2024-12-27 16:07:12
springMVC JRS303验证 ...
[详细]
蜡笔小新 2024-12-20 09:07:39
本文深入探讨了 Java 中的 Serializable 接口,解释了其实现机制、用途及注意事项,帮助开发者更好地理解和使用序列化功能。 ...
[详细]
蜡笔小新 2024-12-27 15:06:12
本文详细介绍了Akka中的BackoffSupervisor机制,探讨其在处理持久化失败和Actor重启时的应用。通过具体示例,展示了如何配置和使用BackoffSupervisor以实现更细粒度的异常处理。 ...
[详细]
蜡笔小新 2024-12-27 15:04:09
本文探讨了MariaDB在当前数据库市场中的地位和挑战,分析其可能面临的困境,并提出了对未来发展的几点看法。 ...
[详细]
蜡笔小新 2024-12-25 18:20:32
本文详细介绍了 Apache Shiro,一个强大且灵活的开源安全框架。Shiro 专注于简化身份验证、授权、会话管理和加密等复杂的安全操作,使开发者能够更轻松地保护应用程序。其核心目标是提供易于使用和理解的API,同时确保高度的安全性和灵活性。 ...
[详细]
蜡笔小新 2024-12-25 16:03:57
一、【组网和实验环境】按如上的接口ip先作配置,再作ipsec的相关配置,配置文本见文章最后本文实验采用的交换机是H3C模拟器,下载地址如 ...
[详细]
蜡笔小新 2024-12-22 20:24:15
探讨 HDU 1536 题目,即 S-Nim 游戏的博弈策略。通过 SG 函数分析游戏胜负的关键,并介绍如何编程实现解决方案。 ...
[详细]
蜡笔小新 2024-12-21 18:26:33
在寻找轻量级Ruby Web框架的过程中,您可能会遇到Sinatra和Ramaze。两者都以简洁、轻便著称,但它们之间存在一些关键区别。本文将探讨这些差异,并提供详细的分析,帮助您做出最佳选择。 ...
[详细]
蜡笔小新 2024-12-20 11:00:15
本文深入探讨了如何通过多种技术手段优化ListView的性能,包括视图复用、ViewHolder模式、分批加载数据、图片优化及内存管理等。这些方法能够显著提升应用的响应速度和用户体验。 ...
[详细]
蜡笔小新 2024-12-28 10:36:30
本文详细解析了 DotNetNuke (DNN) 的两种主要版本:Community 和 Professional。通过对比两者的功能和附加组件,帮助用户选择最适合其需求的版本。 ...
[详细]
蜡笔小新 2024-12-27 13:14:08
ImmutableX is set to spearhead the evolution of Web3 gaming, with its innovative technologies and strategic partnerships driving significant advancements in the industry. ...
[详细]
蜡笔小新 2024-12-27 08:55:17
本文介绍如何使用阿里云的fastjson库解析包含时间戳、IP地址和参数等信息的JSON格式文本,并进行数据处理和保存。 ...
[详细]
蜡笔小新 2024-12-26 16:06:09
本文深入探讨了MySQL中常见的面试问题,包括事务隔离级别、存储引擎选择、索引结构及优化等关键知识点。通过详细解析,帮助读者在面对BAT等大厂面试时更加从容。 ...
[详细]
蜡笔小新 2024-12-20 18:58:01
feify_fei512_478
这个家伙很懒,什么也没留下!
 Hadoop在2.6.0版本中引入了一个新特性异构存储.异构存储可以根据各个存储介质读写特性的不同发挥各自的优势.一个很适用的场景就是冷热数据的存储.针对冷数据,采用容量大的,读写性能不高的存储介质存储,比如最普通的Disk磁盘.而对于热数据而言,可以采用SSD的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度,甚至可以把数据直接存放内存,懒加载入hdfs.HDFS的异构存储特性的出现使得我们不需要搭建两套独立的集群来存放冷热2类数据,在一套集群内就能完成.所以这个功能特性还是有非常大的实用意义的.下面我介绍一下异构存储的类型,以及如果灵活配置异构存储!
Hadoop在2.6.0版本中引入了一个新特性异构存储.异构存储可以根据各个存储介质读写特性的不同发挥各自的优势.一个很适用的场景就是冷热数据的存储.针对冷数据,采用容量大的,读写性能不高的存储介质存储,比如最普通的Disk磁盘.而对于热数据而言,可以采用SSD的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度,甚至可以把数据直接存放内存,懒加载入hdfs.HDFS的异构存储特性的出现使得我们不需要搭建两套独立的集群来存放冷热2类数据,在一套集群内就能完成.所以这个功能特性还是有非常大的实用意义的.下面我介绍一下异构存储的类型,以及如果灵活配置异构存储!







 京公网安备 11010802041100号
京公网安备 11010802041100号