我们知道,linux 的容器是隔离在自己的网络栈中的,其他的network namespace 是看不到自己的。这样有一个好处就是每个容器都可以拥有自己的ip 和端口,当多个容器部署在同一台机的时候就不需要小心翼翼的设置端口,避免和其他的进程进行冲突了。但是同样会带来一个问题,我的容器如何和别人的容器进行通讯呢?
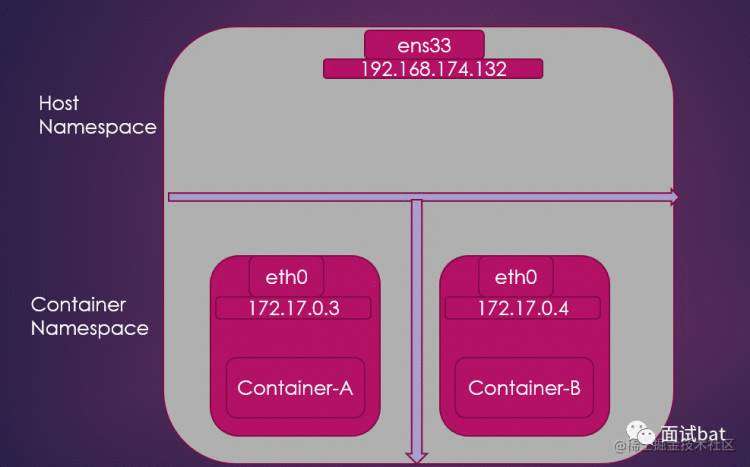
如果要理解这个问题,首先我们可以先把每一个容器都当成独立的一台主机,那么容器和容器之间的通讯问题就变成了我们熟悉的主机和主机之间的通讯问题了。我们知道,如果想主机A和主机B要通讯,那就最简单的做法那就是我们直接用跟网线直接连接在一起就可以了,如果主机A 想和很多主机一起通讯,那大家一起都连在同一个交换机就可以了。
这里的网线对应到linux 上其实就是 Veth Pair 虚拟设备,这个东西一些特殊之处
就是必须是成对出现的,一个插入在A 容器,一个插入容器B。
每一个Veth 就是个虚拟网卡,他们都有自己的IP
在其中一个Veth 发出一个数据包,在另外一个Veth就可以马上收到这个数据包,这样容器A就可以和容器B进行通讯了
一台机可以运行很多个docker ,那容器A 可能需要和很多个容器通讯那就需要一个类似交换机的东西,对应到linux 上,发挥交换机作用的就是网桥
docker 项目默认会创建一个叫做docker0 的网桥,每一个容器启动后就会创建一个Veth Pair 对,一头插在自己的容器,另外一个插在docker0 网桥。这样容器A 需要和其他容器通讯,首先拿到容器X 的ip ,然后发起ARP 广播,网桥给所有的插在它身上的Veth 进行转发,容器X 发现是自己的IP,就回复下自己的mac地址给容器A,那么容器A 拿到mac 地址,就可以直接和容器X 在链路层进行通讯了
启动一个nginx 容器,并且进入的到容器内查看下ifconfig 命令
root@d2e9ed3eb44d:/# ifconfig
eth0: flags=4163
inet 172.17.0.3 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:03 txqueuelen 0 (Ethernet)
RX packets 2471 bytes 8877026 (8.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1592 bytes 87477 (85.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
执行下route 看看路由配置
root@d2e9ed3eb44d:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
默认所有的流量都走路由到eth0,另外所有属于网段172.17的流量也会转发到eth0,这里的eth0 其实就是我们刚说插在容器内的其中一个Veth ,那么它另外一个肯定就是插在了宿主机上。
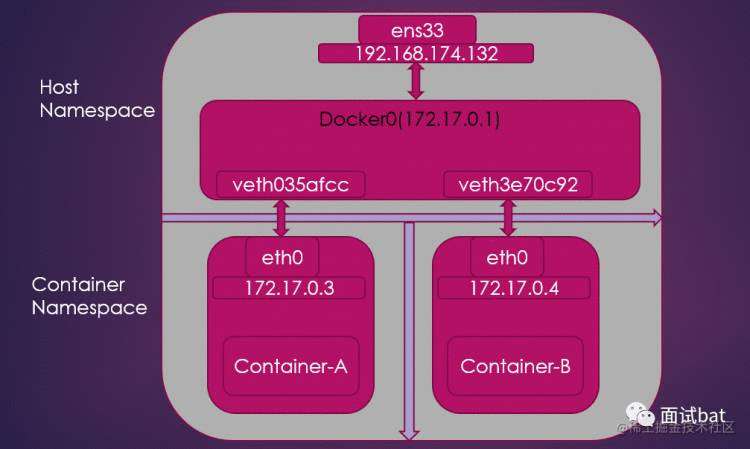
我们回到宿主机器执行,执行ifconfig ,我们可以看到docker0 的虚拟网卡
willjo@ubuntu:/$ ifconfig
docker0: flags=4163
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:42ff:fe00:60de prefixlen 64 scopeid 0x20
ether 02:42:42:00:60:de txqueuelen 0 (Ethernet)
RX packets 1128574 bytes 411733106 (411.7 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1213207 bytes 435163705 (435.1 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163
inet 192.168.174.132 netmask 255.255.255.0 broadcast 192.168.174.255
inet6 fe80::20c:29ff:fed5:29e4 prefixlen 64 scopeid 0x20
ether 00:0c:29:d5:29:e4 txqueuelen 1000 (Ethernet)
RX packets 1420013 bytes 456399624 (456.3 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1270917 bytes 436894257 (436.8 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们看看这台机器的网桥
willjo@ubuntu:~$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242420060de no veth035afcc
我们可以看到veth035afcc 这个已经插在docker0这个网桥上了
如果我们再启动一个容器B,就会发现另外一个容器的Veth设备也插入在这个网桥上
willjo@ubuntu:~$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242420060de no veth035afcc
veth3e70c92
容器B的IP
root@c151772ac203:/# ifconfig
eth0: flags=4163
inet 172.17.0.4 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:04 txqueuelen 0 (Ethernet)
RX packets 1990 bytes 8850903 (8.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1790 bytes 98157 (95.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们在容器A ping一下容器B的地址。容器A的IP:172.17.0.3 容器B的IP:172.17.0.4 (细心的你可能可以发现他们是属于同一个网段)
root@146c46299b69:/# ping 172.17.0.4
PING 172.17.0.4 (172.17.0.4) 56(84) bytes of data.
64 bytes from 172.17.0.4: icmp_seq=1 ttl=64 time=0.951 ms
64 bytes from 172.17.0.4: icmp_seq=2 ttl=64 time=0.048 ms
64 bytes from 172.17.0.4: icmp_seq=3 ttl=64 time=0.037 ms
上面我们知道,相同的机器不同容器通讯可以通过一个docker0 的虚拟网桥来进行连接。如果是不同机器呢?其实思路是一样的,我们在三层网络之上架上一座桥,然后把两个机器打通即可,这就是大名鼎鼎的overlayNetwork

假如容器A 要访问容器C的时候,由于他们是在不同的机器上,原本他们是没有办法通讯的,因为他们对外的真正网卡是192.169网段的。但是如果我们用软件实现了一层overlay NetWork 的时候,他们的通讯的流程变成这样子:
容器A访问容器C
容器A把网络包交给overlay NetWork
node1 上的软件overlay NetWork 和node2 机器上overlay NetWork 进行通讯,把原来的数据包送到容器C上
基于Overlay Network 的网络原理,有一个项目真正的落地了,这个项目就是CoreOs 公司主推的容器网络解决方案 Flannel,目前Flanel 支持三种后端实现:
UDP
VXLAN
host-gw
UDP 方案是最早的,也是性能最差的一种实现方案。但这个方案是最简单,最方便我们理解的一个方案;
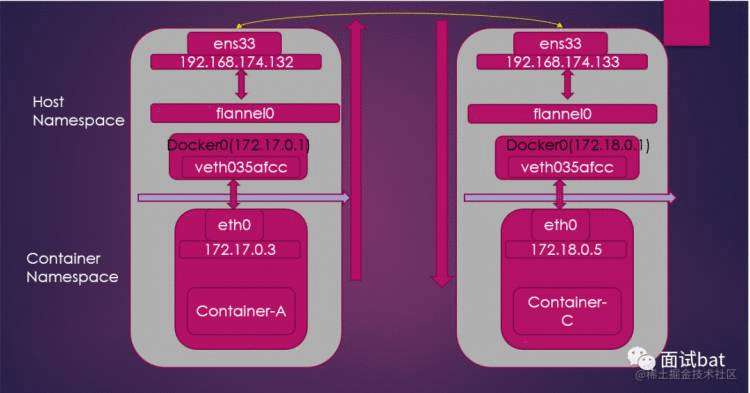
有两台机器 node1(192.168.174.132),node2(192.168.174.133)
node1 有容器A(172.17.0.3),node2 有容器C(172.18.0.5)
目标容器A访问容器C

由于容器C的IP和容器A不在同一个网段,所以容器A 需要通过容器A路由表进行查询,看看数据包通过哪个网卡发出去,这个时候会走默认路由,通过Veth对数据包流转到宿主机的docker0 上,然后这个网络包具体怎么转发就得看宿主机上的路由表了,我们看下宿主机器上的路由规则
willjo@ubuntu:~$ ip route
default via 192.168.174.2 dev ens33 proto static
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.0.0/16 dev flannel0 proto kernel scope link src 172.18.0.1
192.168.174.0/24 dev ens33 proto kernel scope link src 192.168.174.132
我们可以看到走的是路由表的第三条,172.18.0.0/16 这个网段,通过flannel0 发出去,而这个flannel0 其实就是Tunnel 设备,是工作在三层虚拟网络设备,它的功能就是负责在操作系统内核和用户的应用程序之间传递IP包,粗暴点理解,可以看成为一个Java 写的一个特殊进程。
flannel0 进程收到这个网络包的时候,看到目的地址是172.18.0.5,知道这个IP 是属于node2的宿主机器上的容器的ip,然后就把这个网络包用UDP 包了一层,目的地址改成node2的ip (192.168.174.133)源ip改成(192.168.174.132)

这个时候node2 上的flannel0 的进程就收到了这个数据包,就会进行拆包,拿到真实的源数据包,看到目的地址是172.18.0.5,就转发给docker0 ,docker0 通过广播的方式确认这个数据包是容器C的,这样就完成整个通讯的流程。
整个过程是 容器A->查看容器自身的路由表->docker0->查看宿主机上的路由表->flannel0,进行数据包包装->node2上的flannel0 进行数据包解包->node2 docker0->容器C
这里有几个疑问:
首先每一个node 都必须有一个flanenel0 进行监听8285 端口
谁在每个node 上建立路由表,设置对应的网段路由到flannel0
flannel0 如何判断一个容器的IP是在哪一个宿主机器上
第一个问题好解决,只要每个node安装并且启动就可以
第二个问题和第三个问题,就涉及到网络上子网的一个概念。也就意味着每一个node 都必须有独立的子网,并且是不能和其他node 进行冲突的。为什么不能冲突呢?假如冲突会有什么问题呢?打个比方,node2 上有一个容器C的IP是172.18.0.5/16,node3 上有一个容器X 的ip172.18.0.8/16.这个时候,flannel0 看到这172.18.0.0/16 这个网段根本没办法判断这个数据包转发给哪台机器。也就没法工作了。
为什么又说这种方式的性能差呢?
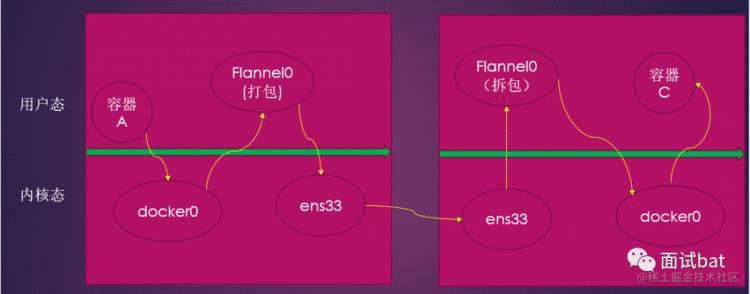
从上图我们可以看到:
容器A 在用户态发起一个IP包,经过docker0 进入内核态
docker0 通过路由表转发到tune 设备进入用户空间态的flannel0
flannel 进行udp 把原始的IP包进行封装,通过ens33 发送出去,这个时候是从用户态进入的内核态
同理node2也会来一个跟node1 方向的操作
所以我们可以看到整个过程涉及到大量的内核态和用户态的切换,这个切换代价是很高的,也是它的性能低下的原因。
如果让你来优化UDP这个过程你怎么做?自然能想到的一种办法就是减少用户态和内核态的切换,把flannel0 做的工作下层的内核态
这就是后面演化出来的VXLAN(虚拟可扩展局域网) 模式。
| 功能 | UDP | VXLAN |
|---|---|---|
| 发生拆解包的操作系统层级 | 用户态 | 内核态 |
| 发生拆解包的网络层 | 4层传输层 | 2层 数据链路层 |
| 性能 | 低 | 高 |
| 是否可以跨局域网通讯 | 可以 | 可以 |
每台机器都会有一个vtep 设备,这个设备和上面的flannel0 很类似,只是它是工作在内核态,并且是在数据链路层的,我们暂且叫做flannel1,当它启动的时候,同样会将本机器子网和flannel1 的IP 地址告诉所有的其他机器,其他机器就会在自己的路由表上添加一条路由规则
举个例子:node2 上有一个vtep 设备,IP 地址是172.18.0.1 ,那么node2 启动的时候,就会在其他主机包括node1 上注册一条路由规则:
root@node1:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
172.18.0.0 172.18.0.1 255.255.0.0 UG 0 0 0 flannel.1
这时候,如果node1 上的dockerA 要和node2 上的dockerC 进行通讯的时候,前面的流程和UDP 模式一样,这里通过 dockerA 流向docker0,查询路由表发向flannel.1,这个是发生在内核态的数据链路层,下一跳是172.18.0.1。这个地址就是node2上的flannel1 的ip 地址。因为flannel.1 是工作在数据连路程,通讯需要mac 地址,上面的路由表只是知道IP地址,我们还需要他的mac 地址,正常情况是通过ARP 广播获取,但是可能两个node是不一定属于同一个局域网的,所以这种方式不一定行的通,所以flannel.1是提前把node2 的flannel1 的mac 地址注册到node1 上的,我们通过以下命令可以查看
在node1 上执行
root@node1:/# ip neigh show dev flannel.1
172.18.0.1 lladdr 00:50:56:eb:a9:5f PERMANENT
数据包会变成下面这样子

这里我们拿到node 上的falnnel 的mac地址其实是没有用的,没办法直接通讯,我们需要知道node2的ip 和mac 地址才能够通讯,这个需要我们需要查询一个叫做FDB 的信息,这个信息也是由flannel.1 来进行维护的,其实也是充当一个网桥的作用
$ bridge fdb show flannel.1 |gerp 00:50:56:eb:a9:5f
00:50:56:eb:a9:5f dev flannel.1 dst 192.168.174.133 self permanent
我们可以看到mac 地址的00:50:56:eb:a9:5f 目的ip 是192.168.174.133,这个IP正好就是node2 的IP地址,至于node2的mac地址通过正常的arp方式即可获取到了。

但是还有一个问题需要解决,当node2 收到这个数据帧的时候,怎么知道这个数据帧是经过VETH 包装的还是一种普通的数据帧呢?这个时候就需要加一个VETH 的标识来告诉node2 这个数据帧是被VETH 包装过了,并且告诉应该交给node2机器上的哪一个VETH 来处理,那么数据包就需要变成下面

这一节,我们用k8s 的calico 的BGP 模式,其实这个模式基本是跟flannel中的host-gw 的一样的,为了节省篇幅,我们就直接叫calico的BGP 模式.
其实我们上面介绍的两种实现,他们都是要经过拆包和解包的,这个过程不管是在用户态的拆包解包的UDP 还是在内核态的VXLAN ,这个过程都是会导致性能损耗的。那能不能不要拆包和解包就能够直接通讯呢?还真有,当然前提是所有的机器都必须在同一个局域网,目前知道的两个实现就是flannel 的host-gw 和calico 的BGP 。我们知道主机的ip网段和pod 的网段是不相同的,按照我们的网络知识是不同的网段就需要经过路由器进行。路由才能够到达。所以如果我们拥有一个智能的路由器,根据一个pod 的ip知道他在哪里,直接路由到这个pod 那就可以解决。
从host-gw 这个名字你可以大概能够猜到,其实每台主机都被当成了gateway 进行路由。如果要路由,我们知道就需要一张路由表。通过route -n 我们就可以看到本机器的路由表
willjo@ubuntu:~$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.174.2 0.0.0.0 UG 0 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
默认下一跳192.168.174.2 是这个网关出去.
现在node3(192.168.174.133) 上的pod A (10.100.135.25) 想访问node2(192.168.174.131) 上的pod-C(10.100.104.15)
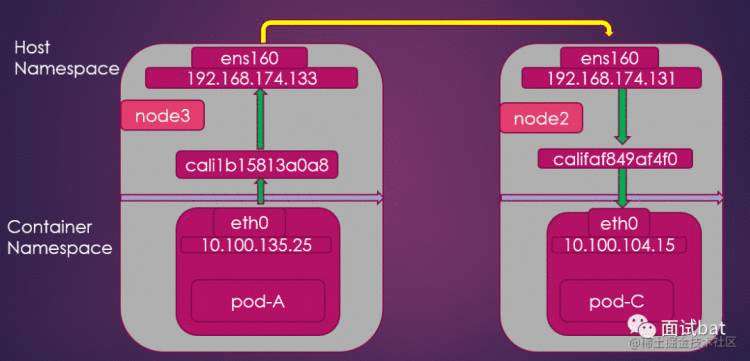

那我们只需要在node3 创建一条路由规则,把这个数据包直接送到node2上
route add -net 10.100.104.0/26 gw 192.168.174.131 ens33
添加成功后执行(当然上面这条路由规则是由calico 自动创建的)
[root@node3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.174.2 0.0.0.0 UG 100 0 0 ens160
10.100.104.0 192.168.174.131 255.255.255.192 UG 0 0 0 ens160
可以看到发现10.100.104.0 网段的数据包直接下一跳就是192.168.174.131 这台机器,这台机器正好就是pod C 所在的机器node2的IP
数据包进入到node2的时候,还需要转发到pod C 上,以前我们知道容器是通过网桥来实现的,calico这里有点区别,他是直接通过Veth 对来直接连接的
[root@node2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.174.2 0.0.0.0 UG 100 0 0 ens160
10.100.104.0 0.0.0.0 255.255.255.192 U 0 0 0 *
10.100.104.15 0.0.0.0 255.255.255.255 UH 0 0 0 cali1b15813a0a8
10.100.135.0 192.168.174.133 255.255.255.192 UG 0 0 0 ens160
10.100.166.128 192.168.174.129 255.255.255.192 UG 0 0 0 ens160
192.168.174.0 0.0.0.0 255.255.255.0 U 100 0 0 ens160
我们可以看到第三行,如果是10.100.104.15 的ip 就直接发往网卡cali1b15813a0a8 ,这个其实就是Veth,另一端连接着pod C ,这样流量就可以直接进入到pod C 拉。
当然数据要返回的时候,在node2 也同样需要配置一些路由才可以。
其实我们知道,为了高可用,一般我们会部署多个pod ,并且希望他们通过负载均衡的算法来分摊流量。比如有一个订单服务order-service ,我们部署了50 个pod.他们组合在一起统一对外提供服务。但是由于应用重启之后pod就销毁了,会重新启动一个新的pod ,那么他的ip 是会不停的变化的,所以这样会带来管理的麻烦,这个时候就会出现了service 的概念,service 有一个固定的VIP ,service负责发现各个pod ,并且有service 来通过负载均衡的方式来路由到真正的pod 去处理请求。
service 其实有几种类型
ClusterIP
HeadLess
loadBalance
NodePod
我们这里只介绍ClusterIP ,其他的请大家移步到官网学习。
创建一个service
apiVersion: v1
kind: Service
metadata:
annotations: {}
name: nginx-service
namespace: default
spec:
ports:
- name: ybydat
port: 80
protocol: TCP
targetPort: 80
selector:
k8s.kuboard.cn/layer: web
k8s.kuboard.cn/name: nginx
type: ClusterIP
创建完后 k8s 会自动分配一个ClusterIP:10.96.55.191 给nginx-service ,servcie关联在后面的名字叫nginx 的pod

有了这个ClusterIP ,以后你就可以直接通过这个IP 来反问nginx 啦,不再关心nginx 这个pod 的ip 是否会变化。
其实CLusterIP你ping 是ping 不通的,他只是一个虚拟IP ,并不是真正的IP。那他又是怎么实现访问这个IP可以真正访问到nginx 这个pod 的呢?service 其实是由kube-proxy 组件,加上iptables 来共同实现的。
如果想知道它的工作原理,这里就不得不说netfilter/iptables 这个神器了。
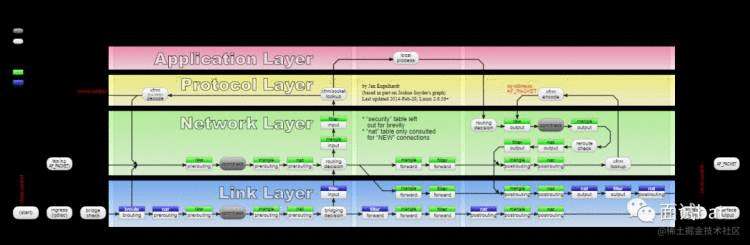
netfilter 提供了很多hooks,iptables 就是通过与hooks 交互来实现各种过滤等防火墙功能和一些网络的nat。这里我们重点会讲nat。如果想了解更多netfilter/iptables 知识,来个传送门[]
每个进入网络系统的包(接收或发送)在经过协议栈时都会触发这些 hook,所以在这些hook 注册函数即可实现网络nat 的功能
[root@node3 ~]# iptables-save |grep 10.96.55.191
-A KUBE-SERVICES -d 10.96.55.191/32 -p tcp -m comment --comment "default/nginx-service:ybydat cluster IP" -m tcp --dport 80 -j KUBE-SVC-6EVOKSP3B2XMBIWJ
-A KUBE-SVC-6EVOKSP3B2XMBIWJ ! -s 10.100.0.0/16 -d 10.96.55.191/32 -p tcp -m comment --comment "default/nginx-service:ybydat cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
可以看到,如果访问的IP是10.96.55.191 端口是80 的话跳转到KUBE-SVC-6EVOKSP3B2XMBIWJ
跳到KUBE-SVC-6EVOKSP3B2XMBIWJ 的作用,其实就是KUBE-SVC-6EVOKSP3B2XMBIWJ 下面挂着一堆pod 的地址
[root@node3 ~]# iptables-save |grep KUBE-SVC-6EVOKSP3B2XMBIWJ
-A KUBE-SVC-6EVOKSP3B2XMBIWJ -m comment --comment "default/nginx-service:ybydat" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-W7LLWAZGY5L4XB27
-A KUBE-SVC-6EVOKSP3B2XMBIWJ -m comment --comment "default/nginx-service:ybydat" -j KUBE-SEP-CDLRHTIOG674VNFD
我机器是有两个pod ,所以这里有条记录,random 可以看到他是通过负载均衡的方式随机跳转到 KUBE-SEP-W7LLWAZGY5L4XB27和KUBE-SEP-CDLRHTIOG674VNFD,这两个其实就是对应到pod
我们看下其中一个
[root@node3 ~]# iptables-save |grep KUBE-SEP-W7LLWAZGY5L4XB27
-A KUBE-SEP-W7LLWAZGY5L4XB27 -p tcp -m comment --comment "default/nginx-service:ybydat" -m tcp -j DNAT --to-destination 10.100.135.28:80
可以看到最终的目的是到10.100.135.28:80,这个是其中之一的pod IP。好了,到这里我们就可以解析清楚了service 的工作原理了。另外补充下,其实kube-proxy 支持的模式还有IPVS,我们生产环境用的就是这个,之所以不使用iptables ,是因为iptables 是工作在用户态的,而IPVS 是工作在内核态的,所以这里可以看到一种性能优化还是把工作态下沉到内核态去进行处理。(我们从iptables 切换到IPVS 的时候还导致了服务调不通,以后有机会可以解析下,让大家避坑)
ingress 其实就是service 的service 。看到一个事物的时候,我们首先得明白这个东西是解决什么问题的。为何需要ingress 呢?从上面的servcie ,如果是CLusterIP 模式的话,外网是没办法访问的,毕竟它是k8s 里面一个虚拟IP 。那么我们需要一个可以通过外网就能访问的服务进行转发,可能你会说,如果service 如果是NodePod 模式的话,也可以通过外网访问啊,是的,确实没错,但是如果我们的服务很多的时候,我们需要记住很多的IP,这样是很不方便的,我们希望可以通过url 级别进行一个路由转发到不同的服务,域名是保持不变的。比如demo.com/order 转发到订单服务,demo.com/product 转发到商品服务
ingress 包好了路由规则文件和ingress controller 。k8s 默认的ingress controller 就是nginx.看到这里你可能就明白了,其实就是借助nginx 来进行一些负载均衡的






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有