仔细观察发现,现在懂爬虫、学习爬虫的人越来越多。

为什么Python爬虫这么受欢迎呢?
一方面,互联网可以获取的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,比如:
知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
淘宝:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
安居客:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
…
爬虫是入门 Python 的一种好方式
Python 有很多应用的方向,比如人工智能、web开发、数据分析等等
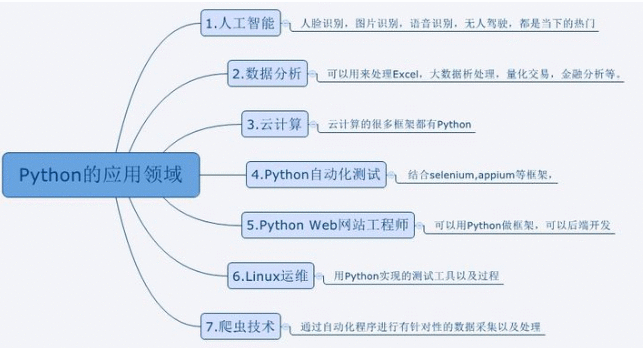
但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习 Python 数据分析、web 开发甚至机器学习,都会更得心应手。因为这个过程中,Python 基本语法、库的使用,以及如何查找文档你都非常熟悉了。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实也不难实现,这里给你分享一份零基础快速入门 Python 爬虫的学习资料。

本书籍分为基础篇、中级篇、深入篇,一共18个章节,436页。由浅及深地讲解了爬虫开发中所需的知识和技能。本书是一本适合初学者的书籍,既有对基础知识点的讲解,也涉及关键问题和难点的分析和解决。
基础篇
第1章 回顾 Python 编程
- 安装 Python
- 搭建开发环境
- IO编程
- 进程和线程
- 网络编程

第2章 Web前端基础

第3章 初识网络爬虫
- 网络爬虫概述
- HTTP 请求的Python 实现
- 小结

第4章 HTML 解析大法
- 初识Firebug
- 正则表达式
- 强大的 BeautifulSoup
- 小结

第5章 数据存储(无数据库版)
- HTML 正文抽取
- 多媒体文件抽取
- Email 提醒
- 小结
第6章 实战项目:基础爬虫
- 基础爬虫架构及运行流程
- URL 管理器
- HTML 下载器
- HTML 解析器
- 数据存储器
- 爬虫调度器
- 小结

第7章 实战项目:简单分布式爬虫

中级篇
第8章 数据存储 (数据库版)
- SQLite
- MySQL
- 更适合爬虫的MongoDB
- …

第9章 动态网站抓取
- Ajax 和动态 HTML
- 动态爬虫1:爬取影评信息
- PhantomJS
- Selenium
- 动态爬虫1:爬取去哪网
- …

第10章 Web 端协议分析
- 网页登录 POST 分析
- 验证码问题
- www>m>wap
- …
第11章 终端协议分析
- PC客户端抓包分析
- APP抓包分析
- API爬虫:爬取mp3 资源

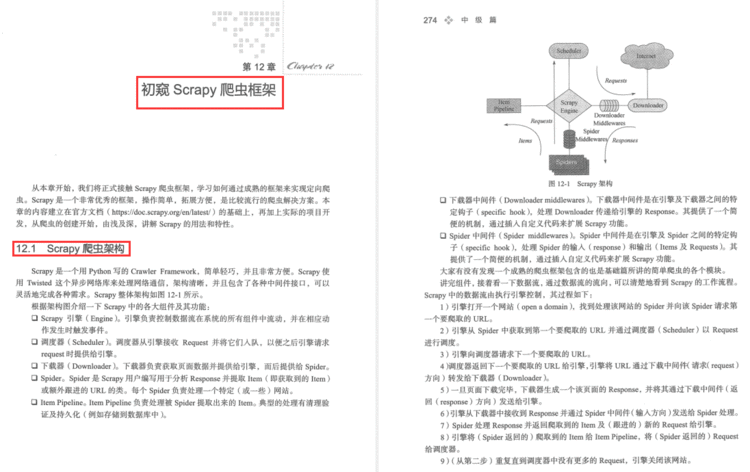
第12章 初窥 Scrapy 爬虫框架
- Scrapy 爬虫架构
- 安装 Scrapy
- 创建 cnblogs 项目
- 创建爬虫模块
- 选择器
- 命令行工具
- 定义 Item
- 翻页功能
- 构建 Item Pipeline
- 内置数据存储
- 内置图片和文件下载方式
- 启动爬虫
- 强化爬虫
- …
第13章 深入 Scrapy 爬虫框架
- 再看 Spider
- Item Loader
- 再看 Item Pipeline
- 请求与响应
- 下载器中间件
- Spider 中间件
- 扩展
- 突破反爬虫
- …


第14章 实战项目:Scrapy 爬虫
- 创建知乎爬虫
- 定义 Item
- 创建爬虫模块
- Pipeline
- 优化措施
- 部署爬虫
- …
深入篇
第15章 增量式爬虫
- 去重方案
- BloomFilter 算法
- Scrapy 与 BloomFilter
- …

第16章 分布式爬虫与Scrapy
- Redis 基础
- Python 和 Redis
- MongoDB 集群
- …
第17章 项目实战:Scrapy 分布式
- 创建云起书院爬虫
- 定义 Item
- 编写爬虫模块
- Pipeline
- 应对反爬虫机制
- 去重优化
- …

第18章 人性化 PySpider 爬虫框架
- PySpider 与 Scrapy
- 安装 PySpider
- 创建豆瓣爬虫
- 选择器
- Ajax 和 HTTP 请求
- PySpider 和 PhantomJS
- 数据存储
- PySpider 爬虫架构
- …

需要领取《Python爬虫开发与项目实战》的朋友可以扫描下方CSDN官方认证二维码,免费领取!

最后:学习任何一门语言都是从入门开始,通过不间断练习达到熟练,最终目标精通。虽然万事开头难,但好的开始是成功的一半,只要方向对了,就不怕路远。











 京公网安备 11010802041100号
京公网安备 11010802041100号