作者:艺卓显示、巴可投影 | 来源:互联网 | 2023-09-11 19:08
篇首语:本文由编程笔记#小编为大家整理,主要介绍了EdgeRec:边缘计算在淘宝推荐系统中的大规模应用相关的知识,希望对你有一定的参考价值。
导读:在全面进入无线的时代,为了解决信息负载的问题,越来越多的推荐场景得到兴起,尤其是以列表推荐形式为主的信息流推荐。以手淘信息流为例,进入猜你喜欢场景的用户,兴趣常常是不明确的,用户浏览时往往没有明确的商品需求,而是在逛的过程中逐渐去发现想买的商品。而推荐系统在用户逛的过程中,会向客户端下发并呈现不同类型的商品让用户从中挑选,推荐系统这个过程中会去捕捉用户的兴趣变化,从而推荐出更符合用户兴趣的商品。然而推荐系统能不能做到用户兴趣变化时立刻给出响应呢?
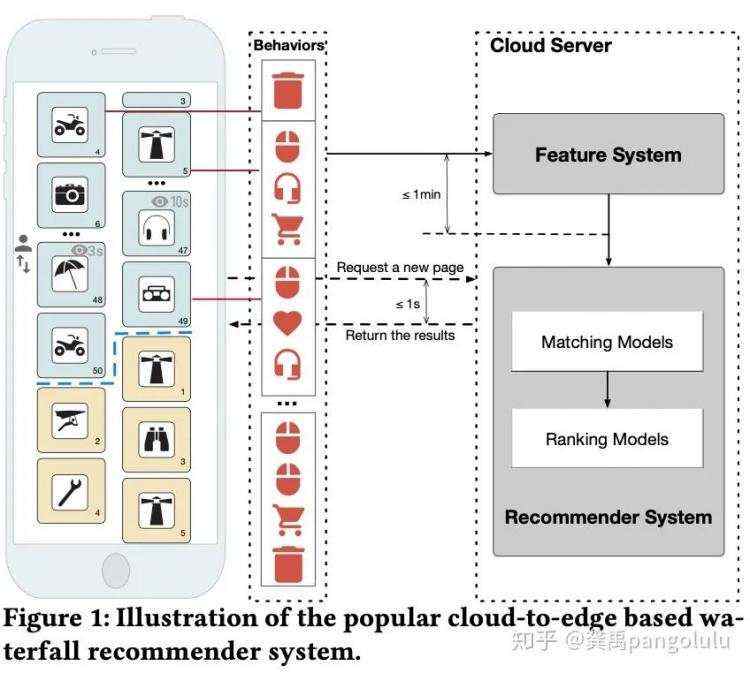
推荐系统以往的做法都是通过客户端请求 ( 分页请求 ) 后触发云端服务器的商品排序,然后将排序好的商品下发给用户,端侧再依此做商品呈现。这样存在下面两个问题:
推荐系统决策的延迟:由于云端服务器的QPS压力限制,信息流推荐会采用分页请求的方式,这样就会导致云端推荐系统对终端用户推荐内容调整机会少,无法及时响应用户的兴趣变化。如下图所示,用户在第4个商品的交互表明不喜欢“摩托车”,但是由于分页请求只能在50个商品后,那么当页后面其他“摩托车”商品无法被及时调整。
对用户行为的实时感知的延迟:目前推荐系统的个性化都是通过把用户与商品交互的行为作为特征来表达的,但是用户的行为其实是发生在客户端上的,推荐系统模型想要拿到用户的行为特征需要把端上数据下发到服务端,此时就会造成延迟的问题,如下图所示用户行为的延迟可能会达到1min。于此同时,由于网络带宽延迟的问题,其他大量的用户细节行为(如商品的实时曝光、用户的滑动手势等)是无法进行建模的。
02
边缘计算 + 推荐系统
边缘计算的优势,是让边缘节点 ( 这里指手机端上 ) 具备了"独立思考"的能力,这让部分决策和计算不再依赖于云端,端侧可以更实时、更有策略的给出结果。另外由于在端侧能够秒级感知用户意图做出决策,产品和用户贴的更近了,这催生了更多实时性的玩法,产品将不再局限于要到固定的时机如分页请求让云端去给到新的内容反馈,而是思考,当用户表达出来特定的用户意图时,产品应该如何提供与意图相匹配的内容。
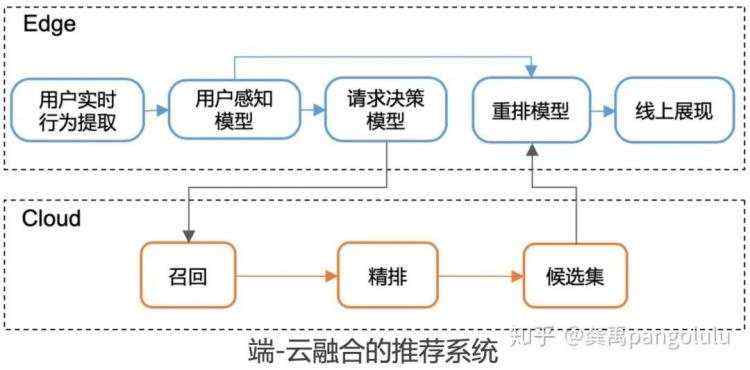
EdgeRec端上推荐系统便是借助于边缘计算的这种实时感知性和实时反馈性,来解决目前Client-Server架构推荐系统的实时感知、实时反馈能力不足的问题。EdgeRec推荐系统提供了端上用户意图感知、端上重排、端上实时插卡等能力。通过在端侧秒级感知用户意图做出决策,并提供与意图相匹配的反馈,提升用户的点击意愿与浏览意愿,整体改变瀑布流的体感。
03
EdgeRec:系统架构
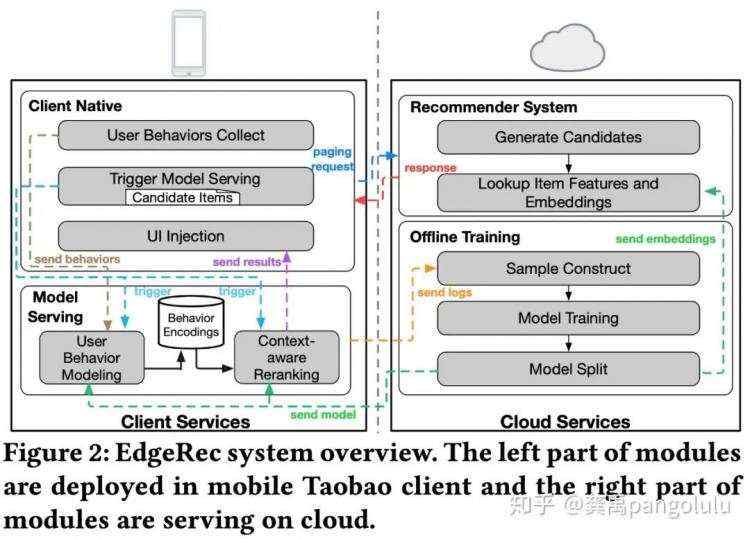
特点:1)手机端上本地重排,不影响服务端推荐链路,支持端上的热插拔;2)支持端上部署大规模深度神经网络。
端上部署大规模深度神经网络的挑战与方案:
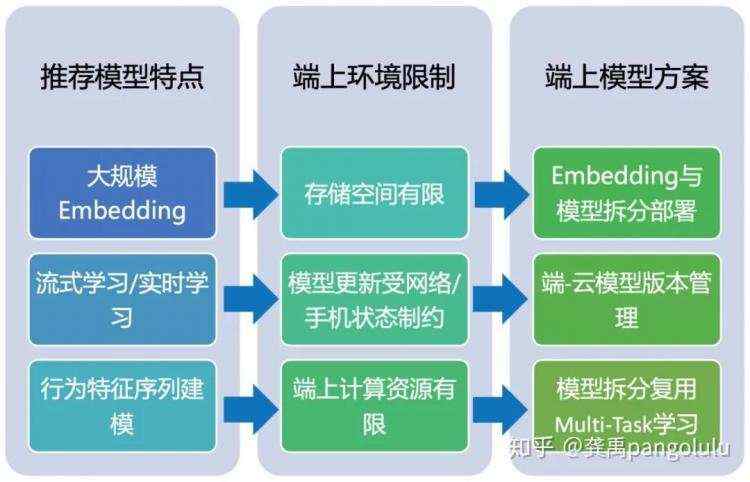
04
EdgeRec:端上算法模型
1. 概述
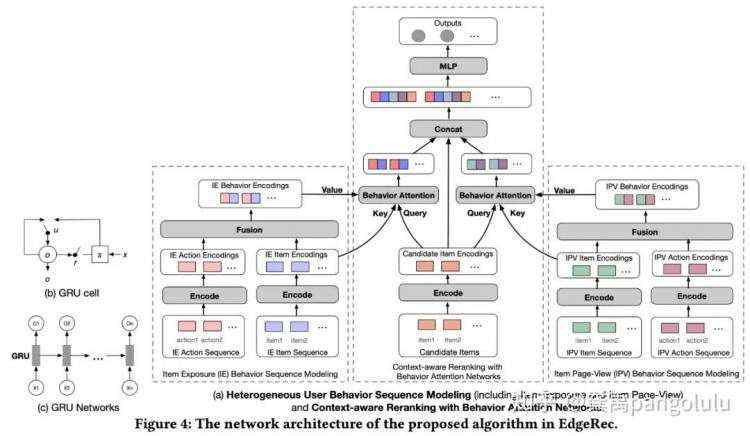
EdgeRec中端上的推荐算法模型主要包含了"端上实时用户感知"和"端上实时重排"两个模块。其中,"端上实时用户感知"被建模为Heterogeneous User Behavior Sequence Modeling,包含了"商品曝光行为序列建模 ( Item Exposure ( IE ) Behavior Sequence Modeling )"和"商品详情页行为序列建模 ( Item Page-View ( IPV ) Behavior Sequence Modeling )"两部分;"端上实时重排"被建模为Context-aware Reranking with Behavior Attention Networks ( CRBAN )。
2. 端上实时用户感知
① 意义
首先,在个性化搜索和推荐中,"千人千面"来源于特征的个性化,而"个性化"主要依赖于用户的行为数据,参考DIN等工作,它们都建模了用户最近交互的商品序列,作为个性化模型的输入。但是,前面的工作一般只考虑了用户和商品的"正反馈"交互 ( 如点击、成交 ),很少考虑到用户与商品的"负反馈"交互 ( 如曝光 )。确实,"正反馈"特征相对来说较为明确,噪声也相对较少;但是我们认为用户与商品实时的"负反馈"交互也很重要,举一个直观的例子来说:某一类目的商品实时地多次曝光后,该类目商品点击率会明显下降。
另外一方面,之前的"个性化模型"的工作一般只考虑了与用户"交互"的商品特征,这句话的中心词是"交互的商品"。但是,用户与商品的"交互动作"其实也很重要,比如:用户点击商品后再详情页的行为反应的是对这个商品真正的偏好,真实的数据里面可能存在"伪"点击的情况;同样地,如果用户对某个商品虽然没有点击,但是用户在这个商品上的曝光非常聚焦,也就是商品曝光的停留时长非常长,这种情况也不能绝对说明这个商品的曝光未点击代表了用户不喜欢,尤其在现在信息流推荐页面里面商品的图片展示越来越大,也会透出各种关键词,甚至可以自动播放视频,也许点击对于某些用户已经成为了非常"奢侈"的正反馈了。
最后,我们认为用户在推荐场景的"实时行为"也会非常重要,比如:用户实时点击了不喜欢等负反馈,或者某个类目实时多次曝光却不点击,这些都反映了当时用户的实时偏好,因此推荐系统需要具备实时建模用户偏好的能力,并及时作出调整。
② 实时行为特征体系
根据上文的分析,相比目前云端推荐算法的用户感知建模,端上实时用户感知要具备以下特点:
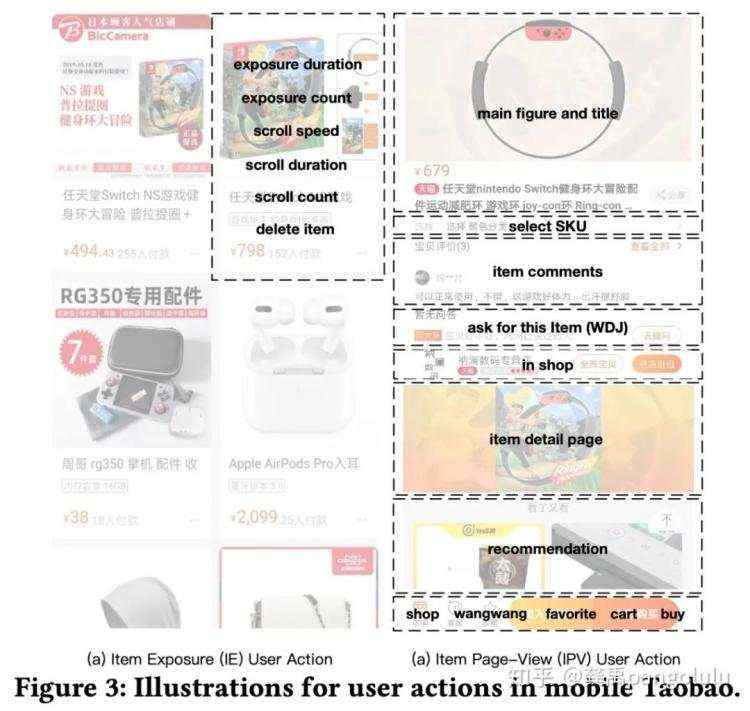
而这三个特点要靠端上特征来体现,基于以上的三个特点,我们设计了用于信息流推荐系统的端上实时用户行为特征体系。如下图所示,端上实时用户行为特征主要包含了:(a)"商品曝光行为"和 (b)"商品详情页行为"这两部分。
③ Heterogeneous User Behavior Sequence Modeling
这里有两方面的异构:
首先我们介绍一下模型输入的组织方式:
用户一个行为定义为一个 Pair <商品 (Item),动作 (Action)>,行为序列定义为 List (<商品(Item),动作(Action)>)
商品曝光行为序列 (Item Exposure (IE) Behavior Sequence),"商品"是一个曝光的商品,"动作"是用户在瀑布流对这个商品的交互动作,如曝光时长、滚动速度、滚动方向等
商品详情页行为序列 (Item Page-View (IPV) Behavior Sequence),"商品"是一个点击的商品,"动作"是用户在详情页对这个商品的交互动作,如停留时长、是否加购、是否收藏等。
上面的模型图中包含了我们对Heterogeneous User Behavior Sequence Modeling的网络结构图的框架,这里重点说明两点:
"商品曝光行为序列 ( IE Behavior Sequence )"和"商品详情页行为序列 ( IPV Behavior Sequence )"先分别单独进行建模,最后再进行融合 ( 如果需要的话 )。这里主要考虑的是点击行为一般比较稀疏,而曝光行为非常多,如果先融合成一条行为序列再建模的话,很可能模型会被曝光行为主导。
商品特征 ( Item ) 和行为动作特征 ( Action ) 先分别Encode后,再进行Fusion。这里主要考虑的是商品特征和行为动作特征属于异构的输入,如果下游的任务需要对具体的商品进行Attention的话,只有对同构的输入Attention才会有意义,后面讲到端上重排模型的时候会再重点说一下这个问题。
这里,商品特征序列 ( 包括IE Item Sequence和IPV Item Sequence ) 使用GRU网络进行Encode,动作特征序列 ( 包括IE Action Sequence和IPV Action Sequence ) 直接使用Identity函数进行Encode。商品序列Embedding ( 包括IE Item Embedding和 IPV Item Embedding ) 和动作序列Embedding ( 包括IE Action Embedding和 IPV Action Embedding ) 的Fusion采用简单的Concat操作,得到行为序列Embedding ( 包括IE Behavior Embedding和IPV Behavior Embedding )。
3. 端上重排
① 意义
端上重排是端上推荐的基础,拥有实时改变商品推荐顺序的能力,可以把端上重排看做用户Local域的推荐优化,也就是在当页推荐结果内进行优化。端上重排依托于实时用户感知,根据实时的正 / 负反馈 ( 曝光、详情页 ) 和更细节的用户行为特征,在信息流里面不断地对待排序商品进行重新排序,真正做到信息流的实时感知+实时推荐。
重排序这个任务无论在搜索还是推荐领域其实都有很多前人的工作,这些工作的核心点其实就是context-aware ranking,这里的context指的是待排序商品之间的上下文,对context的建模可以多种多样,比如:RNN,Transformer,或者人工定义全局特征+DNN。
EdgeRec中端上实时重排也基于context-aware ranking的基础,但是这里的context不仅仅包含待排序商品之间的上下文,还包含了用户实时行为 ( 实时曝光商品、实时点击商品、用户交互行为 ) 的上下文。通过这些上下文信息,实时重排可以做到:我知道已经排了啥,也知道用户在前面排序上的行为,给我一个待排序的商品上下文,如何排可以达到最优。下面重点介绍端上重排的模型框架,我们称作 Context-aware Reranking with Behavior Attention Networks ( BAN )。
② Context-aware Reranking with Behavior Attention Networks
上面的模型图中包含了我们对Context-aware Reranking with Behavior Attention Networks的网络结构图的框架。在背景中已经说过,端上实时重排考虑了两种上下文信息,对待排序商品之间的上下文建模我们依旧采用常用的序列建模的方法,引入GRU网络对商品集合进行Encode;为了考虑到用户实时行为的上下文,这里依旧采用了常用的方法,其实就是Attention ( 有时也被称作target attention )。回忆一下实时用户感知里面,异构行为序列建模的输入:用户一个行为定义为一个 Pair <商品,动作>,行为序列定义为 List (<商品,动作>),其中"商品"指的是用户与之交互的商品,"动作"指的是用户和商品交互的动作。从上面网络图中可以看到,Attention作用在待排序商品和行为序列的商品上,其实也就是商品与商品之间。熟悉Attention的同学应该知道 (Query, Key, Value) 这个三元组,这个模型里面Query是待排序商品的Encode结果 ( Candidate Item Embedding ),Key是行为序列的商品的Encode结果 ( 包括IE Item Embedding和IPV Item Embedding ),Value是行为序列Fusion后的Embedding结果 ( 包括IE Behavior Embedding和IPV Behavior Embedding )。用大白话描述一下motivation:对待排序商品集合里某一个商品来说,先看看用户交互过的商品都长啥样,重点关注下特征相似的商品,于此同时,再看看用户在这些商品上的表现是啥,综合起来都作为这个商品排序的参考。
05
实验效果
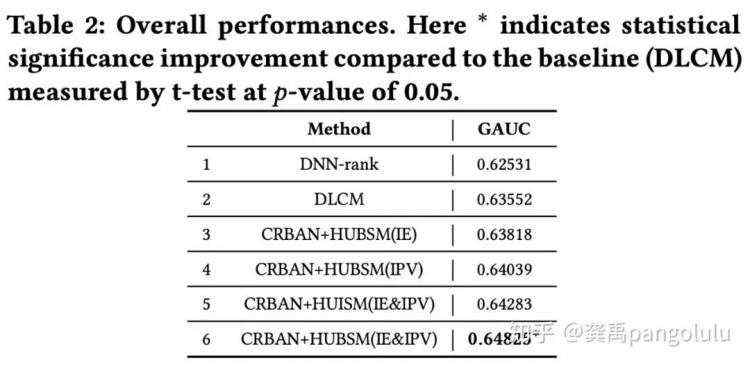
1. 离线实验
2. 在线实验
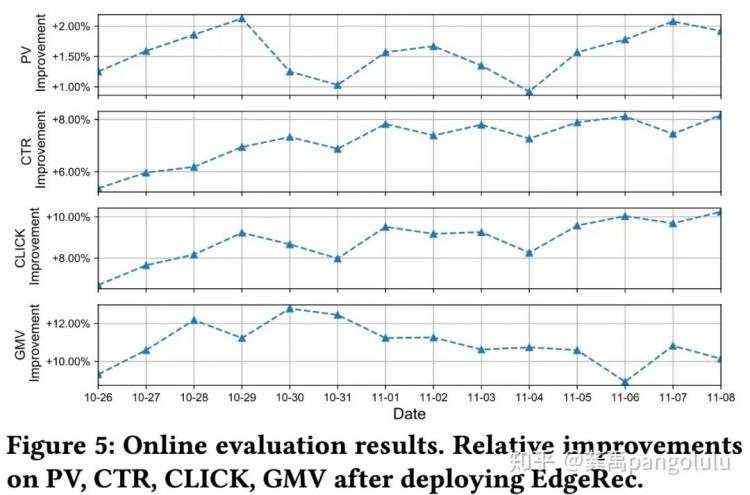
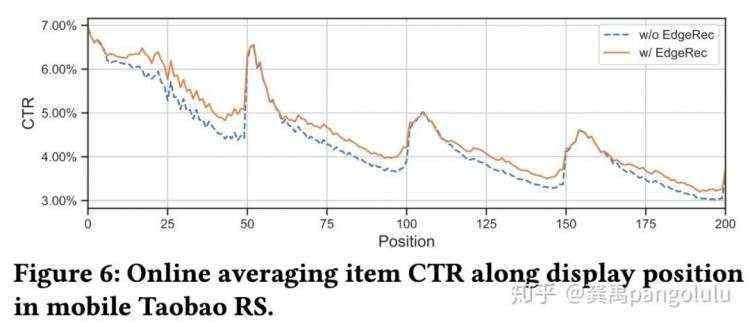
双十一当天,EdgeRec推荐系统提供了点击导向和成交导向的端上重排功能。在淘宝首页猜你喜欢运行5亿次,相对于不开启EdgeRec,点击导向的端上重排商品点击量提升10%,成交导向的端上重排成交金额提升5%。EdgeRec对商品推荐的准确度提升,对用户意图的反馈更加及时,其最好的体现是信息流分页尾部卡片的点击率有大幅提升。
06
总结
EdgeRec是推荐算法在边缘计算方向的第一次小试牛刀,从拿到的业务效果上来看其发展空间是非常巨大的。通过利用端侧计算的能力,深度模型可以在端上做预测,通过端上模型运行来弥补云上实时行为获取困难、策略实时调整能力弱的问题。另外,端侧计算能力不仅可以用于模型预测,还可以考虑在端上做训练,为每个用户训练其个体模型,为端侧智能带来更大的空间。
本文发表于CIKM 2020 Applied Research Track,今天的分享就到这里,谢谢大家。
https://arxiv.org/pdf/2005.08416.pdf
作者介绍:
龚禹 ( 花名:凛至 ),2017年硕士毕业于上海交通大学,现任阿里巴巴搜索推荐事业部算法专家,曾在SIGIR、KDD、AAAI等发表多篇论文,其中IRGAN曾获SIGIR2017最佳论文提名。研究方向包括了推荐系统与自然语言处理等,目前专注于边缘计算与推荐系统的结合,主导的EdgeRec系统已经在手淘推荐场景大规模落地。
https://www.zhihu.com/people/pangolulu
在文末分享、点赞、在看,给个三连击呗~~
社群推荐:
欢迎加入 DataFunTalk 推荐算法交流群,跟同行零距离交流。如想进群,请识别下面的二维码,根据提示自主入群。
文章推荐:
关于我们:


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号