作者:帅哥不潮_460 | 来源:互联网 | 2023-09-07 21:24
篇首语:本文由编程笔记#小编为大家整理,主要介绍了SPARK中 会对Scan的小文件做合并到一个Task去处理么?相关的知识,希望对你有一定的参考价值。
背景
本文基于SPARK 3.1.2
在之前查看SQL物理计划的时候,发现一个很奇怪的现象,文件的个数很多,但是启动的Task却很少。
结论
SPARK在scan文件的时候,会把小文件合并到一个Task上去处理。
分析
这里的SQL很简单:就是select col from table语句我们直接查看对应的计划:
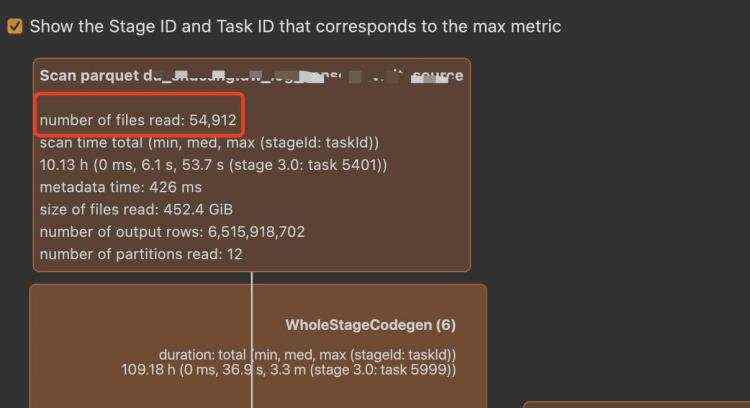

可以看到对于有50000多个文件的source,最终却只有6000多个任务运行。
我们直接看对应的代码FileSourceScanExec实现:
val splitFiles = selectedPartitions.flatMap partition =>
partition.files.flatMap file =>
// getPath() is very expensive so we only want to call it once in this block:
val filePath = file.getPath
val isSplitable = relation.fileFormat.isSplitable(
relation.sparkSession, relation.options, filePath)
PartitionedFileUtil.splitFiles(
sparkSession = relation.sparkSession,
file = file,
filePath = filePath,
isSplitable = isSplitable,
maxSplitBytes = maxSplitBytes,
partitionValues = partition.values
)
.sortBy(_.length)(implicitly[Ordering[Long]].reverse)
val partitions =
FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes)
new FileScanRDD(fsRelation.sparkSession, readFile, partitions)
PartitionedFileUtil.splitFiles就是对每个文件进行遍历,如果一个文件超过了maxSplitBytes,这个可以参考Spark-读取Parquet-为什么task数量会多于Row Group的数量,就进行切分,否则就直接返回整个文件,
关键的在FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes):
...
partitionedFiles.foreach file =>
if (currentSize + file.length > maxSplitBytes)
closePartition()
// Add the given file to the current partition.
currentSize += file.length + openCostInBytes
currentFiles += file
...
她会根据maxSplitBytes来判断,如果文件小于该阈值,就会放到同一个FilePartition中,从而让一个Task去处理,这样就会出现了图上所展示的小文件很多但是Task缺比较小的现象。

![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号