我正在运行一个简单的3节点kafka和5个节点zookeeper来运行kafka,我想知道哪个是备份我的好方法kafka,同样适合我zookeeper.
目前我只是将我的数据目录导出到s3存储桶......
谢谢.
Zalando最近发表了很好的文章,如何备份Kafka和Zookeeper.通常,Kafka备份有两条路径:
维护第二个Kafka集群,所有主题都可以复制到该集群.我还没有验证这个设置,但如果还复制了偏移主题,那么切换到另一个集群不应该损害消费者的处理状态.
将主题转储到云存储,例如使用S3连接器(如Zalando所述).如果还原,您可以重新创建主题并使用云存储中的数据提供主题.这将允许您进行时间点恢复,但消费者必须从头开始阅读主题.
首选备份解决方案取决于您的使用案例.例如,对于流应用程序,第一种解决方案可能会减少您的痛苦,而当使用Kafka进行事件采购时,第二种解决方案可能更为理想.
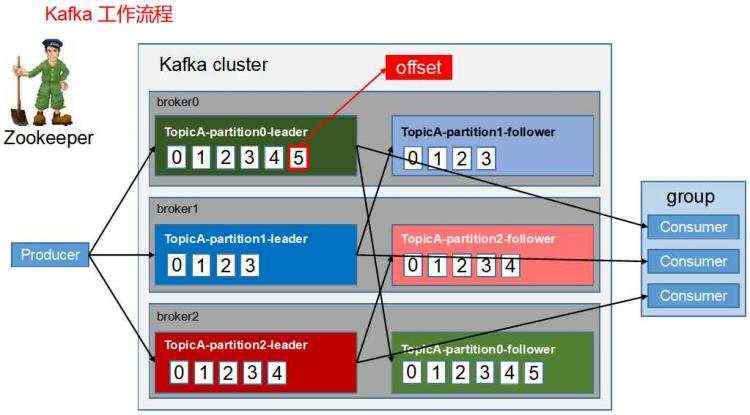
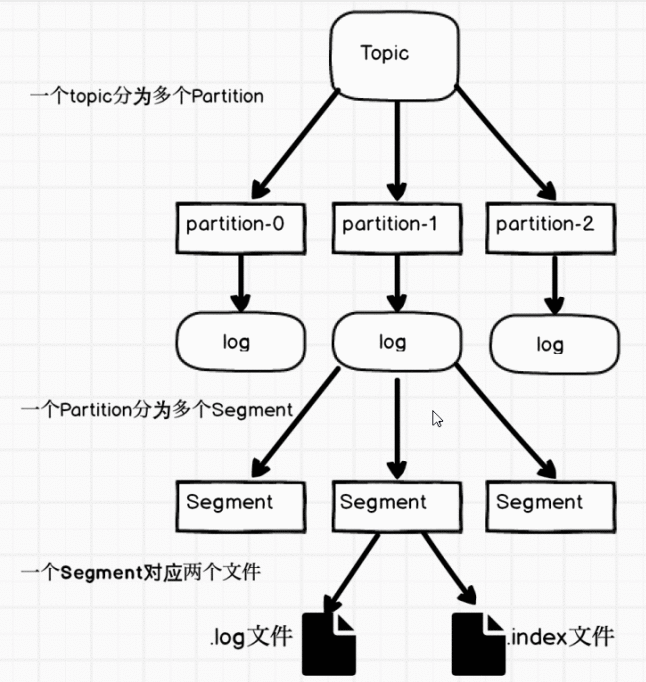
关于Zookeeper,Kafka保留有关主题(持久存储)以及经纪人发现和领导者选举(短暂)的信息.Zalando决定使用Burry,它简单地遍历Zookeeper树结构,将其转储到文件结构,然后将其压缩并推送到云存储.它遇到了一个小问题,但很可能它不会影响Kafka持久数据的备份(TODO验证).Zalando在那里描述,在恢复时,最好首先创建Zookeeper集群,然后将新的Kafka集群连接到它(使用新的唯一代理ID),然后恢复Burry的备份.Burry不会覆盖现有节点,也不会提供有关旧代理的短暂信息,以及备份中存储的内容.
注意:尽管他们提到参展商的使用情况,但在备份Burry时并不需要备份.





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 