
本文适合人群:对机器学习Machine Learning与数据感兴趣的学习者
温馨提示:阅读本文之前,需对以下内容进行了解并掌握
白话ML:什么是机器学习模型?ML Model
白话ML(7):人类最好理解的预测模型-决策树Decision Tree
白话ML(3):理解机器学习中的Bias与Variance
本文白话什么:
用户精细化管理用的K-means聚类分析
本文提纲:
Naive Bayes的元素
Naive Bayes的分类判断过程
弥补贝叶斯分类模型的缺陷
优质or幼稚的模型?
注:全文无编程,只含有少量计算,文章内容全部尽量通俗易懂化,请尽情享用。
写在前面
在之前的白话ML系列,介绍了一些Tree-based model,不仅预测效果出色,而且还可能够做到explainable。这一期我们回归本真,介绍一些在机器学习课程中教授们会在最开始就介绍的模型:naïve Bayes,幼稚的贝叶斯模型。
Naive Bayes的元素
建立贝叶斯模型的几个重要元素,这些重要因素解释起来会比较的生涩我之后会在一个例子中进行讲解,他们分别是Posterior、evidence、likelihood以及prior。下图是贝叶斯的核心思想,上述的四个元素分别对应下面的部分。贝叶斯统计与传统统计学的思想完全不一样,有兴趣大家可以自行学习,我会用一个例子来解释上述公式在naïve bayes应用中的作用。

Naive Bayes的分类判断过程
进入一个典型的例子来进行解释:我们希望使用贝叶斯模型对于垃圾邮件spam mail与正常邮件进行分类。在建立模型之前,我们首先先会拥有一个对于邮件分类的训练集模型,即变量是每封邮件中的单词,target value是邮件的属性(spam or normal)。那么注意了,在这里每封邮件的变量单词就是贝叶斯公式中的x即证据(evidence),target value就是我们公式中的C也叫做参数,参数是分布的属性,也就是spam or normal。

下一步,我们要计算likelihoods,什么是likelihoods?就是在每一种参数(邮件类别)中,不同证据evidence(单词)出现的概率是多少。例如下图,我们将所有的normal email全部挑选出来,并且将所有email中的单词进行统计,假设我们所有的normal email只有4个单词(Dear、Friend、Lunch、Money),每个单词出现的频率如下图所示,那么我们可以根据条件概率算出下图中每一个单词在两个类别邮件中的likelihood。
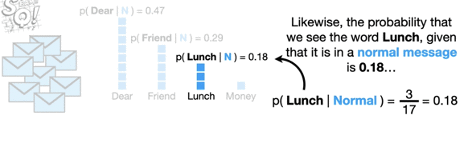
在全部的8封普通normal邮件中,总共有17个词出现,每一个单个单词出现的频率不同,用单个出现频率除以总单词量得到每一个变量的likelihood。在spam的4封邮件里以此类推。
在得到likelihood之后,我们开始计算prior,英文中prior是“先前”的意思,也就是在没有看到evidence之前,我们能够判断的normal以及spam邮件的概率,这个概率直接通过两种邮件的数量以及总邮件数构成。
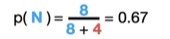

总共有12封邮件(作为训练集),普通的normal邮件有9封,spam垃圾邮件有4封,所以不同参数(属性)的Prior就是0.67和0.33.
在通过训练数据集得到了likelihood、prior之后,我们就要开始探究贝叶斯分类模型究竟是如何进行分类的。加入我们收到一封邮件里面的文字是Dear和Friend。那么对于这条record来说,模型将如何分类呢?这就需要回到我们最上边的贝叶斯公式
我们需要做的就是将两个邮箱类型下的分子进行计算,然后进行对比即可,因为evidence(邮箱里出现的文字)都是一样的,所以分母可以忽略。通过计算得到以下的两个数字。
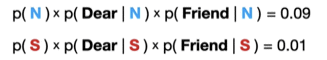
得到的两个数字其实就可以表示P(C|X),即在有一定的证据evidence(单词)出现的条件下,是正常邮件的概率,以及是垃圾邮件的概率。两个数值谁大,模型就选谁。最终,在这个例子下,模型会选择将这个邮件分类为正常邮件。
弥补贝叶斯模型缺陷
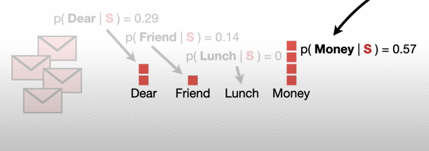
以上就是贝叶斯分类模型进行分类的过程,但是文章到这里还并没有结束,上述的分类过程会有一个很大的缺陷,比如当所收到邮件内容为Lunch,Money,Money,Money,Money时,我们通过直接很容易能够判断出这封邮件应该为Spam垃圾邮件,因为邮件中的Money非常多,而在垃圾邮件中P(Money | S)这个likelihood又特别大,所以模型应该将其分类成Spam。
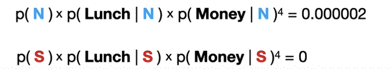
但是问题来了,通过上面这幅图的计算,我们可以看到因为在Spam垃圾邮件中,P(Lunch | S)这个likelihood为0,所以只要邮件中“Lunch”这个单词出现,那么得到的P(Spam|X)的去分母数值就会为0,这个分数一定是会比P(Normal |X)小,那么模型就不会将邮件分类为垃圾邮件,这是个大大的Bug啊!
如何消除这个Bug进而优化模型呢?这里我们引入模型参数alpha(α)。如下图所示,我们设置为α=1就是将每一个单词的数量都增加1,来保证P(Lunch | S)这个likelihood不为0。如下图所示,将每个单词数量增加1,并重新对likelihood进行计算。

接着,我们可以通过更新后的likelihood来计算最终的得分,很显然,在调整了α=1之后,贝叶斯模型很好的将Lunch,Money,Money,Money,Money识别为了spam垃圾邮件。
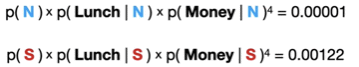
幼稚还是优质?
Naive Bayes在上述的分析过程中看起来确实非常幼稚,它无视了单词的顺序以及关系问题,也不会像NLP一样探究每个单词的情感倾向,它只是通过最简单的贝叶斯统计的原理,对于训练数据进行公式中参数的计算,然后将这些参数应用于新的数据中进行分类。
但是正是因为他的优质,贝叶斯分类会能够很好的应用于实践中,因为贝叶斯模型的表现具有很低的variance。保证应用场景之间没有太大偏差。所以从这个角度来说,Naive Bayes还是个相对优质的模型
本文参考信息来源:
SateQuest
---------------------
PS:有任何疑问欢迎留言,本文完全个人浅薄理解,如有不足欢迎评论区指正。
我是杜吉普,致力于 数据+数据技术+商业场景=商业价值
欢迎关注我,让我们共同持续成长。









 京公网安备 11010802041100号
京公网安备 11010802041100号