作者:卍扯淡的爱卍_989 | 来源:互联网 | 2024-11-28 10:10
本文将详细介绍如何在 APOC 库中使用路径查询功能,如果你对 APOC 不熟悉或不清楚如何安装,建议先阅读《APOC 是什么》这篇文章。本文将以查询光伏组件的上下游关系为例,展示如何利用 APOC 进行高效的数据挖掘。数据模型基于以下示例图: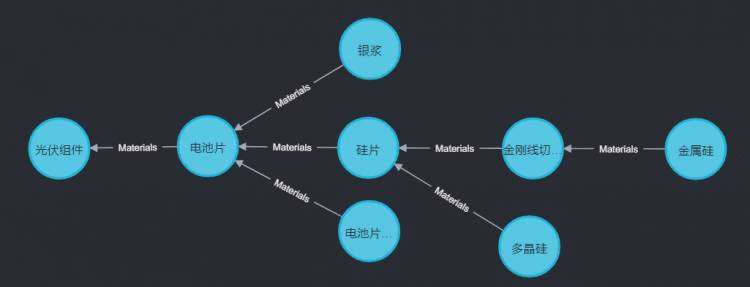 在该模型中,`MaterialsRelationship` 类型用于表示材料之间的关系,其定义如下:
在该模型中,`MaterialsRelationship` 类型用于表示材料之间的关系,其定义如下:@Data
@RelationshipEntity(type = "Materials")
public class MaterialsRelationship {
@Id
private String uuid;
/**
* 起始节点
*/
@StartNode
private ProductEntryNode startNode;
/**
* 终止节点
*/
@EndNode
private ProductEntryNode endNode;
}
假设我们需要查询光伏组件的上游关系,包括 `Materials`、`Manufacture` 和 `Technology` 类型的关系。已知光伏组件的 ID,我们可以在 DAO 层编写如下 Cypher 查询语句:@Query(" match path=(p:ProductEntry)-[r:Materials|Manufacture|Technology*1..]->(pp)" +
" where p.productEntryId={productEntryId}" +
" return path")
List getProductEdgesList(String productEntryId);
此查询将返回光伏组件的所有上游路径和节点。然而,Cypher 中使用 `*1..` 表示路径长度无限大是不允许的,除非你能确保路径长度不超过 6(这是 Neo4j 的推荐值)。因此,可以考虑通过动态参数传递路径长度:@Query(" match path=(p:ProductEntry)-[r:Materials|Manufacture|Technology*1..{level}]->(pp)" +
" where p.productEntryId={productEntryId}" +
" return path")
List getProductEdgesList(String productEntryId, int level);
不幸的是,Cypher 并不支持这种方式传递参数。不过,Neo4j 开发团队已经为此提供了解决方案,即使用 APOC 函数 `apoc.path.expand`。该函数允许动态设置路径的最大长度,具体用法如下:apoc.path.expand(start :: ANY?, relationshipFilter :: STRING?, labelFilter :: STRING?, minLevel :: INTEGER?, maxLevel :: INTEGER?) :: (path :: PATH?)
- start:起始节点,可以是任意类型。
- relationshipFilter:关系类型,多个类型用 | 分隔(STRING)。
- labelFilter:标签过滤(STRING)。
- minLevel:最小路径长度(INTEGER)。
- maxLevel:最大路径长度(INTEGER)。
- path:返回的路径结果。
通过 `maxLevel` 参数,我们可以动态设置路径的最大长度。在 DAO 层,可以这样编写查询:@Query("match (p:ProductEntry) where p.productEntryId={productEntryId}" +
" call apoc.path.expand(p,' " return path")
List getProductEdgesList(String productEntryId, int level);
其中,`'(p)-[r:Materials]->(pp:ProductEntry)-[r:Materials]->(ppp:ProductEntry)
如果要查询下游数据,可以指定方向为 `'>``,例如:@Query("match (p:ProductEntry) where p.productEntryId={productEntryId}" +
" call apoc.path.expand(p,'Materials>|Manufacture>|Technology>','',1,{level}) yield path" +
" return path")
List getProductEdgesList(String productEntryId, int level);
此外,还可以使用标签过滤器来指定遍历的终止条件。例如,如果希望在遇到包含 `Engineering` 标签的节点时终止遍历,可以使用 `/Engineering`:@Query("match (p:ProductEntry) where p.productEntryId={productEntryId}" +
" call apoc.path.expand(p,'Materials>|Manufacture>|Technology>','/Engineering',1,{level}) yield path" +
" return path")
List getProductEdgesList(String productEntryId, int level);
使用 `'(p)-[r:Materials]->(pp:Engineering)-[r:Materials]->(ppp:Engineering)
本文主要介绍了 `apoc.path.expand` 函数的使用方法,包括如何动态设置最大路径长度 `level` 以及其他参数的详细说明。需要注意的是,`start` 参数不仅可以是单个节点,也可以是 ID 或列表,这些扩展用法留给读者自行探索。总之,APOC 函数提供了强大的路径查询能力,尤其是在 Cypher 无法解决某些复杂查询时,APOC 提供了更加灵活的解决方案。- 本期完 -
如有疑问,请点赞,我会及时回复。由于微信公众号留言功能受限,您可以通过公众号聊天直接提问,我将在下期文章末尾回答您的问题。为方便获取最新内容,记得关注哦! 






 京公网安备 11010802041100号
京公网安备 11010802041100号