作者:王狄烽、张清恒
本期《自然语言处理与信息检索国际论文研讨会暨AIS2019(ACL、IJCAL、SIGIR)论文报告会》(简称AIS2019)由中文信息学会、杭州钱塘新区管委会主办,搜狗杭州研究院承办,于2019年5月25日-5月26日,在位于大创小镇的国际创博中心举办。
本次研讨会邀请了将在ACL、IJCAL、SIGIR2019三大会议上进行报告的论文进行提前预讲,讨论的范围包括“对话生成”、“阅读理解”、“检索与推荐”、“机器学习与表示”、“机器翻译”、“文本生成”、“信息抽取与情感分析”七个部分,共计59篇论文报告。报告中频繁出现的 核心词 包括: Attention 、 GNN 、 BERT 等。
在正式论文报告之前,研讨会首先进行了AIS发展趋势报告,由来自清华大学的刘知远老师、北京大学的严睿老师、清华大学的马为之老师分别进行了ACL趋势综述、IJCAL趋势综述、SIGIR趋势综述,分别对这三个会议的走向进行了介绍,下面我主要介绍一下刘知远老师汇报的ACL发展趋势内容。
ACL发展趋势报告
ACL发展趋势报告内容总结起来有一下三点:
- 1)NLP黄金时代:投稿量剧增(2019年1609长文,1085短文,1610审稿人,230AC,长文录用率25%)
- 2)投稿热门领域基本与2018一致,前三为:Information Extraction(9%)、Machine Learning(8%)、Machine Translation(8%),同时以下领域相比2018有了明显的提升:Linguistic Theories, Cognitive Modeling and Psycholinguistics
- 3)ACL趋势总结:预训练语言模型、低资源NLP任务、模型可解释性、更多任务&数据集
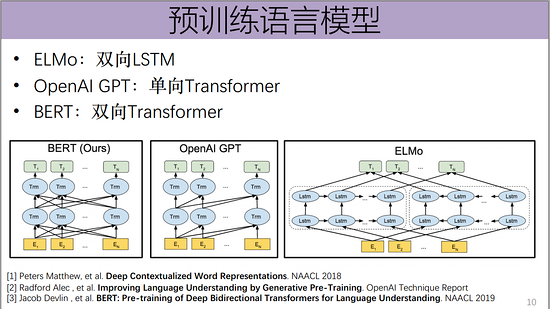
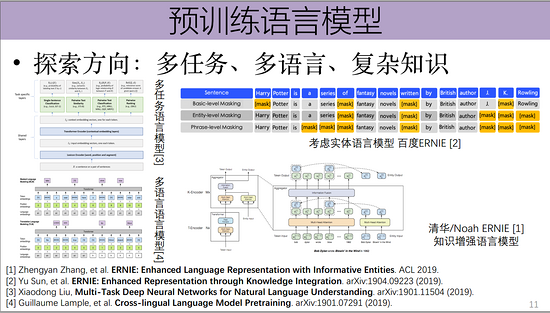
2018年深度学习的一个重大进展,即以ELMo、GPT、BERT为代表的预训练语言模型的重大突破,从2013年使用word2vec从大规模无监督文本中学习词向量,简单的刻画单词之间的语义关系(未考虑一词多义、无法建模复杂语境)到ELMo等通过预训练语言模型产生上下文相关的词向量。预训练语言模型仍有大量可探索的内容:多任务、多语言、复杂知识等。

针对现有自然语言任务中缺乏标记数据的情况,通过迁移学习、元学习、半监督学习等方向探索少样本学习。

在可解释性方向,报告主要提到了三点:1、对抗样本攻击2、如何在推理中考虑常识知识3、结合知识图谱与文本进行推理。
更多任务,多语言自然语言推理、多语言问答、文档级别关系抽取(带推理信息)。
下面介绍一些会场报告。
DocRED: A Large-Scale Document-Level Relation Extraction Dataset
主讲人:清华大学 姚远
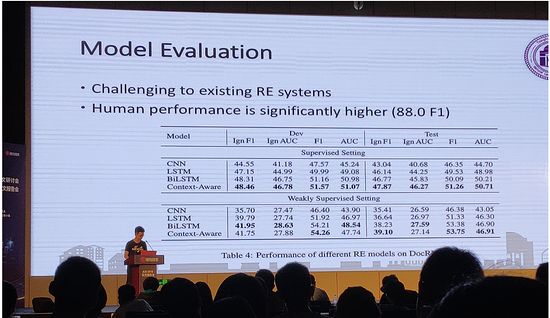
该篇论文针对现有关系抽取数据集只进行句子级别的关系抽取,构建了文档级别的关系抽取数据集(据统计,大约42.2%的实体关系出现在多个句子中),并且注重文档中实体关系的推理。在该DocRED数据集中,标注了实体、实体之间关系、支持该关系的证据数量、以及相应的文档。其数据构建的步骤大致分为四步:1、使用远程监督对wikipedia文档进行初始标记并筛选(保留实体数量多的文档)2、标记文档中的实体及其指代信息3、进行实体链接(link to wikidata items)4、标注实体之间的关系及相关的证据。针对文档中存在的大量实体对,为提高标记效率,其标记流程如下:1、机器自动推荐(使用现有的关系抽取模型)2、crowd-worker修正3、experienced crowd-worker修正。其数据规模及评估结果如下所示:
Joint Type Inference on Entities and Relations via Graph Convolutional Networks
主讲人: MSRA 孙长志
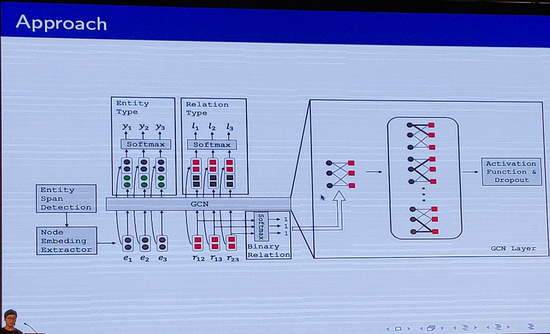
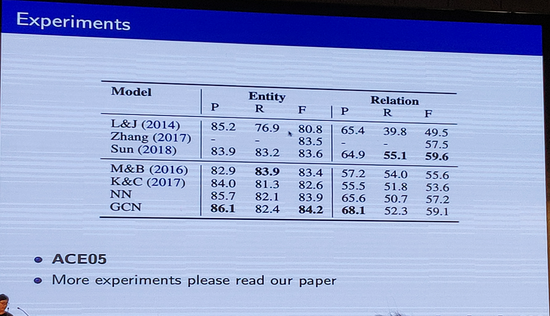
该篇论文主要做实体和关系的联合抽取,其动机如下:1、加强实体和关系之间模型的交互2、抽取更多更丰富的特征(实体-实体特征、实体-关系特征、关系-关系特征)而不是设计复杂的联合推理。其构建Entity-Relation Graph,将每一个实体和关系转为图中节点,将关系节点和相应的两个实体连边,构建了实体-关系图。在构建了实体-关系图的基础上,其框架主要流程如下:1、Entity span detection 2、Node Embedding Extractor 3、GCN based Entity type and Relation Type Inference。其最终在ACE05数据集上取得了state-of-the-art结果。 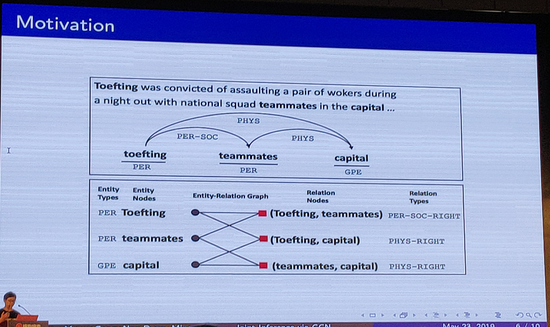
Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs
主讲人:北京大学 吴雨婷
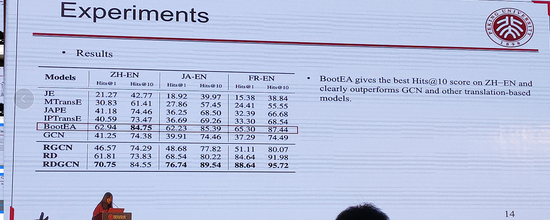
该论文旨在解决知识图谱中的实体对齐问题,为了能够捕获复杂的语义信息,作者提出了一种关系敏感式对偶图卷积网络(Relation-aware Dual-Graph Convolutional Network, RDGCN)模型。
首先,基于原始的图结构构建对偶关系图;然后,通过原始attention层和对偶attention层进行迭代;接着,通过GCN网络进一步结合结构信息;最后,得到实体的向量表示,用于实体对齐任务。
该论文的实验部分采用了JAPE[]的数据集DBP15K,主要对比方法有MTransE、JAPE、IPTransE、BootEA和GCN-Align,该论文所提出的方法RDGCN取得了相对较优的结果。











 京公网安备 11010802041100号
京公网安备 11010802041100号