问题:实现一个简单的垃圾短信过滤功能以及骚扰电话拦截功能,该用什么样的数据结构和算法实现呢?
如果号码不在黑名单,可以通过预设规则来过滤:
短信中包含特殊单词(或词语),比如一些非法、淫秽、反动词语等;
短信发送号码是群发号码,非我们正常的手机号码,比如+60389585;
短信中包含回拨的联系方式,比如手机号码、微信、QQ、网页链接等,因为群发短信的号码一般都是无法回拨的;
短信格式花哨、内容很长,比如包含各种表情、图片、网页链接等;
符合已知垃圾短信的模板。垃圾短信一般都是重复群发,对于已经判定为垃圾短信的短信,我们可以抽象成模板,将获取到的短信与模板匹配,一旦匹配,我们就可以判定为垃圾短信。
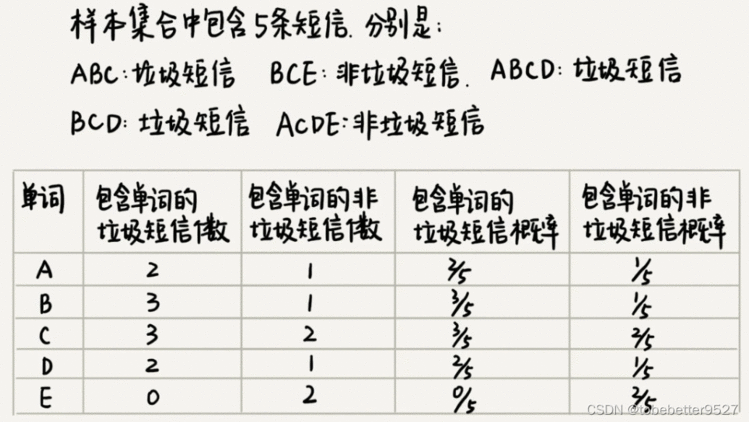
何定义特殊单词?概率统计。
假设事件A是“小明不去上学”,事件B是“下雨了”。现在统计了一下过去10天的下雨情况和小明上学的情况,作为样本数据。
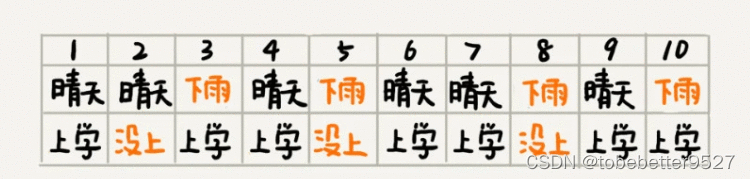
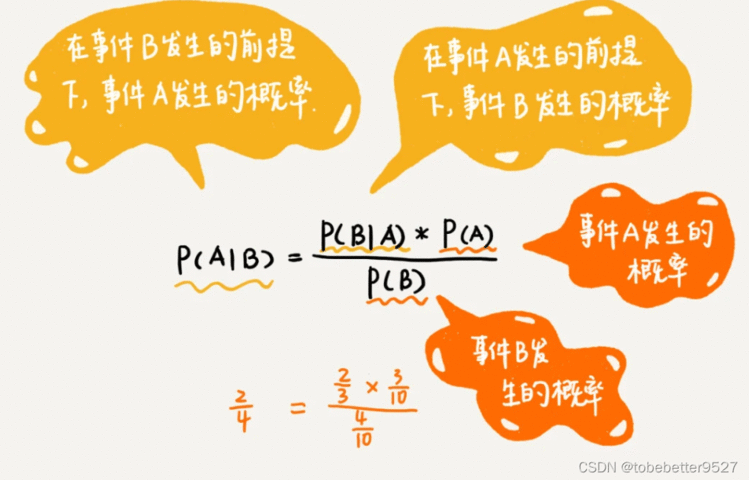
规律:在这10天中,有4天下雨,所以下雨的概率P(B)=4/10。10天中有3天,小明没有去上学,所以小明不去上学的概率P(A)=3/10。在4个下雨天中,小明有2天没去上学,所以下雨天不去上学的概率P(A|B)=2/4。在小明没有去上学的3天中,有2天下雨了,所以小明因为下雨而不上学的概率是P(B|A)=2/3。
公式表达:
计算机没办法像人一样理解短信的含义,需要把短信抽象成一组计算机可以理解并且方便计算的特征项,用这一组特征项代替短信本身,来做垃圾短信过滤。
通过分词算法,把一个短信分割成n个单词。这n个单词就是一组特征项,全权代表这个短信。
使用概率,来表征一个短信是垃圾短信的可信程度。公式如下:
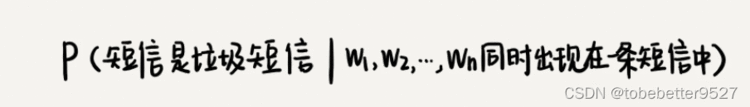
实际没法通过样本数据统计得到这个概率。
朴素贝叶斯公式:

P(W1W_{1}W1,W2W_{2}W2,W3W_{3}W3,…,WnW_{n}Wn同时出现在一条短信中 | 短信是垃圾短信)这个概率照样无法通过样本来统计得到。通过以下公式计算:
独立事件发生的概率计算公式:P(A*B) = P(A)*P(B)如果事件A和事件B是独立事件,两者的发生没有相关性,事件A发生的概率P(A)等于p1,事件B发生的概率P(B)等于p2,
那两个同时发生的概率P(A*B)就等于P(A)*P(B)。
基于上面的公司,得到如下:

其中,P(WiW_{i}Wi出现在短信中 | 短信是垃圾短信)表示垃圾短信中包含WiW_{i}Wi这个单词的概率有多大。这个概率值通过统计样本很容易就能获得。我们假设垃圾短信有y个,其中包含WiW_{i}Wi的有x个,那这个概率值就等于x/y。
P(短信是垃圾短信)表示短信是垃圾短信的概率 = 把样本中垃圾短信的个数除以总样本短信个数,就是短信是垃圾短信的概率。











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有