点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:新智元 | 编辑:LRS
【导读】给一个文本提示就能生成3D模型!
自从文本引导的图像生成模型火了以后,画家群体迅速扩张,不会用画笔的人也能发挥想象力进行艺术创作。
但目前的模型,如DALL-E 2, Imagen等仍然停留在二维创作(即图片),无法生成360度无死角的3D模型。

想要直接训练一个text-to-3D的模型非常困难,因为DALL-E 2等模型的训练需要吞噬数十亿个图像-文本对,但三维合成并不存在如此大规模的标注数据,也没有一个高效的模型架构对3D数据进行降噪。

最近Google研究员另辟蹊径,提出一个新模型DreamFusion,先使用一个预训练2D扩散模型基于文本提示生成一张二维图像,然后引入一个基于概率密度蒸馏的损失函数,通过梯度下降法优化一个随机初始化的神经辐射场NeRF模型。

论文链接:https://arxiv.org/abs/2209.14988
训练后的模型可以在任意角度、任意光照条件、任意三维环境中基于给定的文本提示生成模型,整个过程既不需要3D训练数据,也无需修改图像扩散模型,完全依赖预训练扩散模型作为先验。
从文本到3D模型
以文本为条件的生成性图像模型现在支持高保真、多样化和可控的图像合成,高质量来源于大量对齐的图像-文本数据集和可扩展的生成模型架构,如扩散模型。
虽然二维图像生成的应用场景十分广泛,但诸如游戏、电影等数字媒体仍然需要成千上万的详细的三维资产来填充丰富的互动环境。
目前,3D资产的获取方式主要由Blender和Maya3D等建模软件手工设计,这个过程需要耗费大量的时间和专业知识。
2020年,神经辐射场(NeRF)模型发布,其中体积光线追踪器与从空间坐标到颜色和体积密度的神经映射相结合,使得NeRF已经成为神经逆向渲染的一个重要工具。
最初,NeRF被发现可以很好地用于「经典」的三维重建任务:一个场景下的不同角度图像提供给一个模型作为输入,然后优化NeRF以恢复该特定场景的几何形状,能够从未观察到的角度合成该场景的新视图。
很多三维生成方法都是基于NeRF模型,比如2022年提出的Dream Fields使用预训练的CLIP模型和基于优化的方法来训练NeRF,直接从文本中生成3D模型,但这种方式生成的三维物体往往缺乏真实性和准确性。

DreamFusion采用了与Dream Field类似的方法,但模型中的损失函数基于概率密度蒸馏,最小化基于扩散的前向过程的共享的高斯分布族与预训练的扩散模型所学习的分数函数之间的KL散度。
扩散模型是一个隐变量生成模型,学习如何逐步将一个样本从简单的噪声分布转换到数据分布。
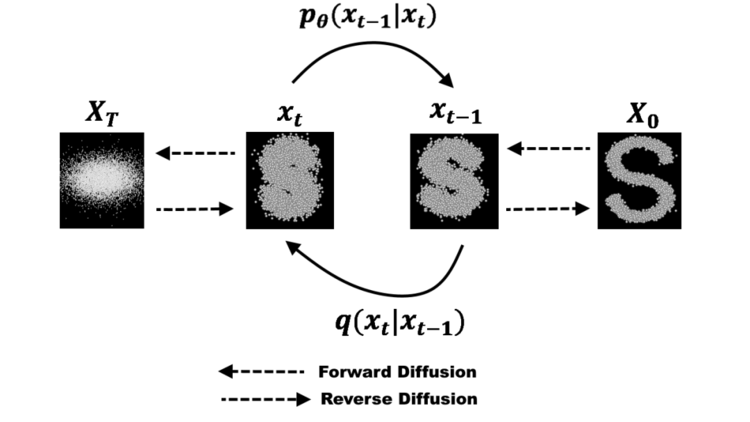
扩散模型的包括一个前向过程(forward process),缓慢地从数据中添加噪声并移除结构,两个时间步之间的过渡通常服从高斯分布,并在反向过程(reverse process)或生成式模型中在噪声上逐渐添加结构。
现有的扩散模型采样方法产生的样本与模型训练的观测数据类型和维度相同,尽管有条件的扩散采样能够实现相当大的灵活性,但在像素上训练的扩散模型传统上只用来对像素进行采样。
但像素采样并不重要,研究人员只希望创建的三维模型在从随机角度渲染时,看起来像是一张好的图像。
可微分图像参数化(DIP)允许模型表达约束条件,在更紧凑的空间中进行优化(例如任意分辨率的基于坐标的MLPs),或利用更强大的优化算法来遍历像素空间。
对于三维来说,参数θ是三维体积的参数,可微生成器g是体积渲染器,为了学习这些参数,需要一个可以应用于扩散模型的损失函数。
文中采用的方法是利用扩散模型的结构,通过优化实现可操作的取样,当损失函数最小化时生成一个样本,然后对参数θ进行优化,使x=g(θ)看起来像冻结扩散模型的样本。
为了进行这种优化,还需要一个可微的损失函数,其中可信的图像具有较低的损失,而不可信的图像有高的损失,与DeepDream的过程类似。
在实践中,研究人员发现即使是在使用一个相同的DIP时,损失函数也无法生成现实的样本。但同期的一项工作表明,这种方法可以通过精心选择的时间步长来实现,但这个目标很脆弱,其时间步长的调整也很困难。
通过观察和分解梯度可以发现,U-Net Jacobian项的计算成本很高(需要通过扩散模型U-Net进行反向传播),而且对于小的噪声水平来说条件很差,因为它的训练目标为近似于边际密度的缩放Hessian
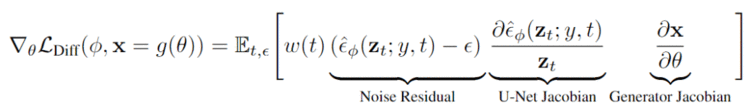
通过实验,研究人员发现省略U-Net的Jacobian项可以带来一个有效的梯度结果,能够用于优化带有扩散模型的DIPs
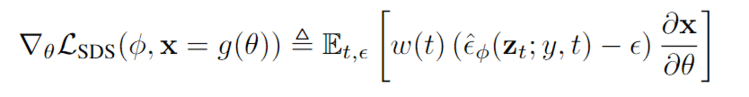
直观来看,这个损失用对应于时间步长的随机数量的噪声来扰动输入数据,并估计出一个更新方向,该方向遵循扩散模型的得分函数,以移动到一个更高密度的区域。

虽然这种用扩散模型学习DIP的梯度可能看起来很特别,但实验结果表明更新方向确实是从扩散模型学到的得分函数中得到的加权概率密度蒸馏损失的梯度。
研究人员将该采样方法命名为得分蒸馏采样(Score Distillation Sampling, SDS),因为该过程与蒸馏有关,但使用的是得分函数而不是密度。
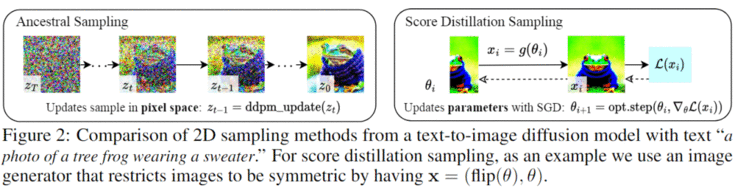
下一步就是通过将SDS与为该3D生成任务定制的NeRF变体相结合,DreamFusion可以为一组不同的用户提供的文本提示生成了高保真的连贯的3D物体和场景。
文章中采用的预训练扩散模型为Imagen,并且只使用分辨率为64×64的基础模型,并按原样使用这个预训练的模型,不做任何修改。
然后用随机权重初始化一个类似于NeRF的模型,从随机的相机位置和角度反复渲染该NeRF的视图,用这些渲染结果作为环绕Imagen的分数蒸馏损失函数的输入。
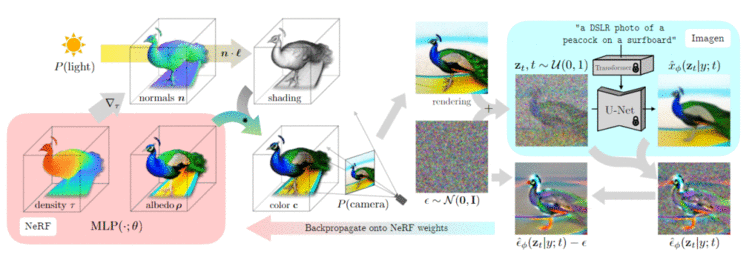
给出一个预训练好的文本到图像的扩散模型,一个以NeRF形式存在的可w微分的图像参数化DIP,以及一个损失函数(最小值代表好样本),这样无三维数据的文本到三维合成所需的所有组件就齐活了。
对于每个文本提示,都从头开始训练一个随机初始化的NeRF。
DreamFusion优化的每次迭代都包含四步:
1、随机采样一个相机和灯光
在每次迭代中,相机位置在球面坐标中被随机采样,仰角范围从-10°到90°,方位角从0°到360°,与原点的距离为1到1.5
同时还在原点周围取样一个看(look-at)的点和一个向上(up)的矢量,并将这些与摄像机的位置结合起来,创建一个摄像机的姿势矩阵。同时对焦距乘数服从U(0.7, 1.35)进行采样,点光位置是从以相机位置为中心的分布中采样的。
使用广泛的相机位置对合成连贯的三维场景至关重要,宽泛的相机距离也有助于提高学习场景的分辨率。
2、从该相机和灯光下渲染NeRF的图像
考虑到相机的姿势和光线的位置,以64×64的分辨率渲染阴影NeRF模型。在照明的彩色渲染、无纹理渲染和没有任何阴影的反照率渲染之间随机选择。
3、计算SDS损失相对于NeRF参数的梯度
通常情况下,文本prompt描述的都是一个物体的典型视图,在对不同的视图进行采样时,这些视图并不是最优描述。根据随机采样的相机的位置,在提供的输入文本中附加与视图有关的文本是有益的。
对于大于60°的高仰角,在文本中添加俯视(overhead view),对于不大于60°的仰角,使用文本embedding的加权组合来添加前视图、侧视图 或 后视图,具体取决于方位角的值。
4、使用优化器更新NeRF参数
3D场景在一台有4个芯片的TPUv4机器上进行了优化,每个芯片渲染一个单独的视图并评估扩散U-Net,每个设备的batch size为1。优化了15,000次迭代,大约需要1.5小时。

实验部分评估了DreamFusion从各种文本提示中生成连贯的3D场景的能力。
与现有的zero-shot文本到3D生成模型进行比较后可以发现,DreamFusion模型中能够实现精确3D几何的关键组件。

通过对比DreamFusion和几个基线的R-精度,包括Dream Fields、CLIP-Mesh和一个评估MS-COCO中原始字幕图像的oracle,可以发现DreamFusion在彩色图像上的表现超过了这两个基线,并接近于ground-truth图像的性能。
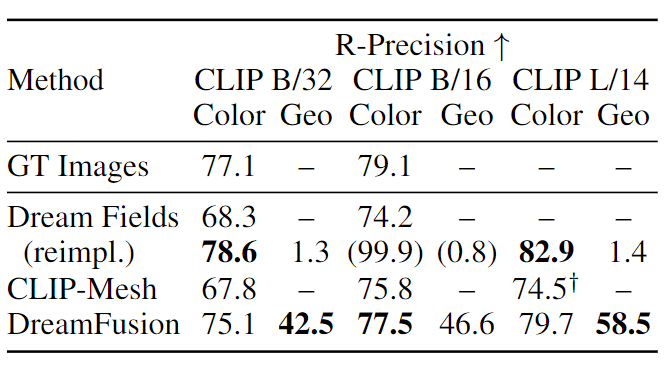
虽然Dream Fields的实现在用无纹理渲染评估几何图形(Geo)时表现得很好,但DreamFusion在58.5%的情况里与标准一致。

参考资料:
https://twitter.com/poolio/status/1575576632068214785?s=46&t=9pUi464Bkyw93WTGhU-cQg
https://dreamfusion3d.github.io/
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看









 京公网安备 11010802041100号
京公网安备 11010802041100号