
以两个变量为例,均值为零可以让变量于自己的轴对称,那么在二维上整个变量分布就是中心对称,而方差则可以控制各个变量离原点的离散程度,那么就可以把二维变量看成限制在某个圈内。
在梯度计算时(偏导)时,梯度方向大致是向着圆心的,那么梯度步长就有一个较大的可调范围,不会出现z字形的梯度路径。


独立同分布IID(independent and identically distributed)
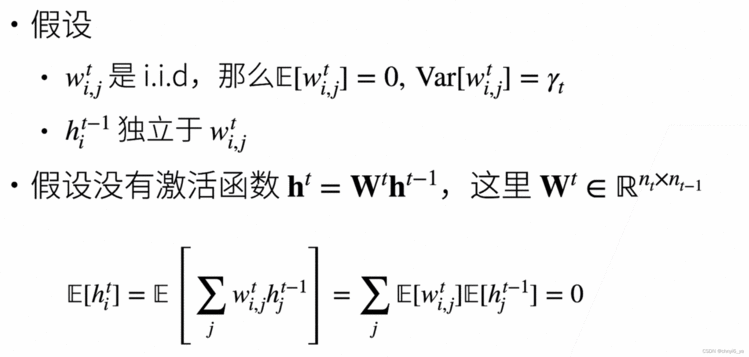
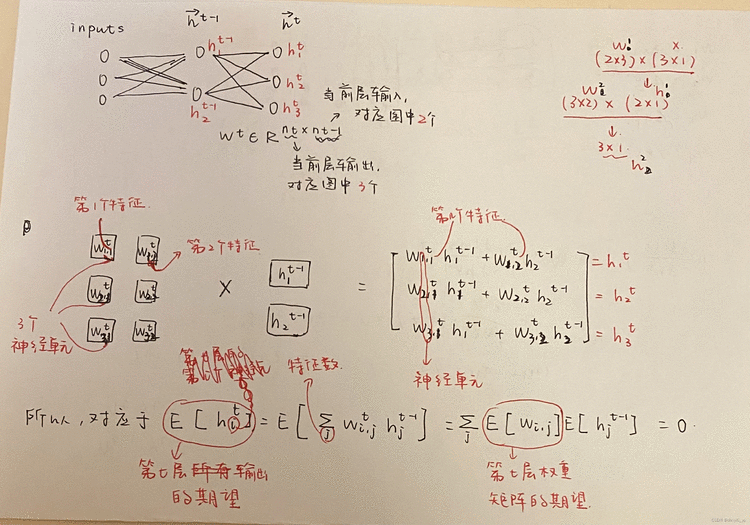
ps: 当X和Y相互独立时,E(XY)=E(X)E(Y),第一项是0,以及之前假设了第二项是0,最后相乘结果为0
方差D(x) = E(X^2 )- E(X) ^ 2
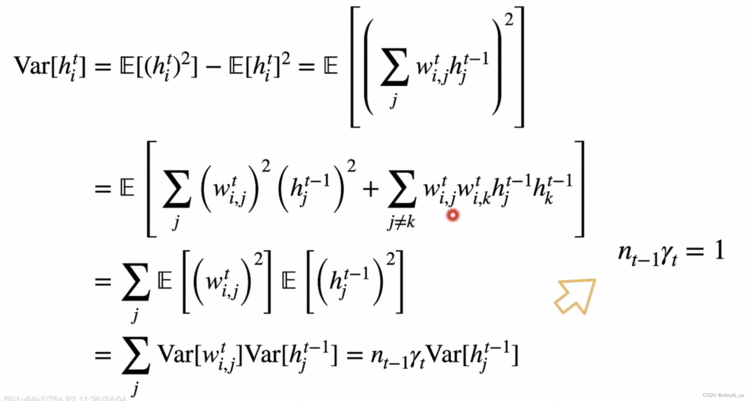

注意:第一行t-1和t弄反了。
最后的结果可知,第t层的输出的个数乘以γ要等于1.

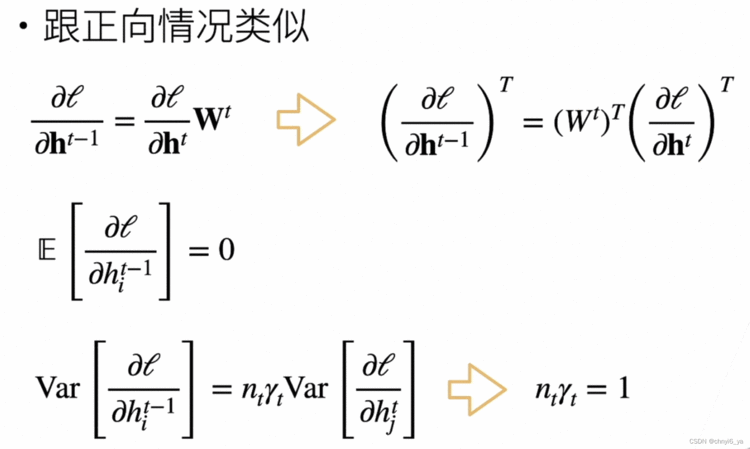
nt-1 * γt = 1保证前项的输出的方差是一致的,nt * γt = 1保证梯度是一样的。
但是nt-1是第t层输入的维度,nt是第t层输出的维度,除非输入的维度和输出的维度一样,不然的话无法同时满足两个条件。
均匀分布 var(x) = 1 / 12(a-b)^2
权重初始化时的方差是根据输入和输出维度来定的。
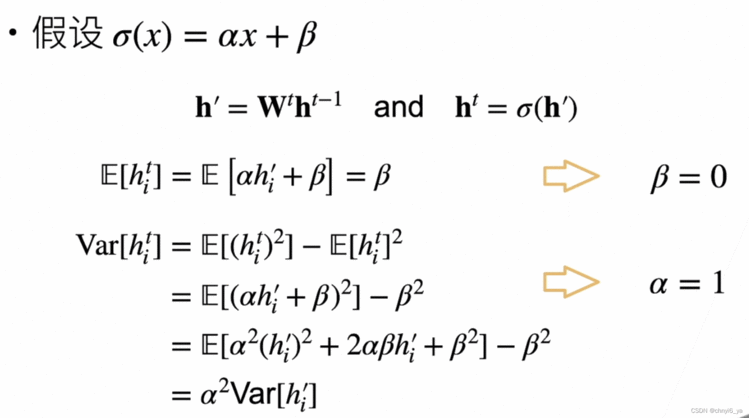
关于期望和方差的公式
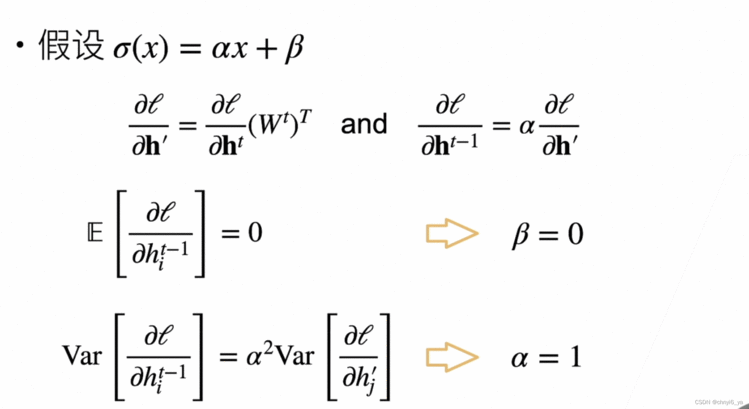
如果希望每一层输出以及梯度的均值为0,方差为固定数的话,只有激活函数f(x)=x满足条件。
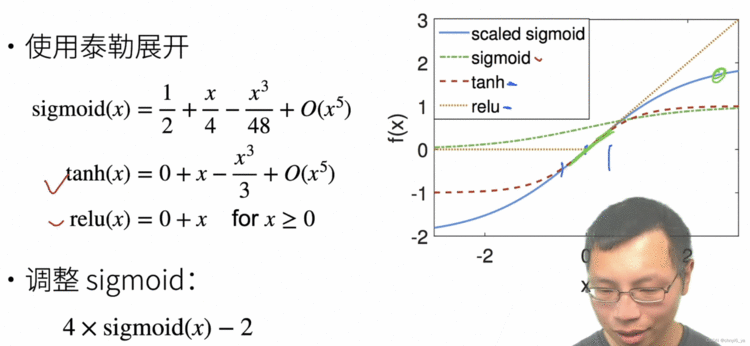
可以看出:tanh,relu以及调整后的sigmoid都可以选取。
解决:1)合理的初始化权重 2)选择正确的激活函数 3)学习率不要选太大。实际碰到了的话,就把学习率一直往小调整,知道nan或inf不出现。也可以看权重的初始,让方差的区间小一点,一直往小走,使得出现值,再慢慢调大使得训练有进展
在训练的过程中,如果网络层的输出的中间层特征元素的值突然变成nan了,是发生了梯度爆炸了吗?
答:是的,nan一般就是梯度太大造成的,梯度太小的话,是训练不动的,没有进展。
sigmoid能引起梯度消失,但是别的情况也会导致梯度消失,用relu代替sigmoid有一定的概率解决梯度消失,但不一定。
通过把每一层输出的均值和方差做限制,可以理解为限制各层输出值出现极大或极小的异常值。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有