全网最详细的Hadoop文章系列,强烈建议收藏加关注!
后面更新文章都会列出历史文章目录,帮助大家回顾知识重点。
目录
本系列历史文章
前言
MapReduce高阶训练
一、上网流量统计
二、需求:统计求和
1、思路分析
2、代码实现
本系列历史文章
2021年大数据Hadoop(三十):Hadoop3.x的介绍
2021年大数据Hadoop(二十九):关于YARN常用参数设置
2021年大数据Hadoop(二十八):YARN的调度器Scheduler
2021年大数据Hadoop(二十七):YARN运行流程
2021年大数据Hadoop(二十六):YARN三大组件介绍
2021年大数据Hadoop(二十五):YARN通俗介绍和基本架构
2021年大数据Hadoop(二十四):MapReduce高阶训练
2021年大数据Hadoop(二十三):MapReduce的运行机制详解
2021年大数据Hadoop(二十二):MapReduce的自定义分组
2021年大数据Hadoop(二十一):MapReuce的Combineer
2021年大数据Hadoop(二十):MapReduce的排序和序列化
2021年大数据Hadoop(十九):MapReduce分区
2021年大数据Hadoop(十八):MapReduce程序运行模式和深入解析
2021年大数据Hadoop(十七):MapReduce编程规范及示例编写
2021年大数据Hadoop(十六):MapReduce计算模型介绍
2021年大数据Hadoop(十五):Hadoop的联邦机制 Federation
2021年大数据Hadoop(十四):HDFS的高可用机制
2021年大数据Hadoop(十三):HDFS意想不到的其他功能
2021年大数据Hadoop(十二):HDFS的API操作
2021年大数据Hadoop(十一):HDFS的元数据辅助管理
2021年大数据Hadoop(十):HDFS的数据读写流程
2021年大数据Hadoop(九):HDFS的高级使用命令
2021年大数据Hadoop(八):HDFS的Shell命令行使用
2021年大数据Hadoop(七):HDFS分布式文件系统简介
2021年大数据Hadoop(六):全网最详细的Hadoop集群搭建
2021年大数据Hadoop(五):Hadoop架构
2021年大数据Hadoop(四):Hadoop发行版公司
2021年大数据Hadoop(三):Hadoop国内外应用
2021年大数据Hadoop(二):Hadoop发展简史和特性优点
2021年大数据Hadoop(一):Hadoop介绍
前言
2021大数据领域优质创作博客,带你从入门到精通,该博客每天更新,逐渐完善大数据各个知识体系的文章,帮助大家更高效学习。
有对大数据感兴趣的可以关注微信公众号:三帮大数据

MapReduce高阶训练
一、上网流量统计
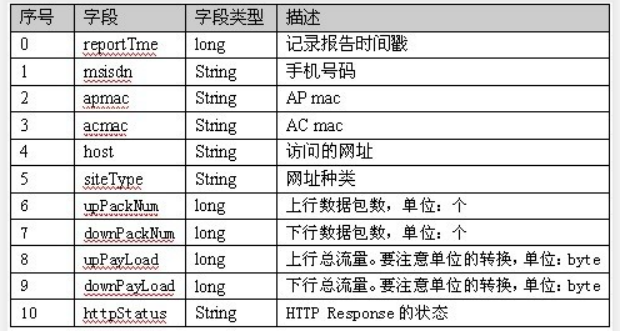
数据格式如下:

二、需求:统计求和
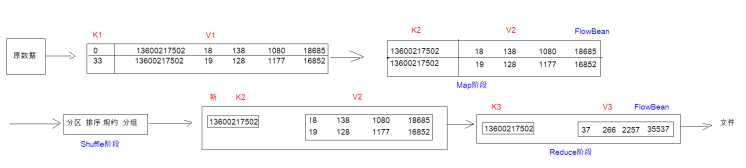
统计每个手机号的上行数据包数总和,下行数据包数总和,上行总流量之和,下行总流量之和
分析:以手机号码作为key值,上行数据包,下行数据包,上行总流量,下行总流量四个字段作为value值,然后以这个key和value作为map阶段的输出,reduce阶段的输入。
1、思路分析
2、代码实现
第一步:自定义map的输出value对象FlowBean
import org.apache.hadoop.io.Writable;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;//如果MR中的JavaBean不是作为K2,则只需要实现Writable接口即可public class FlowBean implements Writable{private Integer upFlow; //上行包数private Integer downFlow; //下行包数private Integer upCountFlow; //上行流量和private Integer downCountFlow; //下行流量和public FlowBean() {}public FlowBean(Integer upFlow, Integer downFlow, Integer upCountFlow, Integer downCountFlow) {this.upFlow = upFlow;this.downFlow = downFlow;this.upCountFlow = upCountFlow;this.downCountFlow = downCountFlow;}public Integer getUpFlow() {return upFlow;}@Overridepublic String toString() {return upFlow +"\t" + downFlow +"\t" + upCountFlow +"\t" + downCountFlow;}public void setUpFlow(Integer upFlow) {this.upFlow = upFlow;}public Integer getDownFlow() {return downFlow;}public void setDownFlow(Integer downFlow) {this.downFlow = downFlow;}public Integer getUpCountFlow() {return upCountFlow;}public void setUpCountFlow(Integer upCountFlow) {this.upCountFlow = upCountFlow;}public Integer getDownCountFlow() {return downCountFlow;}public void setDownCountFlow(Integer downCountFlow) {this.downCountFlow = downCountFlow;}//序列化@Overridepublic void write(DataOutput out) throws IOException {out.writeInt(upFlow);out.writeInt(downFlow);out.writeInt(upCountFlow);out.writeInt(downCountFlow);}//反序列化@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readInt();this.downFlow = in.readInt();this.upCountFlow = in.readInt();this.downCountFlow = in.readInt();}}
第二步:定义FlowMapper类
import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowCountMapper extends Mapper {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1:拆分行文本数据(拆分v1)String[] split = value.toString().split("\t");//2:从拆分数组中得到手机号,得到K2String phoneNum = split[1];//3:从拆分数组中得到4个流量字段,并封装到FlowBean,得到V2FlowBean flowBean = new FlowBean();flowBean.setUpFlow(Integer.parseInt(split[6]));flowBean.setDownFlow(Integer.parseInt(split[7]));flowBean.setUpCountFlow(Integer.parseInt(split[8]));flowBean.setDownCountFlow(Integer.parseInt(split[9]));//4:将K2和V2写入上下文中context.write(new Text(phoneNum), flowBean);}}
第三步:定义FlowCountReducer类
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowCountReducer extends Reducer {@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {//1:定义四个变量,分别来存储上行包数,下行包数,上行流量总和,下行流量总和int upFlow = 0;int downFlow = 0;int upCountFlow = 0;int downCountFlow = 0;//2:遍历集合,将集合中每一个FlowBean的四个流量字段相加for (FlowBean flowBean : values) {upFlow += flowBean.getUpFlow();downFlow += flowBean.getDownFlow();upCountFlow += flowBean.getUpCountFlow();downCountFlow += flowBean.getDownCountFlow();}//3:K3就是原来的K2,V3就是新的FlowBeanFlowBean flowBean = new FlowBean(upFlow, downFlow, upCountFlow, downCountFlow);//4:将K3和V3写入上下文中context.write(key, flowBean);}}
第四步:程序main函数入口FlowCountRunner
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class FlowCountRunner {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1、创建建一个job任务对象Configuration configuration = new Configuration();Job job = Job.getInstance(configuration, "flowcount_demo");//2、指定job所在的jar包job.setJarByClass(FlowCountRunner.class);//3、指定源文件的读取方式类和源文件的读取路径job.setInputFormatClass(TextInputFormat.class); //按照行读取//TextInputFormat.addInputPath(job, new Path("hdfs://node1:8020/input/wordcount")); //只需要指定源文件所在的目录即可TextInputFormat.addInputPath(job, new Path("file:///E:\\input\\flowcount")); //只需要指定源文件所在的目录即可//4、指定自定义的Mapper类和K2、V2类型job.setMapperClass(FlowCountMapper.class); //指定Mapper类job.setMapOutputKeyClass(Text.class); //K2类型job.setMapOutputValueClass(FlowBean.class);//V2类型//5、指定自定义分区类(如果有的话)//6、指定自定义分组类(如果有的话)//7、指定自定义Combiner类(如果有的话)//设置ReduceTask个数//8、指定自定义的Reducer类和K3、V3的数据类型job.setReducerClass(FlowCountReducer.class); //指定Reducer类job.setOutputKeyClass(Text.class); //K3类型job.setOutputValueClass(FlowBean.class); //V3类型//9、指定输出方式类和结果输出路径job.setOutputFormatClass(TextOutputFormat.class);//TextOutputFormat.setOutputPath(job, new Path("hdfs://node1:8020/output/wordcount")); //目标目录不能存在,否则报错TextOutputFormat.setOutputPath(job, new Path("file:///E:\\output\\flowcount")); //目标目录不能存在,否则报错//10、将job提交到yarn集群boolean bl = job.waitForCompletion(true); //true表示可以看到任务的执行进度//11.退出执行进程System.exit(bl?0:1);}}
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨







 京公网安备 11010802041100号
京公网安备 11010802041100号