目录Flink-状态管理Flink中的有状态计算无状态计算和有状态计算无状态计算有状态计算有状态计算的场景状态的分类ManagedState&RawStateKe
目录
Flink-状态管理
Flink中的有状态计算
无状态计算和有状态计算
无状态计算
有状态计算
有状态计算的场景
状态的分类
Managed State & Raw State
Keyed State & Operator State
存储State的数据结构/API介绍
Flink-状态管理
Flink中的有状态计算
注意:
Flink中已经对需要进行有状态计算的API,做了封装,底层已经维护好了状态!
例如,之前下面代码,直接使用即可,不需要像SparkStreaming那样还得自己写updateStateByKey
也就是说我们今天学习的State只需要掌握原理,实际开发中一般都是使用Flink底层维护好的状态或第三方维护好的状态(如Flink整合Kafka的offset维护底层就是使用的State,但是人家已经写好了的)
package cn.it.source;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** Author lanson* Desc* SocketSource*/
public class SourceDemo03 {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2.sourceDataStream linesDS = env.socketTextStream("node1", 9999);//3.处理数据-transformation//3.1每一行数据按照空格切分成一个个的单词组成一个集合DataStream wordsDS = linesDS.flatMap(new FlatMapFunction() {@Overridepublic void flatMap(String value, Collector out) throws Exception {//value就是一行行的数据String[] words = value.split(" ");for (String word : words) {out.collect(word);//将切割处理的一个个的单词收集起来并返回}}});//3.2对集合中的每个单词记为1DataStream> wordAndOnesDS = wordsDS.map(new MapFunction>() {@Overridepublic Tuple2 map(String value) throws Exception {//value就是进来一个个的单词return Tuple2.of(value, 1);}});//3.3对数据按照单词(key)进行分组//KeyedStream, Tuple> groupedDS = wordAndOnesDS.keyBy(0);KeyedStream, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);//3.4对各个组内的数据按照数量(value)进行聚合就是求sumDataStream> result = groupedDS.sum(1);//4.输出结果-sinkresult.print();//5.触发执行-executeenv.execute();}
}
执行 netcat,然后在终端输入 hello world,执行程序会输出什么?
答案很明显,(hello, 1)和 (word,1)
那么问题来了,如果再次在终端输入 hello world,程序会输入什么?
答案其实也很明显,(hello, 2)和(world, 2)。
为什么 Flink 知道之前已经处理过一次 hello world,这就是 state 发挥作用了,这里是被称为 keyed state 存储了之前需要统计的数据,所以 Flink 知道 hello 和 world 分别出现过一次。
无状态计算和有状态计算
无状态计算
不需要考虑历史数据
相同的输入得到相同的输出就是无状态计算, 如map/flatMap/filter....

首先举一个无状态计算的例子:消费延迟计算。
假设现在有一个消息队列,消息队列中有一个生产者持续往消费队列写入消息,多个消费者分别从消息队列中读取消息。
从图上可以看出,生产者已经写入 16 条消息,Offset 停留在 15 ;有 3 个消费者,有的消费快,而有的消费慢。消费快的已经消费了 13 条数据,消费者慢的才消费了 7、8 条数据。
如何实时统计每个消费者落后多少条数据,如图给出了输入输出的示例。可以了解到输入的时间点有一个时间戳,生产者将消息写到了某个时间点的位置,每个消费者同一时间点分别读到了什么位置。刚才也提到了生产者写入了 15 条,消费者分别读取了 10、7、12 条。那么问题来了,怎么将生产者、消费者的进度转换为右侧示意图信息呢?
consumer 0 落后了 5 条,consumer 1 落后了 8 条,consumer 2 落后了 3 条,根据 Flink 的原理,此处需进行 Map 操作。Map 首先把消息读取进来,然后分别相减,即可知道每个 consumer 分别落后了几条。Map 一直往下发,则会得出最终结果。
大家会发现,在这种模式的计算中,无论这条输入进来多少次,输出的结果都是一样的,因为单条输入中已经包含了所需的所有信息。消费落后等于生产者减去消费者。生产者的消费在单条数据中可以得到,消费者的数据也可以在单条数据中得到,所以相同输入可以得到相同输出,这就是一个无状态的计算。
有状态计算
需要考虑历史数据
相同的输入得到不同的输出/不一定得到相同的输出,就是有状态计算,如:sum/reduce

以访问日志统计量的例子进行说明,比如当前拿到一个 Nginx 访问日志,一条日志表示一个请求,记录该请求从哪里来,访问的哪个地址,需要实时统计每个地址总共被访问了多少次,也即每个 API 被调用了多少次。可以看到下面简化的输入和输出,输入第一条是在某个时间点请求 GET 了 /api/a;第二条日志记录了某个时间点 Post /api/b ;第三条是在某个时间点 GET了一个 /api/a,总共有 3 个 Nginx 日志。
从这 3 条 Nginx 日志可以看出,第一条进来输出 /api/a 被访问了一次,第二条进来输出 /api/b 被访问了一次,紧接着又进来一条访问 api/a,所以 api/a 被访问了 2 次。不同的是,两条 /api/a 的 Nginx 日志进来的数据是一样的,但输出的时候结果可能不同,第一次输出 count=1 ,第二次输出 count=2,说明相同输入可能得到不同输出。输出的结果取决于当前请求的 API 地址之前累计被访问过多少次。第一条过来累计是 0 次,count = 1,第二条过来 API 的访问已经有一次了,所以 /api/a 访问累计次数 count=2。单条数据其实仅包含当前这次访问的信息,而不包含所有的信息。要得到这个结果,还需要依赖 API 累计访问的量,即状态。
这个计算模式是将数据输入算子中,用来进行各种复杂的计算并输出数据。这个过程中算子会去访问之前存储在里面的状态。另外一方面,它还会把现在的数据对状态的影响实时更新,如果输入 200 条数据,最后输出就是 200 条结果。
有状态计算的场景

什么场景会用到状态呢?下面列举了常见的 4 种:
1.去重:比如上游的系统数据可能会有重复,落到下游系统时希望把重复的数据都去掉。去重需要先了解哪些数据来过,哪些数据还没有来,也就是把所有的主键都记录下来,当一条数据到来后,能够看到在主键当中是否存在。
2.窗口计算:比如统计每分钟 Nginx 日志 API 被访问了多少次。窗口是一分钟计算一次,在窗口触发前,如 08:00 ~ 08:01 这个窗口,前59秒的数据来了需要先放入内存,即需要把这个窗口之内的数据先保留下来,等到 8:01 时一分钟后,再将整个窗口内触发的数据输出。未触发的窗口数据也是一种状态。
3.机器学习/深度学习:如训练的模型以及当前模型的参数也是一种状态,机器学习可能每次都用有一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
4.访问历史数据:比如与昨天的数据进行对比,需要访问一些历史数据。如果每次从外部去读,对资源的消耗可能比较大,所以也希望把这些历史数据也放入状态中做对比。
状态的分类
Managed State & Raw State

从Flink是否接管角度:可以分为
ManagedState(托管状态)
RawState(原始状态)
两者的区别如下:
- 从状态管理方式的方式来说,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 Raw State 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。
- 从状态数据结构来说,Managed State 支持已知的数据结构,如 Value、List、Map 等。而 Raw State只支持字节数组 ,所有状态都要转换为二进制字节数组才可以。
- 从推荐使用场景来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。
在实际生产中,都只推荐使用ManagedState,后续将围绕该话题进行讨论。
Keyed State & Operator State

Managed State 分为两种,Keyed State 和 Operator State
(Raw State都是Operator State)

在Flink Stream模型中,Datastream 经过 keyBy 的操作可以变为 KeyedStream。
Keyed State是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state,如stream.keyBy(…)
KeyBy之后的State,可以理解为分区过的State,每个并行keyed Operator的每个实例的每个key都有一个Keyed State,即就是一个唯一的状态,由于每个key属于一个keyed Operator的并行实例,因此我们将其简单的理解为

这里的fromElements会调用FromElementsFunction的类,其中就使用了类型为 list state 的 operator state
Operator State又称为 non-keyed state,与Key无关的State,每一个 operator state 都仅与一个 operator 的实例绑定。
Operator State 可以用于所有算子,但一般常用于 Source
存储State的数据结构/API介绍
前面说过有状态计算其实就是需要考虑历史数据
而历史数据需要搞个地方存储起来
Flink为了方便不同分类的State的存储和管理,提供了如下的API/数据结构来存储State!

Keyed State 通过 RuntimeContext 访问,这需要 Operator 是一个RichFunction。
保存Keyed state的数据结构:
ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过value()方法获取状态值,如求按用户id统计用户交易总额
ListState:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable来遍历状态值,如统计按用户id统计用户经常登录的Ip
ReducingState:这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值
MapState:即状态值为一个map。用户通过put或putAll方法添加元素
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄
Operator State 需要自己实现 CheckpointedFunction 或 ListCheckpointed 接口。
保存Operator state的数据结构:
ListState
BroadcastState
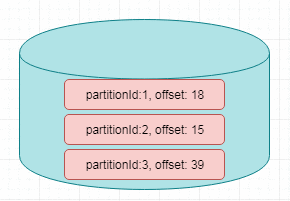
举例来说,Flink中的FlinkKafkaConsumer,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射









 京公网安备 11010802041100号
京公网安备 11010802041100号