**
**
定义:全称Frames Per Second(每秒传输帧数),1秒内游戏画面或者应用界面真实平均刷新次数,俗称帧率。
FPS是图像领域中的定义,指画面每秒传输的帧数,每秒的帧数越多,所显示的动作画面就会越流畅,是测量用来保存、显示动态视频的信息数量。
锁帧: 将帧数锁定在某个比较流畅的帧数,可以保证游戏运行的稳定性,从而减少性能的消耗
掉帧: 指硬件不足以负荷显示器画面动态显示刷新的频率,从而帧率过低造成画面出现停滞现象。掉帧在游戏中就是玩游戏过程中,出现卡这种情况,图像未及时刷新造成,画面粘滞。
电影帧: 电影帧率(18-24),一般是24帧。电影帧单帧耗时:1000ms/24≈41.67ms。电影帧率是一个临界点。低于这个帧率,人眼基本能感觉画面不连续性,也就是感觉到了卡顿。
视觉惯性: 就是视觉上的预期帧率,在用户的潜意识里会认为下一帧也应该是当前的帧率刷新,例如:FPS一直是60帧,用户潜意识就会认为下一帧也应该是60帧;FPS一直是20帧,用户潜意识就会认为下一帧也应该是20帧,但是如果出现60帧一下跳到20帧的情况,就会扰乱用户的视觉惯性,这个时候就会出现卡顿感。
perfdog中所统计的帧率相关数据:
1)Avg(FPS)平均帧率
2)Var(FPS)帧率方差
3)Drop(FPS)降帧次数,平均每小时相邻两个FPS点下降大于8帧的次数
(帧率高,未必流畅。)
定义:1s内卡顿次数。
帧率FPS高并不能反映流畅或不卡顿,帧率FPS低,并不代表卡顿,
例如:FPS为50帧,前200ms渲染一帧,后800ms渲染49帧,虽然帧率50,但依然觉得非常卡顿;
无卡顿时均匀FPS为15帧。
所以帧率和卡顿没有任何直接关系。
PerfDog中Jank的计算方法:
同时满足以下两个条件,则认为是一个卡顿Jank
当前帧耗时 > 前三帧平均耗时2倍
当前帧耗时 > 两帧电影帧耗时(1000ms/24*2=84ms)
同时满足以下两个条件,则认为是一个严重卡顿BigJank
当前帧耗时 > 前三帧平均耗时2倍
当前帧耗时 > 三帧电影帧耗时(1000ms/24*3=84ms)
考虑视觉惯性,以硬件vsync时间间隔,连续1次vsync没有新画面刷新,则认为是一次卡顿,也就是说下一次vsync时间点没有新画面刷新,则认为是一次Jank。如下图:
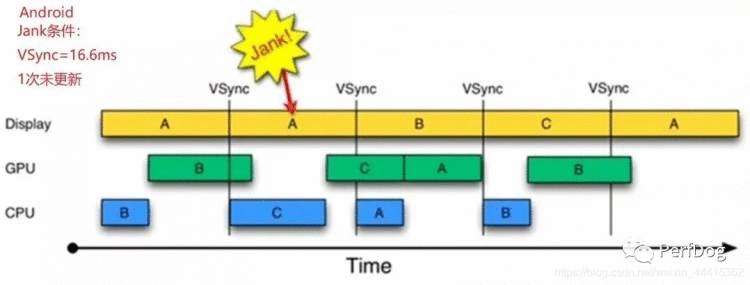
定义:测试过程中卡顿时长的占比,即为 卡顿时长/总时长
注:在游戏中已预知的卡顿,如弹出新UI造成的卡顿,可以认为是干扰,需要剔除
游戏的流畅程度主要取决于Stutter和jank
定义:两帧画面间隔耗时(也可简单认为单帧渲染耗时)。
(iOS9.1以下系统PerfDog暂时不支持)
对于FrameTime与卡顿有什么关联,如下图图示:
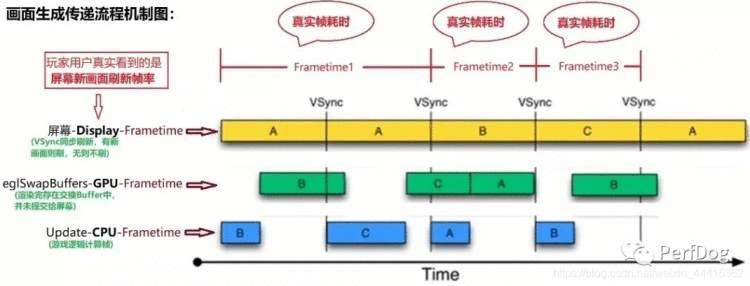
从图中可看出画面中B帧在GPU渲染耗时(帧生成时间)大于显示器刷新间隔,占用两次显示器刷新耗时。也就是说有一次画面没刷新。当出现多次没有画面刷新(也就是说画面没变化),则可能是一次卡顿。
玩家用户真正看到的是屏幕新画面刷新间隔时间,而不是eglSwapbuffers-GPU渲染完成(并未有提交屏幕显示)间隔时间。所以后面所提到Frametime统统指的是屏幕Display-Frametime。
(注:PerfDog统计的FPS和Frametime都是用户看到的屏幕Display新画面真实刷新FPS和帧耗时。所以大家可以直接通过Frametime来判断测试过程中是否出现卡顿。)
注:
流畅度:流畅度和帧率的高低并没有直接关系,流畅度主要是决定于卡顿次数(Jank)和卡顿率(Stutter)
计算方法:当前CPU频率下,CPU Usage = CPU执行时间/CPU总时间
备注:一般Android Studio或adb获取的CPU利用率都是未规范化的CPU利用率
1)TotalCPU:是整机未规范化CPU使用率
2)AppCPU:是进程未规范化CPU使用率
例如:有时候玩游戏会发现手机发烫,就是因为CPU占用率过高,CPU过于繁忙,会使整个手机无法响应,使整体的性能降低,容易引起ANR等一系列问题。
ANR:指在Android设备上,应用程序响应不灵敏时会给用户弹出一个对话框,提示无响应等
CPU问题可能出现的原因:
1)是否有过多的网络请求
2)是否同时有其他应用或进程并行,尝试杀掉其他进程
3)是否有大量图片、视频处理以及加载布局等
4)是否有特殊布局或者特殊操作,例如GPS定位、获取权限、一直刷新;特殊加载,例如GIF图片加载、视频/音频加载等
5)是否有不停的运算消耗CPU,比如不停地while或for循环等
CPU使用率原理:
在Linux系统下,CPU利用率分为用户态、系统态、空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间。
CPU利用率 = CPU执行非系统空闲进程的时间 / CPU总的执行时间
由于移动设备的CPU频率是时刻变化的,用传统CPU利用率的计算方法,假定在低频率时刻计算出的CPU利用率=30%,和在CPU高频率时刻计算出的CPU频率=30%,同样都是30%但性能消耗是完全不一样的,明显高频消耗更高。传统CPU利用率已无法真实的反应性能消耗。
所以我们需要一种规范化(可以量化)的统计方式,将频率因素考虑进去。
CPU Usage(Normalized)=(CPU执行时间/CPU总时间)*(当前时刻所有CPU频率之和/所有CPU频率最大值之和)
注:对于iOS设备,perfdog统计的是传统CPU利用率。由于iOS平台,频率变化一般在电量极低或者是锁屏等极端情况下才出现,所以规范化没有很大意义。
各个CPU核心的未规范化CPU利用率。
即内存占用(是统计FootPrint(访存),注:OOM与FootPrint有关,与系统、机型无关。只与RAM有关,如1G内存机器。FootPrint超过650MB,引发OOM)
OOM:全称“Out Of Memory”,就是内存用完了,官方解释:当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个error。
内存不够了主要有以下两点原因:
1)分配的少:虚拟机本身可使用的内存太少。
2)应用用的太多:应用用的太多,并且用完没有释放,造成了内存泄漏或者内存溢出。
内存泄漏: 申请使用完的内存没有释放,导致虚拟机不能再次使用该内存,此时这段内存就泄露了,因为申请者不用了,而又不能被虚拟机分配给别人用,从而导致系统内存的浪费,导致程序运行速度变慢甚至系统崩溃等严重后果。
内存泄漏也称作“存储渗漏”,用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元。直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。
内存泄漏形象的比喻是“操作系统可提供给所有进程的存储空间正在被某个进程榨干”,最终结果是程序运行时间越长,占用存储空间越来越多,最终用尽全部存储空间,整个系统崩溃。所以“内存泄漏”是从操作系统的角度来看的。这里的存储空间并不是指物理内存,而是指虚拟内存大小,这个虚拟内存大小取决于磁盘交换区设定的大小。由程序申请的一块内存,如果没有任何一个指针指向它,那么这块内存就泄漏。
我们一般常说的内存泄漏是指堆内存的泄漏。
堆内存: 指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显式释放的内存。
内存泄漏分类:
1)常发性:发生内存泄漏的代码会被多次执行到,每次执行的时候都会导致一次内存泄漏。
2)偶发性:发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
3)一次性:发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块且仅一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
4)隐式:程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天、几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏
导致内存泄漏的原因:
因为有root持有引用,所以并没有被销毁,所占用的内存一直没有被释放。一次两次发生影响不大。如果频繁发生,那么可用内存会渐渐不足,最终在某一次请求内存时发现内存不足而发生oom。
内存泄漏和对象的引用计数有很大的关系,再加上c/c++都没有自动的垃圾回收机制,如果没有手动释放内存,问题就会出现。
内存泄漏的危害:
1)CPU资源耗尽
2)进程ID耗尽:无法创建新的进程
3)硬盘耗尽:无法交换内存,无法生成日志等
4)内存耗尽:
内存溢出: 申请的内存超出了JVM能提供的内存大小,此时称之为溢出。
关于OOM的详细解释,具体请查看地址:https://blog.csdn.net/qq_42447950/article/details/81435080
导致内存溢出的原因:
1)内存中加载的数据量过于庞大,如一次从数据库中取出过多的数据
2)集合类中有对对象的引用,使用完后没有清空,是的JVM不能回收
3)代码中存在死循环或者循环产生过多重复的对象实体
4)使用第三方软件中的bug
5)启动参数内存值设定的过小
Xcode Instrument统计方式即Real Memory,即实际占用物理内存
注:物理内存系统策略有关,衡量内存指标时不会关注,但是它有助于分析定位整体性能问题。比如:footprint没有降低,说明应用没有释放内存,但是real memory却降低了,说明系统对内存做了压缩。由于压缩会占用CPU资源,同时相应会导致FPS降低)
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。目前,大多数操作系统都使用了虚拟内存,如Windows家族的“虚拟内存”;Linux的“交换空间”等。
整机可以使用的内存
Swap: 在没有足够的物理内存情况下,系统会通过交换,使用虚拟内存,从而解决内存容量不足的情况。
Swap又被称为交换分区,它的作用是在物理内存使用完之后,将磁盘空间(也就是Swap分区)虚拟成内存来使用。它和Windows系统的交换文件作用类似,但是它是一段连续的磁盘空间,并且对用户不可见,但其访问速度远远慢于实内存的访问速度。
部分设备支持Swap功能,在启用Swap功能后,系统会对PSS内存进行压缩,Swap增加,PSS会相应减少,由于压缩会占用CPU资源,同时相应会导致FPS降低。
PSS:实际使用的物理内存(比例分配共享库占用的内存)
VSS:虚拟耗用内存
USS:进程独自占用的物理内存
RSS:实际使用物理内存(包含共享库占用的物理内存)
包括NativePSS、GFX、GL、JavaHeap、Unknown
注:在极限测试情况下,例如开启游戏超高帧率,建议不要勾选收集Memory Usage和Memory Detail,因为部分机型会有性能损耗。
超过150进程很大可能会被系统kill。
(a sleep/wake cycle on each thread per second,Exceeding limit of 150 wakeups per second over 300 seconds,特别是iOS13.2闷杀后台进程事件,建议重点关注)
图形处理
perfdog目前仅支持部分机型,支持的GPU列表详情:https://perfdog.qq.com/article_detail?id=10101&issue_id=0&plat_id=1
详细解释请看第21点
1)Render: 渲染器利用率(像素着色处理阶段,若占比高,说明是PS阶段出现瓶颈,shader过于复杂或纹理大小、采样复杂等)
2)Tiler: Tiler利用率(顶点着色处理阶段,若占比高,说明是VS阶段出现瓶颈,顶点数太多等原因)
3)Device: 设备利用率(整体GPU利用率)
Mali GPU支持列表:https://perfdog.qq.com/article_detail?id=10055&issue_id=0&plat_id=1
1)Non-fragment: 非片段着色器(顶点着色器,细分着色器,计算着色器)耗费的GPU时间占渲染耗费的GPU时间的比例。
2)Fragment: 片段着色器耗费的GPU时间占渲染耗费的GPU时间的比例。
(仅支持Mali芯片GPU)
1)L2Load/Store:Load/Store单元读取L2内存的实际带宽 (包括顶点缓存,原子,图像数据)。
2)L2Texture:Texture单元读取L2内存的实际带宽 (纹理采样)。
3)Bus Read:定义GPU到DRAM或者GPU外部的系统内存的实际读带宽。
4)Bus Write:定义GPU到DRAM或者GPU外部的系统内存的实际写带宽。
(仅支持Mali芯片GPU)
1)OverDraw:表示每个像素由多少个片段分层组成,通常用于表示像素被重复绘制的次数。
2)PixelsThroughput:表示每个被渲染的像素耗费的GPU的时钟的数量。
1)Mali GPU Utilization
主要包含两个性能指标:
① Non Fragment Utilization:非片段处理耗时占整体GPU处理耗时的百分比
② Fragment Utilization:片段处理耗时占整体GPU处理耗时的百分比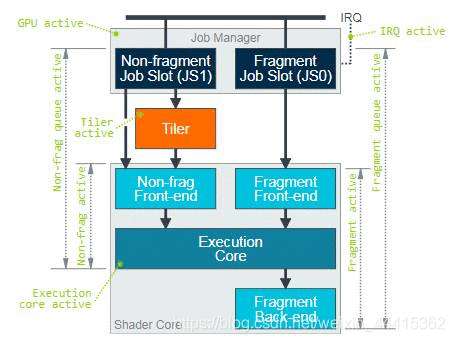
上图显示了通过GPU处理不同类型工作负载的基本处理管道数据路径,以及各个层次结构中每个处理模块的性能指标。在Mali GPU上运行的工作负载由作业管理器统一协调,该任务管理器负责将工作负载调度到GPU内部的各个处理单元上,它将两个FIFO工作队列(称为作业插槽)公开给图形驱动程序。一个插槽用于非片段工作负载,其中包括vertex shading, tiling,geometry shading, tessellation shading, and compute shading,还有一个插槽用于片段着色工作负载,主要包括光栅化、EarlyZ、FPK、Fragment shading、Blender、Tile write等。
注:用于定位GPU瓶颈是在非片段处理阶段还是片段处理阶段,可用于指导程序优化方向。当出现GPU瓶颈时,正常情况下Non Fragment Utilization和Fragment Utilization至少有一个是接近100%,如果两者都低于100%,则有可能是Non Fragment和Fragment之间存在数据依赖关系。
Non Fragment Utilization过高原因及优化建议:
顶点数量过多
a.是否有大量的不可见顶点 —— 优化建议:遮挡剔除、视锥裁剪、背面裁剪
b.可见顶点数量多 —— 使用Lod简化模型,使用距离裁剪
顶点属性数据量大 —— 使用中精度属性,删除无用属性
顶点Shader(着色器)过于复杂 —— 顶点Shader中避免采样纹理,尽量使用低精度变量进行计算
使用了复杂的compute shader或者geometry shader、tessellation shader
Fragment Utilization过高原因及优化建议:
使用Mask材质导致EarlyZ和FKP机制失效 —— 优化建议:提前渲染Mask mesh深度或者降低Mask mesh面数,检查是否可以禁用Mask。
注:EarlyZ:early-z是放在片段着色器之前,提前进行深度测试可以节省不必要像素的片元计算,所以会有性能的提升。
具体的说明可以到此查看:https://www.jianshu.com/p/837c70c98644?utm_campaign=maleskine&utm_cOntent=note&utm_medium=seo_notes&utm_source=recommendation
粒子等半透明像素过多 —— 优化建议:减少粒子数量,控制粒子大小
ALE(应用程序)逻辑计算耗时高 —— 优化建议:避免动态分支,避免使用高耗时函数,把复杂的计算转移到VS阶段
纹理采样耗时高 —— 优化建议:减少纹理采样次数,使用压缩格式纹理,避免使用各项异性过滤方式
Load/Store耗时高 —— 优化建议:使用中精度变量,尽量避免使用高精度计算
2)PixelThrought
指平均每个已着色Pixel(像素)所耗费的GPU Cycle(一个cycle一般指一个时钟周期),所以通常情况下该指标和Vertex Shader(顶点着色器)或Fragment Shader(片段着色器)复杂度有关,可以根据Non Fragment Utilization和Fragment Utilization这两个指标来判定哪部分瓶颈。如果是Fragment处理瓶颈,说明当前场景下Fragment Shader较为复杂,导致处理单个Pixel所耗费Cycle较高。
Vertex Shader:顶点着色器
Fragment Shader:片段着色器
指平均每个已着色Pixel所耗费的GPU Cycle,包括Non Fragment处理Cycle和Fragment处理Cycle。假设GPU最高频率为800Mhz,GPU使用率100%,游戏运行分辨率为1080*2340,FPS为60。
每秒Shaded Pixel (不考虑OverDraw)= 1080 * 2340 * 60 = 151.6M
PixelThrought = 800M / 151.6 = 5.27 Cycle
说明在这种情况下平均渲染每个Pixel 花费5.27个Cycle。
3)Mali OverDraw
Overdraw就是在一帧当中,同一个像素被重复绘制的次数。PerfDog中OverDraw是每秒的平均OverDraw,
OverDraw = 每秒Shaded Fragments / 每秒Screen Pixels
例:假设游戏运行FPS为60, 游戏运行分辨率为10802340,每秒Shaded Fragments 数量为273M。
OverDraw = 2731000000 / (1080234060) = 1.8
(注:从以上公式上可以看出在固定分辨率和帧率下,OverDraw越高则说明每帧处理的Fragments数量越大,负载越高,当负载超过GPU最大处理能力后就会引起掉帧。)
当分析GPU性能时,如果某段时间Fragment Utilization突然升高,原因可能有以下两个方面:
① Fragment数量增大,对应Overdraw性能指标升高,优化方向是降低OverDraw。
② Fragment平均处理耗时增大,对应PixelThrought性能指标升高,优化方向是降低材质Shader复杂度。
Overdraw过高原因及优化建议:
① 在游戏中,Overdraw过高主要是由AlphaTest和AlphaBlend(拥有透明或半透明像素的位图)物件渲染导致,Opaque物件由于GPU中的EarlyZ、FPK机制会自动进行排序并剔除被遮挡片段,所以Opaque(不透明)物件对于OverDraw影响较小。
② AlphaTest物件Overdraw影响:AlphaTest物件的深度写入需要在执行FragmenShader之后才能确定是否写入深度,延迟的深度写入会影响TBDR架构下的HSR效率,因为后续图元需要等到AlphaTest图元执行完FragmenShader并更新深度缓冲区后才能继续处理。
AlphaTest物件Overdraw优化建议:
从前往后排序渲染。
美术制作时减小AlphaTest三角形图元面积。
③ AlphaBlend物件Overdraw影响:AlphaBlend物件可以被Opaque物件EarlyZ剔除,但是因为不会写深度,所以AlphaBlend三角形彼此不能EarlyZ剔除,叠加时产生OverDraw。游戏中的半透明粒子特效、UI等容易产生OverDraw问题。
AlphaBlend物件Overdraw优化建议:
降低半透明混合叠加层数,例如半透明粒子特效根据机型调整粒子数量。
尽量缩减半透明图元屏幕渲染面积,例如渲染粒子特效或UI时使用不规则面片代替矩形面片进行渲染。
4)BusRead/ BusWrite
BusRead/ BusWrite分别表示GPU每秒通过系统总线从外部共享内存中读取和写入的字节数。GPU读写外部DDR(双倍速率同步动态随机存储器)内存非常的耗电,通常来说每GB/s带宽功耗为100mW。另外读写外部内存相对于GPU内部Cache来说,延迟会更大。
BusRead带宽主要来自于GPU的Load/Store Unit(加载/存储单元)、Texture Unit(瓦片单元)和 Tile Unit(渲染单元)三个处理单元,包括顶点输入属性数据、Uniform数据(储存各种着色器需要的数据)、TileList数据(瓦片列表数据)、纹理数据、颜色/深度数据的读取,BusRead大小取决于GPU这几个单元每秒的数据读取量以及L1、L2缓存的命中率。在总数据量不变的情况下,缓存命中率越高,BusRead越小。
BusWrite带宽主要来自于GPU的Load/Store Unit和 Tile Unit两个处理单元,包括顶点输出属性数据、TileList数据、颜色/深度数据的存储。
BusRead带宽过高的原因以及优化建议
1)顶点属性带宽
2)纹理带宽
3)颜色/深度缓冲区带宽
Buswrite带宽过高的原因以及优化建议
1)顶点输出属性带宽
2)Tile List带宽
3)颜色/深度缓冲区带宽
Recv/Send,测试目标进程流量
注:
Android设备:USB/WiFi测试模式下均为APP数据
iOS设备:USB测试模式下是app的,WiFi测试模式下可能是整机可能是app
仅吃吃WiFi模式,包括:整机实时Current电流、Voltage电压、Power功耗
iOS设备:20s获取一次,目前最精准的统计方式,结果和Battery life结果一致,支持所有iOS机型
Android设备:与仪器测试误差<3%左右
Sum(Battery)是耗电量
Android设备:对单个进程是没有特别限制,只要VirtulMomory不超过进程地址空间(一般是4G),系统剩余内存Ram不低于LKM,进程就不会OOM。
iOS设备:比较复杂些,对进程有资源限制,如单个进程FootPrint Limit(1G内存,maxFootPrint=650MB,2G内存,maxFootPrint=1400MB)及系统剩余Ram都有关系。
所以理论上只要游戏或者APP不OOM,内存占用多少都OK。但现实很残酷,内存占用过大会影响整机内存及性能。原则上是越小越好。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
![[二分图]JZOJ 4612 游戏](https://img.php1.cn/3cd4a/1eebe/cd5/2fdc212433a29829.png)