二、数据预处理(第二天)

–real python
文章目录
- 二、数据预处理(第二天)
- 来源
- 1 数据预处理及特征工程
- 1.1 缺失数据统计与处理
- 1.1 任务一:缺失值统计
- 1.2 任务二:对缺失值进行处理
- 1.2 重复值统计及处理
- 1.3 特征工程
- 1.3.1 数据分桶
- 1.3.2 标签编码和独热编码
- 2 数据重构
- 小建议
来源
- 文章内容来源于Datewhale的hands-on-data-analysis项目
- 地址:https://github.com/datawhalechina/hands-on-data-analysis
- 作者:金娟娟,陈安东,杨佳达,老表,李玲,张文涛,高立业
1 数据预处理及特征工程
1.1 缺失数据统计与处理
1.1 任务一:缺失值统计
(1) 请查看每个特征缺失值个数
- 可用
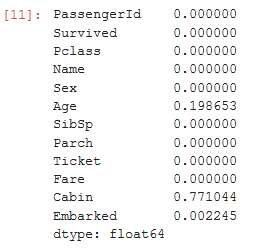
isna 或 isnull (两个函数没有区别)来查看每个单元格是否缺失, mean查看比例, sum查看数量
df.isnull().sum()
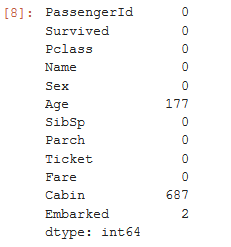
df.isnull().mean()
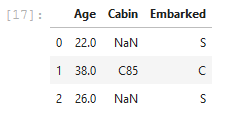
(2) 请查看Age, Cabin, Embarked列的数据
df[['Age','Cabin','Embarked']].head(3)
1.2 任务二:对缺失值进行处理
-
处理方式: 删除dropna和填充fillall
-
deopha主要参数为轴方向 axis (默认为0,即删除行)、删除方式 how 、删除的非缺失值个数阈值 thresh ( 非缺失值 没有达到这个数量的相应维度会被删除)、备选的删除子集 subset ,其中 how 主要有 any 和 all 两种参数可以选择。
-
fillna 中有三个参数是常用的: value, method, limit 。其中, value 为填充值,可以是标量,也可以是索引到元素的字典映射; method 为填充方法,有用前面的元素填充 ffill 和用后面的元素填充 bfill 两种类型, limit 参数表示连续缺失值的最大填充次数。
df1 = df.dropna().head()
df1.reset_index(inplace=True)
df1

df.fillna(0).head()

1.2 重复值统计及处理
1.2.1 重复值统计
duplicated()显示各行是否有重复行,没有重复行显示为FALSE,有重复行显示为TRUE;
df[df.duplicated()]
1.2.2 重复值处理
drop_duplicates方法用于返回一个移除了重复行的DataFrame
df.drop_duplicates().head()
 —
—
1.3 特征工程
1.3.1 数据分桶
- 数据分桶是一种数据预处理技术,用于减少次要观察误差的影响
为什么要进行数据分桶?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化;
- 可以将缺失作为独立的一类带入模型;
- 将所有的变量变换到相似的尺度上。
- 分桶方法分为无监督分桶和有监督分桶。
(1)常用的无监督分桶方法有等频分桶、等距分桶和聚类分桶。
(2) 有监督分桶主要有best-ks分桶和卡方分桶。 pd.cut( x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', )
df['AgeBand'] = pd.cut(df['Age'], 5,labels = ['1','2','3','4','5'])
df.head()

df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = ['1','2','3','4','5'])
df.head(3)

df = pd.read_csv('train.csv')
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = ['1','2','3','4','5'])
df.head()

1.3.2 标签编码和独热编码
- 标签编码将文本变量Sex, Cabin ,Embarked用数值变量12345表示
df = pd.read_csv('test_clear.csv')
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket','Sex']:lbl = LabelEncoder() label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))df[feat + "_labelEncode"] = df[feat].map(label_dict)df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))df.head()

df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
df.head()
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
df.head()
- 独热编码将文本变量Sex, Cabin, Embarked用one-hot编码表示
for feat in ["Age", "Embarked"]:
x = pd.get_dummies(df[feat], prefix=feat)df = pd.concat([df, x], axis=1)df.head()

2 数据重构
2.1 数据合并
-
已知有 text-left-up.csv, text-right-up.csv, text-left-down, text-right-down四张表
-
concat 中,最常用的有三个参数,它们是 axis, join, keys ,分别表示拼接方向,连接形式,以及在新表中指示来自于哪一张旧表的名字.
-
join 函数除了必须的 on 和 how 之外,可以对重复的列指定左右后缀 lsuffix 和 rsuffix 。其中,on 参数指索引名,单层索引时省略参数表示按照当前索引连接。
-
merge主要就是on和how ; left_on 左侧DataFarme中用作连接键的列
right_on 右侧DataFarme中用作连接键的列
2.1.1 横向合并
result_up = pd.concat([text_left_up,text_right_up],axis=1)
result_down = pd.concat([text_left_down,text_right_down],axis=1)
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
2.1.2 纵向合并
result = pd.concat([result_up,result_down])
result = result_up.append(result_down)
2.2 数据分组
text = pd.read_csv('result.csv')
text.head()
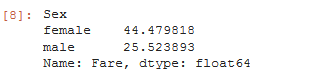
text.groupby('Sex')['Fare'].mean()
text.groupby('Sex')['Survived'].sum()
3.计算客舱不同等级的存活人数
text.groupby('Pclass')['Survived'].sum()
text.groupby(['Sex','Pclass'])['Survived'].agg({'Sex': [('sum_sex','sum')], 'Pclass': [('sum_pclass','sum')]})

小建议
- 第一节 2.3.1 任务一

- 第二节 2.5.1
 3. 第二节2.5.1
3. 第二节2.5.1

- 第三节 2.4.4










 京公网安备 11010802041100号
京公网安备 11010802041100号