目前我们已经完成了商品详情和搜索系统的开发。思考一下,是否存在问题?
如果我们在后台修改了商品的价格,搜索页面和商品详情页显示的依然是旧的价格,这样显然不对。该如何解决?
这里有两种解决方案:
以上两种方式都有同一个严重问题:就是代码耦合,后台服务中需要嵌入搜索和商品页面服务,违背了微服务的独立原则。
所以,我们会通过另外一种方式来解决这个问题:消息队列
消息队列,即MQ,Message Queue,消息队列是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦结合前面所说的问题,如果以后有其它系统也依赖商品服务的数据,同样监听消息即可,商品服务无需任何代码修改。
MQ是消息通信的模型,并不是具体实现。现在实现MQ的有两种主流方式:AMQP、JMS
两者间的区别和联系:
常见MQ产品
消息队列中间件的比较
RabbitMQ:
Redis:
Kafka:
ActiveMQ:基于JMS
RocketMQ:基于JMS,阿里巴巴产品,目前交由Apache基金会
为什么选用了RabbitMQ,首先 基于AMQP协议,稳定性好,不规定实现方式,可以跨语言,可分布式部署,并发量远高于ActiveMQ
下载
因为是erlang编写的所以就像要安装jdk一样安装基础的erlang运行环境
当然还有RabbitMQ安装文件
安装
配置环境变量
erlang和RabbitMQ需要配置
紧接着是安装可视化操作插件
下载插件的指令
C:\WINDOWS\system32>rabbitmq-plugins enable rabbitmq_management
http://localhost:15672/
默认账号密码:
guest
guest
这个时候注意一点一定不要使用默认的账号去操作RabbitMQ,这样会导致无法连接的意外情况。
所以要自己新建一个账户,因为是用来做测试,为了方便权限就直接全部分配就好
RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ,我们平时用不到所以就没有了解
点对点:一个生产者生产的消息,只能由一个消费者处理
普通消息模型,work工作消息模型
发布订阅:一个生产者生产的消息,可以由订阅了消息的所有消费者进行处理
fanout, direct, topic
(dəˈrekt)(ˈtäpik)
RabbitMQ是一个消息代理:它接受和转发消息。 可以把它想象成一个邮局:当你把邮件放在邮箱里时,你可以确定邮差最终会把邮件发送给你的收件人。 在这个比喻中,RabbitMQ是信箱,邮局和邮递员。RabbitMQ与邮局的主要区别是它不处理纸张,而是接受,存储和转发数据消息的二进制数据块。
P( publisher[ˈpəbliSHər]):生产者,一个发送消息的用户应用程序。
C(consumer[kənˈso͞omər]):消费者,消费者是一个用来等待接收消息的用户应用程序
队列:rabbitmq内部类似于邮箱的一个概念。虽然消息流经rabbitmq和你的应用程序,但是它们只能存储在队列中。队列只受主机的内存和磁盘限制,实质上是一个大的消息缓冲区。许多生产者可以发送消息到一个队列,许多消费者可以尝试从一个队列接收数据。
总之:
生产者将消息发送到队列,消费者从队列中获取消息,队列是存储消息的缓冲区。
工作队列或者竞争消费者模式:能者多劳
工作队列,又称任务队列。主要思想就是避免执行资源密集型任务时,必须等待它执行完成。相反我们稍后完成任务,我们将任务封装为消息并将其发送到队列。 在后台运行的工作进程将获取任务并最终执行作业。当你运行许多消费者时,任务将在他们之间共享,但是一个消息只能被一个消费者获取。
这个概念在Web应用程序中特别有用,因为在短的HTTP请求窗口中无法处理复杂的任务。
如何实现能者多劳呢
我们可以使用basicQos方法和prefetchCount = 1设置。 这告诉RabbitMQ一次不要向工作人员发送多于一条消息。 或者换句话说,不要向工作人员发送新消息,直到它处理并确认了前一个消息。 相反,它会将其分派给不是仍然忙碌的下一个工作人员。
如何避免消息堆积?
1)采用workqueue,多个消费者监听同一队列。
2)接收到消息以后,而是通过线程池,异步消费。
在之前的模式中,我们创建了一个工作队列。 工作队列背后的假设是:每个任务只被传递给一个工作人员。 在这一部分,我们将做一些完全不同的事情 - 我们将会传递一个信息给多个消费者。 这种模式被称为“发布/订阅”。
1、1个生产者,多个消费者
2、每一个消费者都有自己的一个队列
3、生产者没有将消息直接发送到队列,而是发送到了交换机
4、每个队列都要绑定到交换机
5、生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者获取的目的
X(Exchanges):交换机一方面:接收生产者发送的消息。另一方面:知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange类型有以下几种:
Fanout:广播,将消息交给所有绑定到交换机的队列Direct:定向,把消息交给符合指定routing key 的队列 Topic:通配符,把消息交给符合routing pattern(路由模式)的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Fanout,也称为广播。在广播模式下,消息发送流程是这样的:
在Direct模型下,队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)消息的发送方在向Exchange发送消息时,也必须指定消息的routing key
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。当然还是会有一些小概率事件会导致消息丢失
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
什么是消息确认ACK。
如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失。为了确保数据不会丢失,RabbitMQ支持消息确定-ACK。
ACK的消息确认机制
ACK机制是消费者从RabbitMQ收到消息并处理完成后,反馈给RabbitMQ,RabbitMQ收到反馈后才将此消息从队列中删除。(注:息永远不会从RabbitMQ中删除,只有当消费者正确发送ACK反馈,RabbitMQ确认收到后,消息才会从RabbitMQ服务器的数据中删除。)如果一个消费者在处理消息出现了网络不稳定、服务器异常等现象,那么就不会有ACK反馈,RabbitMQ会认为这个消息没有正常消费,会将消息重新放入队列中。如果在集群的情况下,RabbitMQ会立即将这个消息推送给这个在线的其他消费者。这种机制保证了在消费者服务端故障的时候,不丢失任何消息和任务。消息的ACK确认机制默认是打开的。
ACK机制的开发注意事项
如果忘记了ACK,那么后果很严重。当Consumer退出时候,Message会一直重新分发。然后RabbitMQ会占用越来越多的内容,由于RabbitMQ会长时间运行,因此这个"内存泄漏"是致命的。
2) 但是,如果在消费者消费之前,MQ就宕机了,消息就没了。
思路分析
发送方:商品微服务
什么时候发?
当商品服务对商品进行写操作:增、删、改的时候,需要发送一条消息,通知其它服务。
发送什么内容?
对商品的增删改时其它服务可能需要新的商品数据,但是如果消息内容中包含全部商品信息,数据量太大,而且并不是每个服务都需要全部的信息。因此我们只发送商品id,其它服务可以根据id查询自己需要的信息。
接收方:搜索微服务、静态页微服务
接收消息后如何处理?
实现
在pom引入依赖
我们在application.yml中添加一些有关RabbitMQ的配置
在GoodsService中封装一个发送消息到mq的方法
单独编写一个 监听器 处理insert和update、delete的消息
分布式系统
我们先假设一下,设想我们正在做一个电商网站。有用户下订单了,除了要在数据库中新建一条记录之外,很显然我们还需要给用户发送一封邮件通知他们订单的详情以及一份报表,以便将来某些时候用户可能会用到。
如果画流程图的话,可能会是这样:
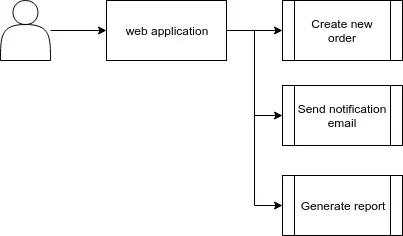
但是,上述这个解决方案的问题在于发送邮件和生成报表都是非常耗时的任务。如果我们在一个请求/响应周期当中,使用同一个进程来处理这2个耗时任务,那么用户将会从服务器端等待比较长的时间。甚至,你的应用服务将会变得很难扩展,因为越多用户向服务器发起请求,就要花越多的时间去处理这些请求。而且,一旦在处理请求上花费很多时间,那么就会给服务器增加负担,更坏的情况下,如果服务器处理的时间很长,那么服务器甚至会向用户返回一个请求超时的错误。
解决办法是让Web应用解耦。Web应用可以首先将消息发送给消息代理(message broker),然后由消息代理将这些消息分发给能执行这些任务的消息消费者,这样一来,Web应用就不用亲自去执行这些任务了。
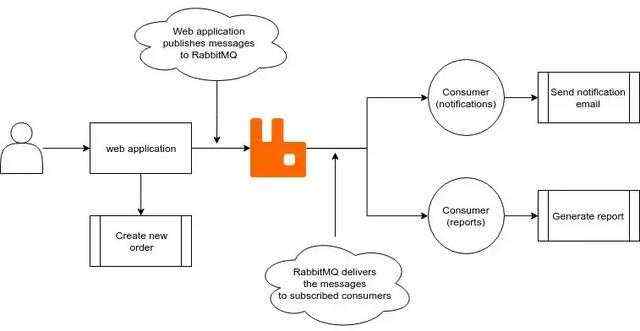
基本上,消费者是相互之间能独立分开工作的程序,并且一般情况下消费者程序来自web应用本身。而那些用来服务消费者的服务器,可以坐落在不同的地方。
除了能减轻服务器的压力之外,分布式系统的另外一个优势是即使其中一个应用挂了,整套系统仍然还是可以工作的。假如其中一个消费者无法给用户发送通知邮件了,那么我们可以把它停掉。即使我们的消费者挂了,我们的web应用仍然可以继续处理用户的请求并且给代理发送消息。一旦消费者恢复了,它马上就能接收到之前web应用发来的消息。
现在我们来看一下RabbitMQ ,它是一个在生产者(Web应用)和消费者之间的中间人。
RabbitMQ 要点知识
RabbitMQ 是一个消息代理。它实现了不同的协议,但是最重要的是,它实现了AMQP(高级消息队列协议),AMQP是一个用来在多个系统之间通过生产者,代理以及消费者交换消息的协议。
AMQP是如何工作的
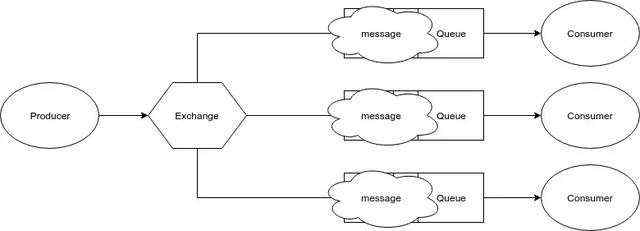
现在,我们有一个生产者和一个消费者。生产者产生消息,消费者消费消息。在它们二者之间我们还有一个代理,代理从生产者那里接收消息然后发送给消费者。
如果我们仔细研究下代理的工作原理,可能会有些难理解。代理由如下3个组件组成:
当创建Exchange时,我们会指定一个exchange类型。当创建一个binding用来连接一个exchange和一个队列时,我们会指定一个Binding key。 当发布一条消息时,我们会指定一个exchange和一个routing Key。 哪条消息会被发送给哪个queue,取决于下面这4个标准:
一共有4种类型的exchange:
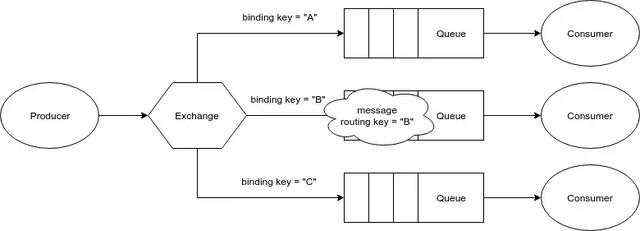
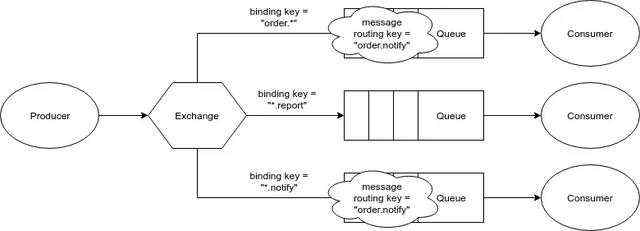
最后,说点题外话,默认情况下RabbitMQ其实是有一个匿名的exchange。这个exchange会用队列的名字跟routing key做匹配,而不是binding key。所以,如果你发布一个routing key = “order”的消息到这个exchange,exchange将会路由这个消息到名为“order”的队列。
RabbitMQ可以通过三种方法部署分布式集群策略:Cluster集群、联盟(federation)和shovel。
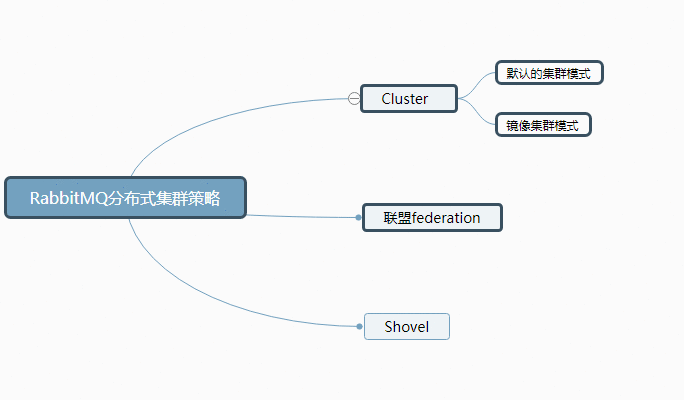
至少包含一个磁盘服务器节点节点,N个内存节点
集群中有两种节点:
1 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
2 磁盘节点:保存状态到内存和磁盘。
内存节点队列服务器数据保存在内存,宕机会丢失未读取的的数据。内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。
磁盘节点队列服务器数据保存在硬盘,宕机不会丢失未读取的消息
联盟模式允许单台服务器上的交换机或队列接收到另一台服务器上交换机或队列的消息,可以是单独机器或集群。
shovel连接方式与联盟(federation)的连接方式类似,但它工作在更低层次。shovel接受队列上的消息,转发到另一台服务器上的交换机。
shovel和联盟类似,但它比联盟提供更多控制。
一个集群中多个节点共享一份.erlang.COOKIE文件;若是没有启用RABBITMQ_USE_LONGNAME,需要在每个节点的hosts文件中指定其他节点的地址,不然会找不到其他集群中的节点。
RabbitMQ集群对于网络分区的处理和忍受能力不太好,推荐使用federation或者shovel插件去解决。federation详见高级->Federation。但是,情况已经发生了,怎么去解决呢?放心,还是有办法恢复的。当网络断断续续时,会使得节点之间的通信断掉,进而造成集群被分隔开的情况。这样,每个小集群之后便只处理各自本地的连接和消息,从而导致数据不同步。当重新恢复网络连接时,它们彼此都认为是对方挂了,便可以判断出有网络分区出现了。但是RabbitMQ默认是忽略掉不处理的,造成两个节点继续各自为政(路由,绑定关系,队列等可以独立地创建删除,甚至主备队列也会每一方拥有自己的master)。可以更改配置使得连接恢复时,会根据配置自动恢复。
配置:**【详见下文:集群配置】






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有