作者:书友49457861 | 来源:互联网 | 2023-08-12 17:15
【README】
1.本文包含了 批处理与流处理的代码示例;
- 批处理:把数据 攒在一起(或攒一段时间或攒一定内存大小),然后再处理,这叫批处理;
- 流处理:数据每来一个就处理一个;
2.特点:
| 数据处理方式 | 特点 |
| 批处理 | 1.高延时; |
| 流处理 | 1.低延时; |
3.引入flink的maven依赖:
org.apache.flinkflink-java1.14.4org.apache.flinkflink-streaming-java_2.121.14.4org.apache.flinkflink-clients_2.121.14.4
【1】flink批处理离线数据(数据有限)
【1.1】代码
1)数据源,我们保存在本地文本文件中,命名为 hello.txt
hello world
hello flink
how are you
thank you
hello zhangsan
hello lisi
2)批处理代码:
/*** @Description 批处理,word count程序(离线数据)* @author xiao tang* @version 1.0.0* @createTime 2022年04月09日*/
public class WordCount {public static void main(String[] args) throws Exception {// 创建执行环境ExecutionEnvironment env &#61; ExecutionEnvironment.getExecutionEnvironment();// 从文件中读取数据String inputPath &#61; "D:\\workbench_idea\\diydata\\flinkdemo2\\src\\main\\resources\\hello.txt";DataSource dataSource &#61; env.readTextFile(inputPath);// 对数据集处理&#xff0c;按照空格分词展开&#xff0c;转为 (word,1) 二元组统计DataSet> resultSet &#61; dataSource.flatMap(new MyFlatMapper()).groupBy(0) // 按照第1个位置的word分组.sum(1); // 将第2个位置上的数据求和resultSet.print();}public static class MyFlatMapper implements FlatMapFunction> {&#64;Overridepublic void flatMap(String value, Collector> collector) throws Exception {// 按照空格分词String[] words &#61; value.split(" ");// 遍历所有word&#xff0c;包装成word 输出Arrays.stream(words).forEach(x->{collector.collect(new Tuple2<>(x, 1));});}}
}
批处理打印结果&#xff1a;
(you,2)
(flink,1)
(world,1)
(hello,4)
(lisi,1)
(zhangsan,1)
(are,1)
(thank,1)
(how,1)
批处理的结果是最终结果&#xff1b;
【2】flink流处理离线数据&#xff08;数据有限&#xff09;
/*** &#64;Description 流数据&#xff08;无限数据&#xff09;* &#64;author xiao tang* &#64;version 1.0.0* &#64;createTime 2022年04月09日*/
public class StreamWordCount {public static void main(String[] args) throws Exception {// 流处理执行环境StreamExecutionEnvironment streamEnv &#61; StreamExecutionEnvironment.getExecutionEnvironment();streamEnv.setParallelism(2); // 设置并行度// 从文件中读取数据String inputPath &#61; "D:\\workbench_idea\\diydata\\flinkdemo2\\src\\main\\resources\\hello.txt";DataStream dataStream &#61; streamEnv.readTextFile(inputPath);// 定义流操作DataStream> resultStream &#61; dataStream.flatMap(new WordCount.MyFlatMapper()).keyBy(0).sum(1);// 打印结果resultStream.print();// 执行任务&#xff08;流终止操作&#xff09;streamEnv.execute();}
}
打印结果&#xff1a;
2> (world,1)
1> (thank,1)
2> (flink,1)
1> (hello,1)
2> (how,1)
2> (you,1)
1> (hello,2)
2> (you,2)
1> (hello,3)
2> (zhangsan,1)
1> (hello,4)
2> (lisi,1)
1> (are,1)
流处理的结果是一个动态变化的有状态的结果&#xff1b;
有状态的意思说白了就是&#xff1a;后面的处理结果依赖前面的处理结果&#xff0c;如对hello计数为3&#xff0c;它是在前面hello计数为2的基础上做的处理&#xff1b;
【3】flink流处理在线数据&#xff08;数据无限&#xff09;
我们引入了 netcat&#xff08;nc&#xff09;&#xff0c;底层使用socket模拟向某端口写入数据&#xff1b;
然后 flink监控该端口的数据&#xff0c;并做处理&#xff1b;
【3.1】 flink处理类
处理类监听了 nc所在机器的的端口&#xff0c;即 192.168.163.201:7777&#xff1b;
/*** &#64;Description socket文本流词计数* &#64;author xiao tang* &#64;version 1.0.0* &#64;createTime 2022年04月09日*/
public class SocketTextStreamWordCount {public static void main(String[] args) throws Exception {// 流处理执行环境StreamExecutionEnvironment streamEnv &#61; StreamExecutionEnvironment.getExecutionEnvironment();streamEnv.setParallelism(2); // 设置并行度// 从 flinkjava parametertool 获取参数&#xff08;或有&#xff09;
// ParameterTool parameterTool &#61; ParameterTool.fromArgs(args);
// String host &#61; parameterTool.get("host");
// int port &#61; parameterTool.getInt("port");// 从socket文本流读取数据DataStream inputDataStream &#61; streamEnv.socketTextStream("192.168.163.201", 7777);// 定义流操作DataStream> resultStream &#61; inputDataStream.flatMap(new WordCount.MyFlatMapper()).keyBy(0).sum(1);// 打印结果resultStream.print();// 执行任务&#xff08;流终止操作&#xff09;streamEnv.execute();}
}
演示效果&#xff1a;
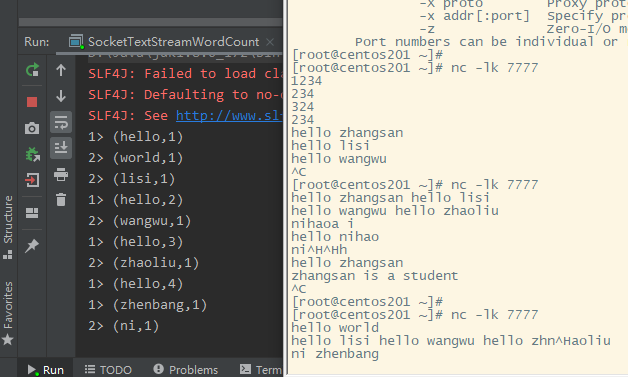






![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号