目录
awk不是一个命令,而是一门语言。
awk 又叫做GNU awk,gawk
ll $(which awk)
lrwxrwxrwx. 1 root root 4 Jul 5 19:00 /usr/bin/awk -> gawk
awk 'BEGIN{}{}END{}' filename
练习
awk -F: 'BEGIN{print "name","uid"}{print $1,$3}END{print "文件读取结束"}' /etc/passwd|column -t
| awk option | awk action | awk内置变量 |
|---|---|---|
| -F:指定分隔符 | print:打印 | NR:Number of Record(行) |
| -v:给awk传递变量 | ~:成员运算(模糊匹配,包含) | RS:Record Separator 记录分隔符(默认是 \n) |
| gsub:替换 gsub(/被替换的内容/,"替换后的内容", 列) | FS:Field Separator 字段分隔符,可以用-F | |
| ~:匹配正则 | NF:Number of Field 这个文件总共有多少字 段 | |
| !~:不匹配正则 | OFS:Output Field Separator 输出字段分隔符 |
行:record 记录
## 取行(记录)
awk 'NR==1' /etc/passwd
## 取第5行到第10行
## $0 表示当前整行数据
awk 'NR>=5 && NR<=10{print NR,$0}' /etc/passwd
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
## 取第一行和第三行
awk 'NR==1 || NR==3{print NR,$0}' /etc/passwd
## 精确匹配指定字段的行
awk '/root/' /etc/passwd
awk '/root/,/zls/' /etc/passwd
## 模糊匹配:/etc/passwd中,第一列包含n字符串的内容
awk -F: '$1~/n/' /etc/passwd
## awk控制结束标记(换行符)
awk -vRS=: '{print NR,$0}' /etc/passwd
列:field 字段
## 取列(取字段)
awk -F: '{print $1,$3}' /etc/passwd
# 注意:在awk中,$数字,$内容 都是指取某一列,别和shell中的位置变量搞混了
## 1,3,最后一列
awk -F: '{print $1,$3,$NF}' /etc/passwd
## 将每一列的分隔符改为#
awk -F: '{print $1"#"$3"#"$NF}' /etc/passwd
# 如果文件有10万行
awk -vOFS=# -F: '{print $1,$3,$NF}' /etc/passwd
行和列一起取
# 取top中的运行时间
top -n1|awk -F '[ ,]+' 'NR==1{print $5,$6,$7}'
# 取出网卡配置文件中的IP地址
awk -F= '/IPADDR/{print $2}' /etc/sysconfig/network-scripts/ifcfg-eth0
10.0.0.61
## 文件内容
Zeng Laoshi 133411023 :110:100:75
Deng Ziqi 44002231 :250:10:88
Zhang Xinyu 877623568 :120:300:200
Gu Linazha 11029987 :120:30:79
Di Lireba 253097001 :220:100:200
Jiang Shuying 535432779 :309:10:2
Ju Jingyi 68005178 :130:280:385
Zhang Yuqi 376788757 :500:290:33
Wen Zhang 259872003 :100:200:300
## 请找出姓氏是张的人,他们第二次捐款的数额及姓名
awk -F '[ :]+' '$1~/Zhang/{print $1,$2,$5}' test.txt
Zhang Xinyu 300
Zhang Yuqi 290
awk -F '[ :]+' '$1~/Zhang/{print $2,$3,$(NF-1)}' test.txt
Zhang Xinyu 300
Zhang Yuqi 290
## 显示所有以25开头的QQ号及姓名
awk '$3~/^25/{print $1,$2,$3}' test.txt
Di Lireba 253097001
Wen Zhang 259872003
## 显示所有QQ号最后一位是1或者3的人,全名及QQ
awk '$3~/1$|3$/{print $1,$2,$3}' test.txt
Zeng Laoshi 133411023
Deng Ziqi 44002231
Di Lireba 253097001
Wen Zhang 259872003
awk '$3~/[13]$/{print $1,$2,$3}' test.txt
Zeng Laoshi 133411023
Deng Ziqi 44002231
Di Lireba 253097001
Wen Zhang 259872003
awk '$3~/(1|3)$/{print $1,$2,$3}' test.txt
Zeng Laoshi 133411023
Deng Ziqi 44002231
Di Lireba 253097001
Wen Zhang 259872003
## 显示每个捐款值都以$开头 $110:$00$75
awk '{gsub(/:/,"$",$4);print $0}' test.txt
awk 'gsub(/:/,"$",$4){print $0}' test.txt
Zeng Laoshi 133411023 $110$100$75
Deng Ziqi 44002231 $250$10$88
Zhang Xinyu 877623568 $120$300$200
Gu Linazha 11029987 $120$30$79
Di Lireba 253097001 $220$100$200
Jiang Shuying 535432779 $309$10$2
Ju Jingyi 68005178 $130$280$385
Zhang Yuqi 376788757 $500$290$33
Wen Zhang 259872003 $100$200$300
## 综合应用:找出ifconfig中范围是1-255的数字
[root@m01 /tmp]# ifconfig|awk -vRS='[^0-9]+' '{print NR,$0}'
[root@m01 /tmp]# ifconfig|awk -vRS='[^0-9]+' '$0>=1 && $0<=255'
[root@m01 /tmp]# ifconfig|grep -Eo '[0-9]+'|awk '$0>=1 && $0 <=255{print $0}'
在awk中,我们最常用的动作就是 print ,当然我们还有别的动作可以使用:
# 统计/etc/service文件中一共有多少行
awk '{line++}END{print line}' /etc/services
sed -n '$=' /etc/services
11176
wc -l /etc/services
11176 /etc/services
状态码:10
流量:11
awk '$10==200{line++;liuliang+=$11}END{print "200次数:"line,"200的流量:"liuliang}'
blog.driverzeng.com_access.log
200次数:166 200的流量:5068201
# gsub替换
awk 'gsub(/:/,"$"){print $0}' test.txt
awk 'gsub(/:/,"$",$4){print $0}' test.txt
正则表达式
# 正则表达式写法
'/正则表达式/flag'
'$1~/正则表达式/flag'
'$1!~/正则表达式/flag'
只不过我们在awk中很少使用flag
比较表达式
NR==1
NR>=10
NR<=100
NR>=1 && NR<=10
$1>=100
范围模式
## 精确匹配行号:从第10行到第20行
NR==10,NR==20
## 精确匹配字符串:从该字符串的行到另一个字符串所在行
'/root/,/zls/'
'/从哪个字符串所在行/,/到那个字符串所在行/' #中间的行都包含进去
[root@m01 /tmp]# awk -F'[,]' '/zl/,/cl/' laoshi.txt
1,zls,666
2,wls,777
3,cls,888
## 模糊匹配字符串:从含有该字符串所在行到含有另一字符串所在行
'$1~/oo/,$1~/zl/'
[root@m01 /tmp]# awk -F'[,]' '$2~/zl/,$2~/cl/' laoshi.txt
1,zls,666
2,wls,777
3,cls,888
特殊模式:BEGIN
如果要使用BEGIN模式,那么一定要成双成对的出现: BEGIN{}
那么我们要知道,BEGIN{}中,大括号里面的内容,会在读取文件内容之前执行
主要应用场景:
awk 'BEGIN{print 1/3}'
0.33333
特殊模式:END
一般来说,END{}要比BEGIN{}重要一些,BEGIN{}可有可无,计算其实可以放在读取文件的时候,也可以执行 END{}中,大括号里面的内容,会在awk读取完文件的最后一行后,进行处理
作用:一般我们使用END{}来显示对日志内容分析后的一个结果 当然,还有其他功能,比如文件读取完了,可以显示 一些尾部信息
# 统计/etc/services文件的行数
awk '{line++}END{print line}' /etc/services
11176
# 统计/etc/services文件的空行数
awk '/^$/{line++}END{print line}' /etc/services
17
grep -c '^$' /etc/services
17
# 统计出下列文件中所有人的年龄和
[root@m01 /tmp]# cat student.txt
姓名 年龄
曾老湿 23
苍颈空 18
西冶详 99
[root@m01 /tmp]# awk 'NR>1{sum+=$2}END{print sum}' student.txt
140
# 统计nginx日志中,状态码是200的次数以及,状态码是200时占用的流量
条件:
- 获取状态码 $10
- 获取大小 /流量 $11
[root@m01 /tmp]# awk '$10==200{liang+=$11}END{print liang/1024/1024}' blog.driverzeng.com_access.log
1.94777
[root@m01 /tmp]# awk '$10==200{num++;liang+=$11}END{print "200的次数:"num,"总流量:"liang/1024/1024"MB"}' blog.driverzeng.com_access.log
200的次数:87 总流量:1.94777MB
# 统计2xx 3xx 4xx 5xx的总流量和次数
awk '
$10~/^2/{line2++;liuliang2+=$11}
$10~/^3/{line3++;liuliang3+=$11}
$10~/^4/{line4++;liuliang4+=$11}
$10~/^5/{line5++;liuliang5+=$11}
END{
print line2,liuliang2
print line3,liuliang3
print line4,liuliang4
print line5,liuliang5
}' blog.driverzeng.com_access.log
# 统计URI
[root@m01 /tmp]# awk '{print $7}' blog.driverzeng.com_access.log|sort|uniq -c|sort -nr|head
16 /wp-login.php
15 /
9 /wp-content/uploads/2019/08/84CF01626246E27625FB03A84651435B.mp4?_=1
8 /zenglaoshi/1759.html
7 /zenglaoshi/category/linux/linux%e5%9f%ba%e7%a1%80%e7%af%87
5 /favicon.ico
3 /zenglaoshi/hyrzzz/01.cur
在awk中的数组数据类型,是非常好用的一个类型,不像是shell,当然shell中数组也有它自己的优点。
awk中的数组,专门用来统计不同的分类。
例如: 1.nginx日志中每个IP出现的次数 2.nginx日志中每种状态码出现的次数 3.nginx日志中每个URI的访问次数
[root@m01 /tmp]# awk '{print $1}' blog.driverzeng.com_access.log|sort|uniq -c|sort -nr|head
10 180.97.165.74
10 180.97.165.26
8 180.97.165.62
7 58.215.115.35
6 180.97.165.27
5 180.97.165.41
4 180.97.165.66
4 180.97.165.63
4 180.97.165.48
4 180.97.165.33
awk 'BEGIN{array[0]="zls";array[1]="cls"}'
## 取值,只支持数字下标
[root@m01 /tmp]# awk 'BEGIN{array[0]="zls";array[1]=cls;print array[0]}'
zls
[root@m01 /tmp]# awk 'BEGIN{array[0]="zls";array[1]="cls";print array[1]}'
cls
## shell
array=("a" "b" "c")
for n in ${array[*]};do
echo $n
done
## awk
for(n in array){
print n
}
## 注意,在awk中循环数组,出来的结果是数组的下标(索引)
[root@m01 /tmp]# awk 'BEGIN{array[0]="zls";array[1]="cls";for(name in array){print name}}'
0
1
[root@m01 /tmp]# awk 'BEGIN{array[0]="zls";array[1]="cls";for(name in array){print array[name]}}'
zls
cls
# 取出下列域名并根据域名,进行统计排序处理
[root@m01 /tmp]# vim web.log
https://blog.driverzeng.com/index.html
https://blog.driverzeng.com/1.html
http://post.driverzeng.com/index.html
http://mp3.driverzeng.com/index.html
https://blog.driverzeng.com/3.html
http://post.driverzeng.com/2.html
[root@m01 /tmp]# awk -F'/' '{print $3}' web.log|sort|uniq -c|sort -nr
3 blog.driverzeng.com
2 post.driverzeng.com
1 mp3.driverzeng.com
[root@m01 /tmp]# awk -F/ '{array[$3]++}END{for(ip in array){print ip,array[ip]}}' web.log
blog.driverzeng.com 3
post.driverzeng.com 2
mp3.driverzeng.com 1
# 统计日志中,每个IP出现的次数,及流量总和
统计ip的次数:count[$1]++
流量总和:sum[$1]+=$11
[root@m01 /tmp]# awk '{count[$1]++;sum[$1]+=$11}END{for(ip in count){print ip,count[ip],sum[ip]}}' blog.driverzeng.com_access.log
# awk
if(条件){
}
if(条件){
}else{
}
if(条件){
}else if(条件){
}else{
}
[root@m01 /tmp]# awk -F: '{if($1~/root/){print $0}}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@m01 /tmp]# awk -F: '{if($1~/root/){print}}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@m01 /tmp]# awk -F: '$1~/root/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
练习
# 判断磁盘使用率大于70%,大于显示磁盘空间不足,不大于显示正常
[root@m01 /tmp]# df -h|awk -F '[ %]+' 'NR>1{sum+=$5}END{if(sum>50){print "磁盘空间不足,当前使用率:"sum"%"}else{print "磁盘空间够用"}}'
磁盘空间不足,当前使用率:59%
# 1.数组循环
awk '{array[$1]++}END{for(n in array){print n,array[n]}}' filename
for(num in array){
print num,array[num]
}
## 2.按次数循环
for(i=1;i<=10;i++){
print i
}
[root@m01 /tmp]# seq 100|awk '{sum+=$1}END{print sum}'
5050
[root@m01 /tmp]# seq 100|awk 'BEGIN{for(i=1;i<=100;i++){sum+=i}print sum}'
5050
# 2.企业面试题:统计每个学生的总成绩和平均成绩
[root@m01 /tmp]# cat grade.txt
stu01 70 80 90 100 90 80
stu02 89 78 98 67 97 90
stu03 56 12 33 44 55 66
stu04 89 78 77 99 100 30
stu05 98 97 96 95 94 93
stu06 100 20 20 20 20 20
[root@m01 /tmp]# awk '{sum=0;for(i=2;i<=NF;i++){sum+=$i}print "总成绩:"sum,"平均成绩:"sum/(NF-1)}' grade.txt
总成绩:510 平均成绩:85
总成绩:519 平均成绩:86.5
总成绩:266 平均成绩:44.3333
总成绩:473 平均成绩:78.8333
总成绩:573 平均成绩:95.5
总成绩:200 平均成绩:33.3333
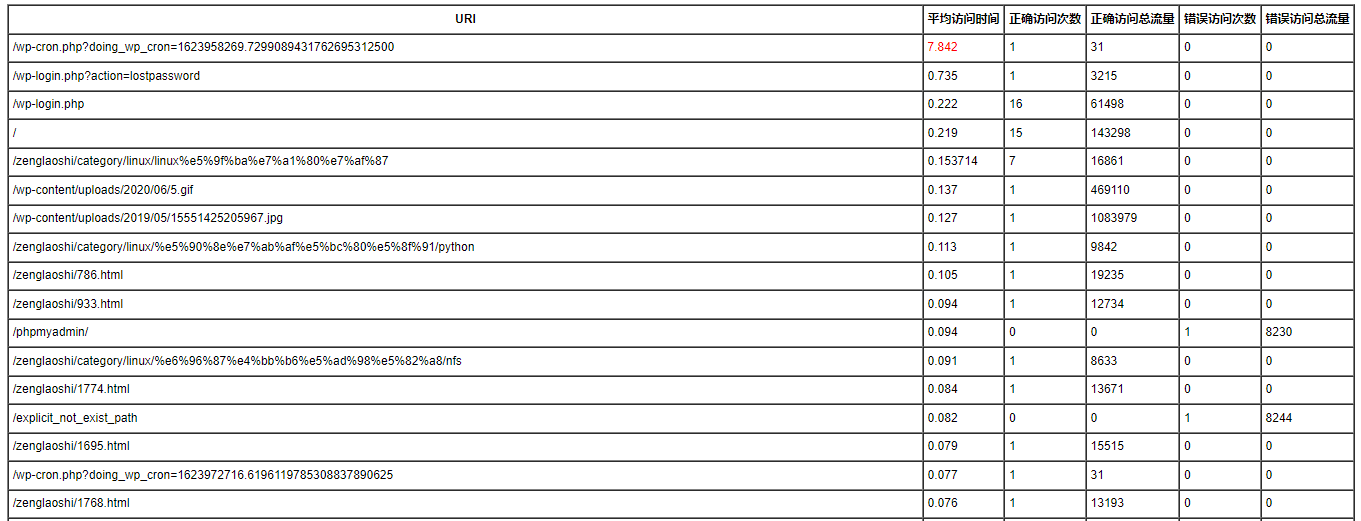
统计日志URI,平均访问时间,正确访问次数,错误访问次数,正确访问总流量,错误访问总流量。并发送邮件
1.使用awk统计,输出指定格式到文件中
# 使用awk统计,输出指定格式到文件中
echo 'URI 平均访问时间 正确访问次数 正确访问总流量 错误访问次数 错误访问总流量' > table.txt
2.编写脚本
#!/bin/bash
awk '{
uri_access_count[$7]++
uri_access_time[$7]+=$9
if($10!~/[1-3]/){
uri_error_count[$7]++
uri_error_flow[$7]+=$11
}else{
uri_right_count[$7]++
uri_right_flow[$7]+=$11
}
}END{
for(uri in uri_access_count){
if(uri_error_count[uri]){error_count=uri_error_count[uri]}else{error_count=0}
if(uri_error_flow[uri]){error_flow=uri_error_flow[uri]}else{error_flow=0}
if(uri_right_count[uri]){right_count=uri_right_count[uri]}else{right_count=0}
if(uri_right_flow[uri]){right_flow=uri_right_flow[uri]}else{right_flow=0}
if(uri_access_time[uri]){access_avg_time=uri_access_time[uri]/uri_access_count[uri]}else{access_avg_time=0}
print uri,access_avg_time,right_count,right_flow,error_count,error_flow
}
}' blog.driverzeng.com_access.log|column -t|sort -nrk2 >> table.txt
3.编写awk生成html脚本
# 编写awk生成html脚本
cat > file_to_html.awk <<"EOF"
#!/bin/awk -f
BEGIN {
# FS="分隔符"
print ""
"
}
NR==1 {
print "" "
for(i=1; i<=NF; i++){
print ""$i" "
}
print "
}
NR>1 {
print "" "
for(i=1; i<=NF; i++){
if(i==2 && $i>3){
print ""$i" "
}else{
print ""$i" "
}
}
print "
}
END {
print "
}
EOF
# 为该脚本授予执行权限
chmod +x file_to_html.awk
# 指定该脚本,生成html
./file_to_html.awk table.txt > table.html
4.使用sendEmail发送HTML文件
# 使用sendEmail发送HTML文件
sendEmail \
-f 295770347@qq.com \
-t Leessrs@163.com \
-s smtp.qq.com \
-u '日志统计' \
-xu 295770347 \
-xp oerhngfrqbgxbjed \
-o message-content-type=html \
-o message-file=/tmp/table.html \
-o message-charset=utf8 \
-o tls=no




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有