总目录:https://blog.csdn.net/qq_41106844/article/details/105553392
Hadoop - 子目录:https://blog.csdn.net/qq_41106844/article/details/105553369
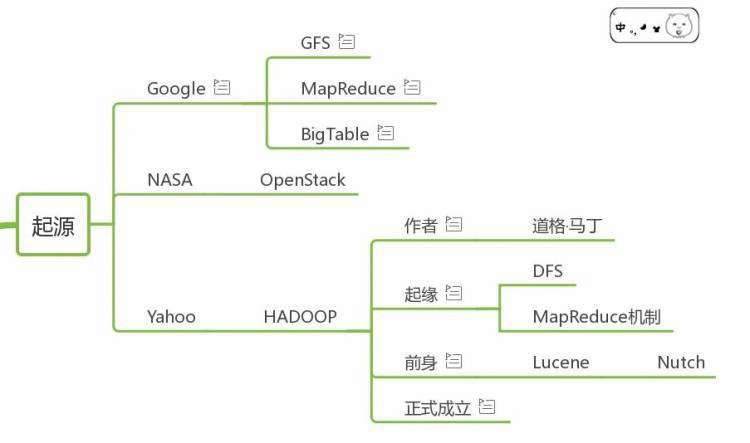
起源
起源可以分为三步,Google提出思想,并实现了内部的大数据系统,这让其他人知道这种解决方式是可行的;之后NASA为了计算火箭的偏移和位置,研发了OpenStack用于日常使用;最后道格马丁和其他同伴在雅虎基于谷歌披露的论文开发了开源系统Hadoop。
本文链接:https://www.jianshu.com/p/ef765c933808
Google
谷歌作为地球上最大的搜索引擎服务商,每天都需要处理海量的数据,但是为了存储和使用他们,谷歌每天都要投入大量的人力物力,产生大量成本。
这显然和谷歌的低成本之道不符合,之后为了降低成本,谷歌使用大量旧式服务器搭建集群用于处理这些数据,由此谷歌三剑客之一的GFS诞生。
之后为了处理方便逻辑处理这些数据,MapReduce诞生。
为了方便存储和管理他们,BigTable诞生。
谷歌三剑客
GFS ===> HDFS
MapReduce ===> MapReduce
BigTable ===> HBASE
Yahoo
作者:Doug cutting(道格·卡丁),就职于Yahoo期间开发了Hadoop。
起源:2003-2004年,Google公布了部分GFS和MapReduce思想的细节。以此为基础,道格等人用来两年业余时间,开发了DFS和MapReduce机制,构建了一个搜索引擎:Nutch。
前身:2005年秋天,Hadoop作为Lucene(全文检索引擎)的子项目Nutch的一部分引入Apache基金会(专门为支持开源软件项目而办的一个非盈利性组织)。
正式成立:2006年3月,map-reduce和NDFS分别被纳入HADOOP项目。
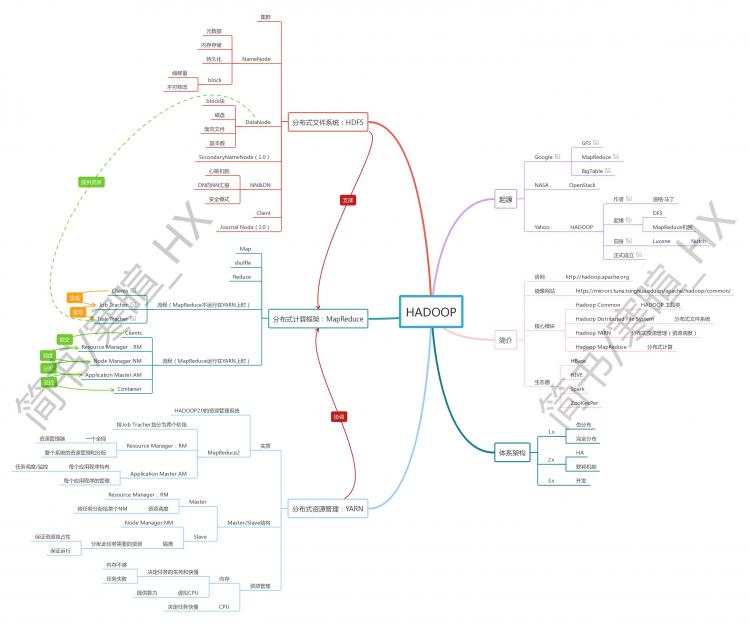
简介
官网:http://hadoop.apache.org
镜像网站:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
核心模块:
Hadoop Common HADOOP 工具类
Hadoop Distributed File System 分布式文件系统
Hadoop YARN 分布式资源管理(资源调度)
Hadoop MapReduce 分布式计算
架构
Hadoop分为Hadoop1.x,Hadoop2.x和Hadoop3.x三个版本,其中Hadoop1.x只有HDFS、MapReduce,Hadoop2.x和Hadoop3.x有HDFS、MapReduce和Yarn。
Hadoop1.x
由HDFS和MapReduce组成。
缺陷:
任务机制是job-task任务机制,没有负载均衡。
只有一个NN,一旦受压崩溃,集群瘫痪。
Hadoop2.x
由HDFS、MapReduce和Yarn组成。
缺陷:
即便有Yarn协调作业,有HA来避免主节点宕机,但是主节点的作业能力依旧限制着集群的发展。
Hadoop是一个提供了基本架构的框架,人们可以按照自己的需求在Hadoop上构建自己的集群。












 京公网安备 11010802041100号
京公网安备 11010802041100号