作者:MS07224_670 | 来源:互联网 | 2023-08-26 04:51
1、Partition 操作常用API
- Random partitioning
- Rebalancing
- Rescaling
- Custom partitioning
- Broadcasting
- Random partitioning:随机分区
使用dataStream.shuffle()方法
底层实现:
public class ShufflePartitioner extends StreamPartitioner {
private static final long serialVersiOnUID= 1L;
private Random random = new Random();
private final int[] returnArray = new int[1];
@Override
public int[] selectChannels(SerializationDelegate> record,
int numberOfOutputChannels) { // 获取所有 channel 数
returnArray[0] = random.nextInt(numberOfOutputChannels); // 得到一个 0 - channel_num 之间的数值
return returnArray; // 该返回的数值决定了要分到哪个区
}
@Override
public StreamPartitioner copy() {
return new ShufflePartitioner();
}
@Override
public String toString() {
return "SHUFFLE";
}
}
- Rebalancing:对数据集进行再平衡,重分区,消 除 数 据 倾 斜 \color{red}{消除数据倾斜}消除数据倾斜
使用dataStream.rebalance()方法
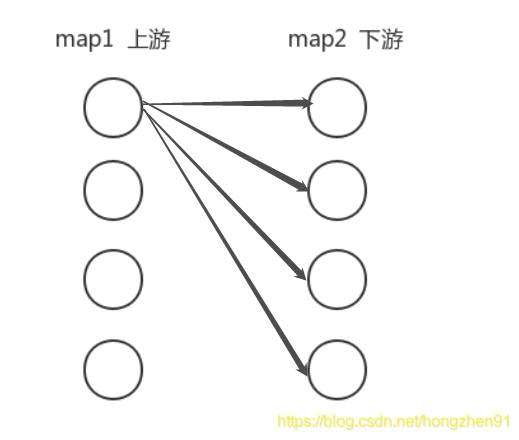
底层实现:
public class RebalancePartitioner extends StreamPartitioner {
private static final long serialVersiOnUID= 1L;
private final int[] returnArray = new int[] {-1};
@Override
public int[] selectChannels(SerializationDelegate> record,
int numberOfOutputChannels) {
int newChannel = ++this.returnArray[0]; // 获取 0 号元素的数据,通过加1,指向下一个channel
if (newChannel >= numberOfOutputChannels) { // 如果大于等于 channel数,则加到头了,重新再从 0号channel开始分发
this.returnArray[0] = 0;
}
return this.returnArray;
}
public StreamPartitioner copy() {
return this;
}
@Override
public String toString() {
return "REBALANCE";
}
}
- Rescaling:
使用dataStream.rescale()方法
举例:
如果上游操作有2个并发,而下游操作有4个并发,那么上游的一个并发结果分配给下游的两个并发操作,另外的一个并发结果分配给了下游的另外两个并发操作.另一方面,下游有两个并发操作而上游又4个并发操作,那么上游的其中两个操作的结果分配给下游的一个并发操作而另外两个并发操作的结果则分配给另外一个并发操作。
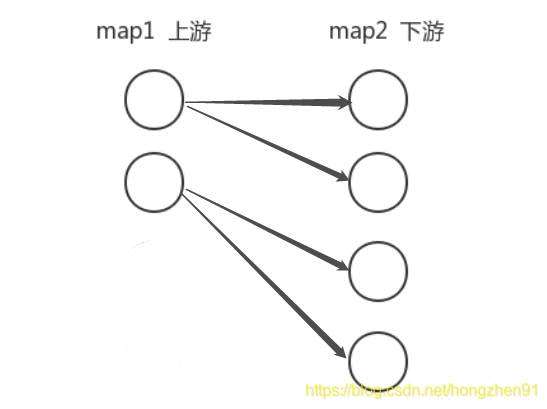
注意:
- Rescaling与Rebalancing的区别:
- Rebalancing会产生全量重分区,而Rescaling不会。
- Custom partitioning:自定义分区
自定义分区需要实现Partitioner接口
使用dataStream.partitionCustom(partitioner, “someKey”)方法
或者
使用dataStream.partitionCustom(partitioner, 0); 方法 - Broadcasting
2、自定义分区 Custom partitioning
自定义分区
自定义分区需要实现Partitioner接口
2.1 Java代码实现
实现根据奇、偶数分区
public class MyPartition implements Partitioner {
@Override
public int partition(Long key, int numPartitions) {
System.out.println("分区总数:"+numPartitions);
if(key % 2 == 0){
return 0;
}else{
return 1;
}
}
}
dataStream.partitionCustom(partitioner, "someKey")
或者:
dataStream.partitionCustom(partitioner, 0);
完整代码:
package com.Streaming.custormPartition;
import com.Streaming.custormSource.MyNoParalleSource;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple1;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Author: Henry
* @Description: 使用自定义分析
* 根据数字的奇偶性来分区
* @Date: Create in 2019/5/12 19:21
**/
public class SteamingDemoWithMyParitition {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource text = env.addSource(new MyNoParalleSource());
//对数据进行转换,把long类型转成tuple1类型
DataStream> tupleData = text.map(new MapFunction>() {
@Override
public Tuple1 map(Long value) throws Exception {
return new Tuple1<>(value);
}
});
//分区之后的数据
DataStream> partitiOnData= tupleData.partitionCustom(new MyPartition(), 0);
DataStream result = partitionData.map(new MapFunction, Long>() {
@Override
public Long map(Tuple1 value) throws Exception {
System.out.println("当前线程id:" + Thread.currentThread().getId() + ",value: " + value);
return value.getField(0);
}
});
result.print().setParallelism(1);
env.execute("SteamingDemoWithMyParitition");
}
}
2.2、运行结果
分数总数:8 (因为没有设置并行度)
虽然并行度是8,但是实际只有两个线程工作:即线程id=68 和 线程id=69
线程id=68,处理奇数分区
线程id=69,处理偶数分区
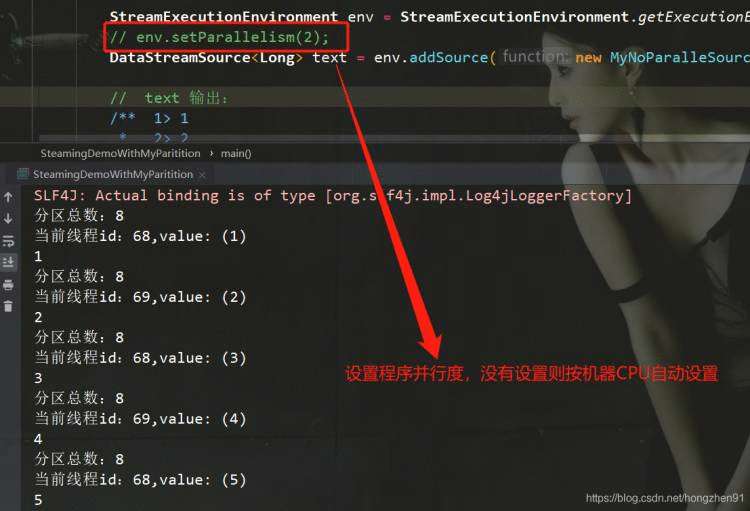
由上图代码,可以根据业务设置并行度,即 env.setParallelism(2) ;
2.3 Scala代码实现
自定义分区代码如下:
package cn.Streaming.custormPartition
import org.apache.flink.api.common.functions.Partitioner
/**
* @Author: HongZhen
* @Description:
* @Date: Create in 2019/5/14 22:16
**/
class MyPartitionerScala extends Partitioner[Long]{
override def partition(key: Long, numPartitions: Int) = {
println("分区总数:"+numPartitions)
if(key % 2 ==0){
0
}else{
1
}
}
}
主程序代码:
package cn.Streaming.custormPartition
import cn.Streaming.custormSource.MyNoParallelSourceScala
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* @Author: Henry
* @Description:
* @Date: Create in 2019/5/14 22:17
**/
object StreamingDemoMyPartitionerScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
//把long类型的数据转成tuple类型
val tupleData = text.map(line=>{
Tuple1(line)// 注意tuple1的实现方式
// Tuple2 可以直接写成如 (line,1)
// 但是 Tuple1 必须加上关键词 Tuple1
})
// 上面将 Long 转换为 Tuple1[Long] 的原因是由于
// partitionCustom 的 field 参数类型: Tuple1[K]
val partitiOnData= tupleData.partitionCustom(
new MyPartitionerScala, 0 )
val result = partitionData.map(line=>{
println("当前线程id:"+
Thread.currentThread().getId+",value: "+line)
line._1
})
result.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
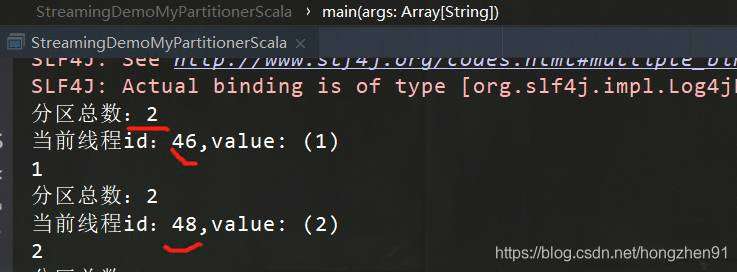
2.4 运行结果







 京公网安备 11010802041100号
京公网安备 11010802041100号