来源:http://stblog.baidu-tech.com/?p=418
多模式匹配在这里指的是在一个字符串中寻找多个模式字符字串的问题。一般来说,给出一个长字符串和很多短模式字符串,如何最快最省的求出哪些模式字符串出现在长字符串中是我们所要思考的。该算法广泛应用于关键字过滤、入侵检测、病毒检测、分词等等问题中。多模问题一般有Trie树,AC算法,WM算法等等。我们将首先介绍这些常见算法。
1.hash
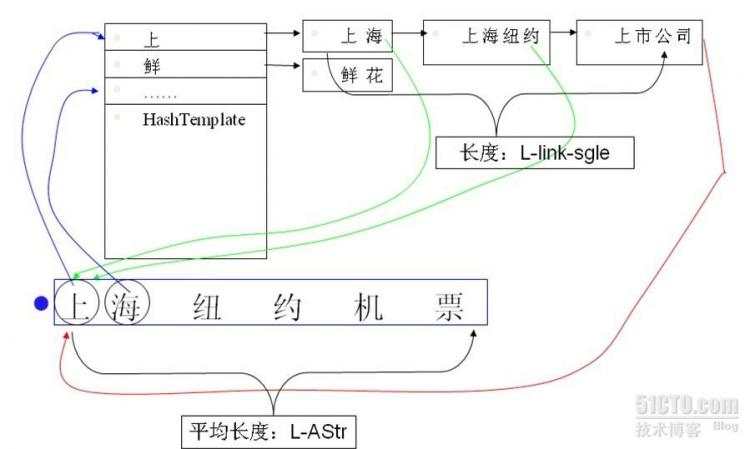
可以单字、双字、全字、首尾字hash。
优点:简单、通常有效
缺点:受最坏情况制约,空间消耗大,需要回朔。
2.Trie树
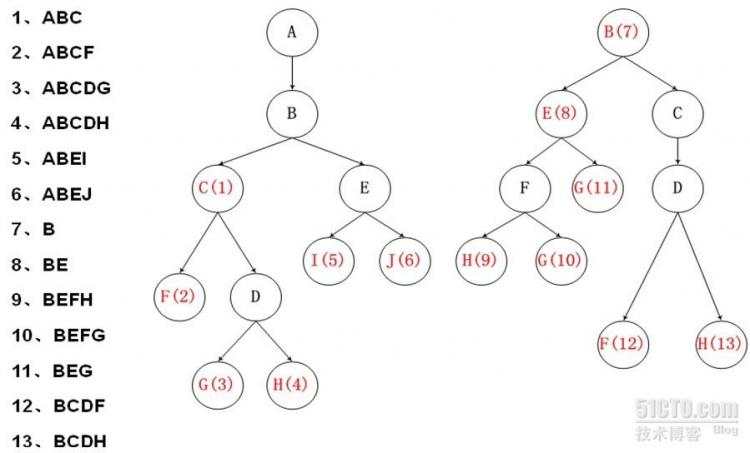
改进:进行穿线,参考KMP的算法,进行相同前缀匹配,建立跳转路径,避免回朔。
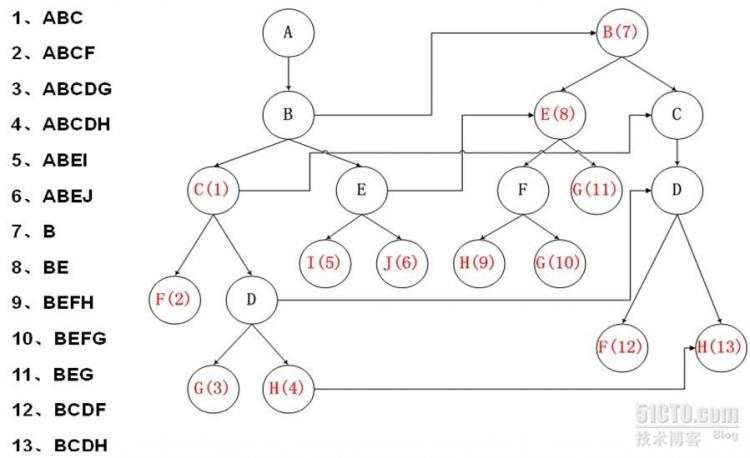
跳转路径建立的算法思想:
如果要建立节点 A -> A’ 的 跳转路径需要满足:
1) A = A’ 节点有相同的value值,代表同一个字
2) A的深度>A’的深度
3) 对于A节点的父节点F,和A’节点的父节点(如果有父节点的话),有F->F’
优点:无回朔,查询效率一般较高
缺点:数据结构复杂难以维护,浪费空间多,建树时间长。
3.AC算法
本质上来说和Trie树一样。
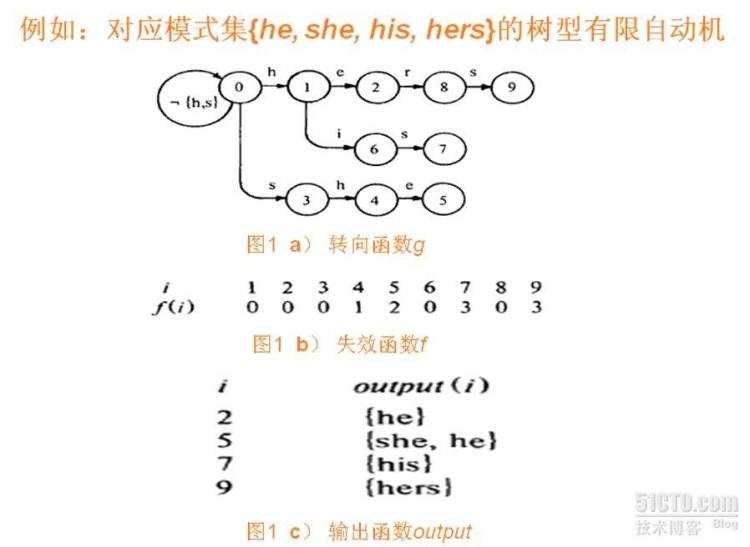
转向函数:建立一个根据输入字符转变状态的有限自动机
失效函数:当出现状态无法根据输入字符继续走时,需要根据失效函数转化当前状态。失效函数的建立需要满足:节点r深度之前都已建立失效函数f。则若有g(r, a) = s,回朔r’=f( r )直至找到g(r’, a) 存在,则将f(s)=g(r’, a)。和Trie树是一致的。实际上,如果某状态节点r对输入字符a无路径,则可以将该节点的失效函数f( r )指向的状态节点r’的g(r’, a)作为g(r, a)。这样在搜索中就不需要专门考虑失效节点的问题了,只需要沿着转向函数一直走。
输出函数:某状态代表着匹配某模式的结束,因此输出函数的值就是匹配成功模式的集合。因为模式之间可能会有互包含,因此可能有多个成功匹配的模式。
AC算法比Trie树数据结构简单,因此运用广泛。用于snort等代码中。
4.WM算法
先讲BM算法。BM算法是KMP之外的另一个单模式字符串匹配算法,其思想也很简单:
假设模式串是P 主串是T, m=strlen(P),n=strlen(T)
1) 从左向右移动模式串
2) 对于模式串的匹配, 从右向左检查, 也就是P[m-1],p[m-2]…
3) 当发现不匹配时, 使用好后缀和/或坏字符来决定模式串移动的距离 通常同时使用两个来加快查找速度
当发现一个不匹配时 如下:
Consider a mismatch at P[n - 5]:
T: mahtava talomaisema omalomailuun
P: maisemaomaloma
上面 m != t ,
这时 T 中的 t字符叫做坏字符,P 中的字符 “aloma” 叫做好后缀
坏字符算法:
当出现一个坏字符时, BM算法向右移动模式串, 让模式中最靠右的对应字符与坏字符相对。然后继续匹配。移动距离可预先计算为delta1(x) &#61; m – max{k|P[k] &#61; x, 1 <&#61; k <&#61; m}; &#xff08;x出现在P中&#xff09;。
好后缀算法:
如果程序匹配了一个好后缀, 并且在模式中还有另外一个相同的后缀, 那把下一个后缀移动到当前后缀位置(类似KMP 只是KMP是从左向右移动)。移动距离delta2可预先计算为delta2&#xff08;j&#xff09;&#61; {s|P[j&#43;1..m]&#61;P[j-s&#43;1..m-s]) && (P[j]≠P[j-s])(j>s)}。
BM算法在查找开始时 先根据模式串中所有字符建立一个坏字符表&#xff0c;然后创建一张好后缀表。在匹配过程中&#xff0c;取max{delta1, delta2}作为实际移动的离尾部的距离&#xff0c;即尽量移动距离最大。
BM算法的最坏时间复杂度为O(m*n)&#xff0c;但实际比较次数只有文本串长度的20%&#xff5e;30%。可以看作是亚线性的时间复杂度算法。
WM算法的思想从BM算法思想演变而来&#xff0c;但是用于多模匹配中。WM算法也是从右到左进行匹配。WM算法有一个重要假设&#xff0c;假设所有的模式的字符串长度是一样的&#xff0c;为m。若不一样&#xff0c;则按最短的那个模式长度在做匹配时截断其他的模式。
WM算法将建立三张表&#xff1a;SHIFT[], HASH[], PREFIX[]。其中&#xff0c;SHIFT表用于决定匹配时出现失配的情况时的移动距离&#xff0c;类似于BM算法中的坏字符策略。HASH和PREFIX表则用于当SHIFT表匹配成功不需要移动后&#xff0c;决定是否具体匹配到某个模式的问题。
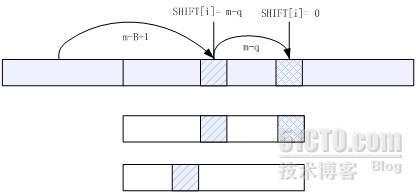
SHIFT表&#xff1a;考虑一块大小为B的字符块&#xff0c;而不是单纯的一个字符。一般取B&#61;2或3。SHIFT为长度为B的一切可能的字符排列都建立一个索引&#xff0c;因此其下标的大小就是所有可能的长度为B的排列数。&#xff08;实际上&#xff0c;可以通过压缩的策略将一些排列串弄到相同的空间&#xff09;。SHIFT 中每一项的值决定在文本中出现某B 个字符组成的字符串时pattern 的移动距离&#xff0c;也就是在所有的pattern中出现的最右的B离pattern尾部的距离。假设X为当前计算的B长字符块&#xff0c;且被hash为i&#xff0c;考虑两种情况&#xff1a;
第一&#xff1a;X 不在任何一个pattern 中出现&#xff0c;我们可以将当前text考察的位置向后移
动m-B&#43;1 个字符的距离&#xff0c;于是我们在SHIFT[i]中存放m-B&#43;1。
第二&#xff1a;X 在某些pattern 中出现&#xff0c;这种情况下&#xff0c;我们考察那些pattern 中
X 出现的最右位置。假设&#xff0c;X 在P[j]中的q 位置出现&#xff0c;且在其他的出现X 的pattern 中X 的位置都不大于q。那么我们应该在SHIFT[i]中存放m-q。
最后我们将得到SHIFT 表&#xff0c;表中存放的值是我们text 中出现某一长为B 的字符串时能够移动的最大的安全距离。当检查pos位置&#xff0c;得到其B块的hash值为i&#xff0c;当SHIFT[i]<> 0 时&#xff0c;pos&#61;pos &#43; SHIFT&#xff0c;跳动。
HASH表&#xff1a;当SHIFT[i]&#61;0时使用。SHIFT[i]&#61;0时&#xff0c;代表匹配串当前位置的X可能匹配上了某个&#xff08;某些&#xff09;模式的尾部。因此HASH[i]指向了尾部B长的字符块散列值为i的模式链表的头p。我们可以将所有的模式以尾部B长的字符块的散列值进行排序存放在某个模式表数组中&#xff0c;则只需要依次递增p就可以找到所有尾部散列值为i的模式&#xff0c;直到p &#61; hash[i&#43;1]&#xff0c;代表了该链表的尾部。
PREFIX表&#xff1a;当SHIFT[i]&#61;0时&#xff0c;且通过HASH表列出了所有可能的模式时使用。通过对每个模式头部B’个字符进行hash&#xff0c;将其散列值放在PREFIX表中。HASH[i]中的指针同时也是指向PREFIX表的&#xff0c;通过比较PREFIX[p]和匹配串的头B’个字符的hash值&#xff0c;能够进一步确定是哪个模式匹配上了。最终&#xff0c;对该模式和匹配串的每一个字符进行一一匹配确定是否匹配。
如果SHIFT[i]&#61;0&#xff0c;且检查匹配完成&#xff0c;则pos &#61; pos &#43; 1&#xff0c;继续检查pos位置的SHIFT。
实践证明&#xff0c;大部分时间SHIFT都不为0&#xff0c;&#xff08;在一个典型的例子中&#xff0c;对于100个模式5%的时间移动值为0&#xff0c;1000个模式27%的时间移动值为0&#xff0c;5000个模式53%的时间。&#xff09;&#xff0c;也就代表匹配串是跳跃着前进的&#xff0c;因此可以达到亚线性的时间复杂度。经过计算&#xff0c;复杂度为O(mp)&#43; O(BN/m)&#xff0c;设N是文本的大小&#xff0c;P是模式的数量&#xff0c;m是每个模式的长度。
优点&#xff1a;快速&#xff0c;数据结构简单&#xff0c;实现容易。
缺点&#xff1a;需要所有模式长度基本相同&#xff08;不能有太短的模式&#xff09;&#xff0c;不支持变长的编码&#xff0c;例如GB18030。
dictmatch基本数据结构及算法
dictmatch其实是实现了最简单的Trie树的算法&#xff0c;而且并没有进行穿线改进&#xff0c;因此其是需要回朔的。但是其使用2个表来表示Trie树&#xff0c;并对其占用空间大的问题进行了很大的优化&#xff0c;特点是在建树的时候比较慢&#xff0c;但在查询的时候非常快。而且其使用的hash算法也值得一讲。
- 字典数据结构&#xff1a;
typedef struct _DM_DICT
{
char* strbuf; // buffer for store word result;
u_int sbsize;
u_int sbpos; // the next position in word buf
dm_entry_t* dentry; // the dict entry list
u_int desize;
u_int depos; // the first unused pos in de list
u_int* seinfo; // the suffix entry list
u_int seisize;
u_int seipos;
dm_inlemma_t* lmlist; // the lemma list
u_int lmsize;
u_int lmpos; // the first unused pos in lemma list
u_int entrance;
}dm_dict_t;
//lemma structure for dict
typedef struct _DM_INLEMMA
{
u_int len;
u_int prop;
u_int bpos;
}dm_inlemma_t;
typedef struct _DM_ENTRY
{
u_int value;
u_int lemma_pos;
u_int suffix_pos;
}dm_entry_t;
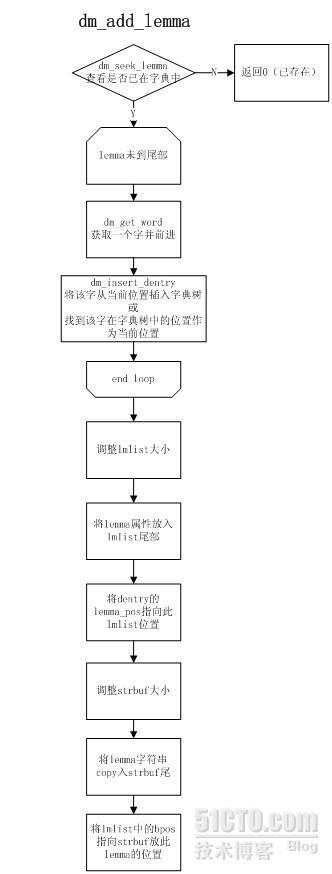
其中&#xff0c;dentry可以认为存放树的每个节点&#xff0c;seinfo可以认为存放每个节点的子树的指针列表&#xff08;即后继块&#xff09;&#xff0c;lmlist存放完成匹配对应的某模式&#xff0c;而strbuf记录所有模式的字符串内容。
每个表的空间都预先开好&#xff0c;以xxxsize为大小。而xxxpos指针之前是已用空间&#xff0c;之后是未使用空间。
seinfo中&#xff0c;每个后继块首字节放的是该后继块的hash表大小&#xff0c;第二个字节指向其属主dentry节点&#xff0c;第三个字节开始是存放子树指针的hash表。因此&#xff0c;每个后继块的大小为hsize&#43;2。
entrance指向了虚根节点所引出的每棵树的指针列表&#xff0c;也就是整个Trie树的入口。
图示&#xff1a;
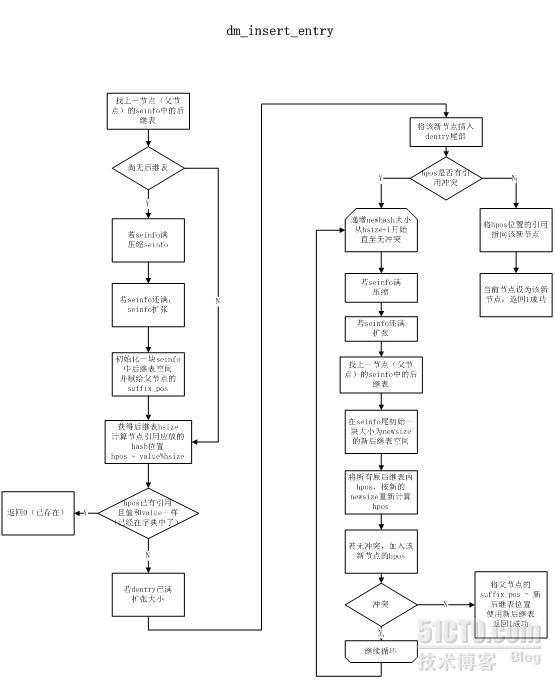
2. 建树算法&#xff1a;&#xff08;lemma指得就是一个模式&#xff09;
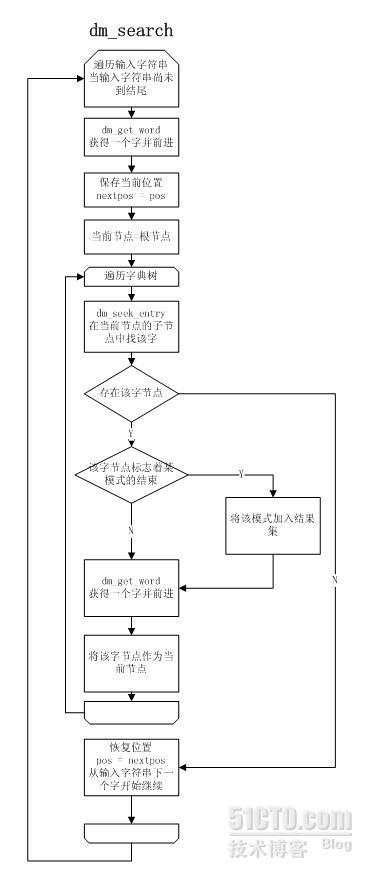
3. 搜索模式匹配
关键策略
1. 解决hash冲突
解决后缀表中的hash冲突是非常重要的&#xff0c;因为在策略中通过hpos &#61; value%hsize直接找到存放指向dentry的引用的位置&#xff0c;而没有考虑冲突的情况&#xff0c;因此必须在加入该hash表时解决。
方法也很简单&#xff0c;当出现冲突则不断增长hash size的大小&#xff0c;重新计算所有该后缀表中的hash值&#xff0c;直至无冲突。由于size变大因此原位置必然无法容纳新后缀表&#xff0c;需要在seinfo的尾部添加新表&#xff0c;而原表废弃不用&#xff0c;就造成了一个空洞。这也是需要压缩的原因。
2. seinfo压缩算法
从前到后遍历所有的后缀表块&#xff0c;检查是否是有效的
无效&#xff1a;其backentry所指向的节点的suffix_pos不是自己&#xff0c;或backentry指向DM_DENTRY_FIRST&#xff08;代表是根后缀表块&#xff09;但entrance指向的不是自己。
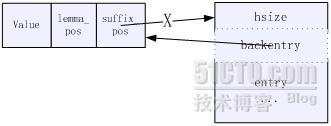
当发现一块有效的后缀表块&#xff0c;而其前面有若干块无效的后缀表块时&#xff0c;将这块有效后缀表块copy到前面覆盖原来无效的位置&#xff0c;并更新backentry指向的dentry的suffix_pos。这样就可以填充掉所有的空洞&#xff0c;将所有的可用空间都留在sepos之后。
3. 编码
由于采用GB18030编码格式&#xff0c;因此一个字可能是1字节、2字节、4字节
1字节&#xff1a; 0×00~0×7F ASCII
2字节&#xff1a; 0×81~0xFE 0×40~0×7E/0×80~0xFE GBK传统
4字节&#xff1a; 0×81~0xFE 0×30~0×39 0×81~0xFE 0×30~0×39 GB新增&#xff08;日韩文&#xff09;
dm_get_word通过遍历字符决定下一个字是多少字节之后&#xff0c;并将当前字拼成u_int。
4. 各表初始大小
strsize: 20*lemma_num [char]
desize: 2*lemma_num [struct]
sesize: 8*lemma_num [uint]
lmsize: lemma_num [struct]
每次扩张都×2
每新建一个seinfo中的后继块&#xff0c;默认大小为3个u_int&#xff0c;一个放hsize&#xff0c;一个放backentry&#xff0c;一个放1个后继节点。
5. search
| 参数 | DM_OUT_FMM | DM_OUT_ALL |
| dm_search | 正向最大匹配的所有模式 | 匹配&#xff08;含重叠和包含&#xff09;的所有模式 |
| dm_search_prop | 正向最大匹配的所有模式的prop累“或”值 | 匹配&#xff08;含重叠和包含&#xff09;的所有模式的prop累“或”值 |
| dm_has_word | 正向最大匹配含有特定属性的子串&#xff0c;如果是多个属性值或在一起&#xff0c;任意一个属性符合条件即返回1 | 匹配&#xff08;含重叠和包含&#xff09;的所有模式含有特定属性的子串&#xff0c;如果是多个属性值或在一起&#xff0c;任意一个属性符合条件即返回1 |
6. prop和int互转
prop属性是一串字符串&#xff0c;其中每个字符都代表某一属性为真。
将prop转换成int需要遍历字符串&#xff0c;对每个字符查找其值是否已被分配到32位中的一位&#xff0c;若尚未分配&#xff0c;则递增分配&#xff0c;并记在g_propmap中。然后将该位置1。
将int转换成prop则正好是反操作&#xff0c;通过g_propmap查找每一位对应的字符。
int (*dm_prop_str2int_p)(char *) &#61; NULL;
void (*dm_prop_int2str_p)(int, char *) &#61; NULL;
这2个全局的函数指针&#xff0c;需要在使用时在外部赋值以便进行属性转换。
7. 搜索时&#xff0c;读同一个字典&#xff0c;多线程安全。
8. 为了使32位的字典在64位机器内使用&#xff0c;因此为了&#xff0c;将词典内部词条的结构和切词结构独立开了&#xff08;以前是一个结构&#xff09;&#xff0c;分别是dm_inlemma_t和dm_lemma_t。区别在于&#xff0c;dm_inlemma_t结构中只有int&#xff0c;而dm_lemma_t中有int和char* &#xff0c;其中char*在32位和64位表现不同&#xff0c;影响存储结构。
可能的改进
- 进行穿线&#xff0c;引入跳转路径。基本的想法就是&#xff0c;在dentry中新加入一个域failjump&#xff0c;指向另一个跳转的dentry节点&#xff0c;当Trie树匹配在某节点失败时&#xff0c;转向failjump域指向的新节点再进行一次或若干次匹配。这样可以做到对目标字符串无回朔&#xff0c;而不是现在的匹配失败后必须进行回朔。
- 转换成UNICODE之类的定长编码&#xff0c;&#xff08;实际上dm_get_word已经做过类似的这一遍&#xff09;&#xff0c;然后使用WM算法进行计算。






 京公网安备 11010802041100号
京公网安备 11010802041100号