作者:手机用户2502857113 | 来源:互联网 | 2023-09-15 19:10
改进了MixMatch半监督学习算法,引入了两种新技术:分布对齐(DistributionAlignment)和增强锚定(AugmentationAnchoring).分布对齐鼓励
改进了 MixMatch 半监督学习算法, 引入了两种新技术: 分布对齐(Distribution Alignment)和增强锚定(Augmentation Anchoring). 分布对齐鼓励未标记数据预测的边际分布接近真实标签的边际分布. 增强锚定将输入的多个强增强版本输入到模型中, 并鼓励每个输出接近同一输入的弱增强版本的预测.
在 MixMatch 的基础上, 原作者自己提出了改进版本: ReMixMatch. 关于 MixMatch 的介绍, 可以参考上一篇文章: https://blog.csdn.net/by6671715/article/details/122766432?spm=1001.2014.3001.5501.
ReMixMatch 与 MixMatch 主要的区别在于, ReMixMatch 改进了两个地方: 分布对齐, 增强锚定.
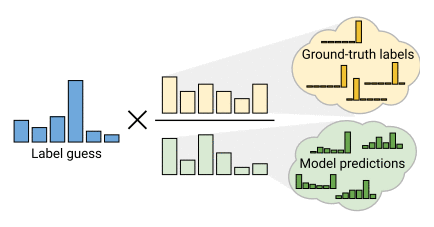
分布对齐(Distribution Alignment)
Distribution Alignment 可描述如下: 在训练过程中, 我们保持模型对未标记数据的预测的平均值, 称之为 p~(y)\tilde{p}(y) p ~ ( y ) uu u q=pmodel(y∣u;θ)q=p_{model}(y \vert u; \theta) q = p m o d e l ( y ∣ u ; θ ) p(y)/p~(y)p(y)/ \tilde{p}(y) p ( y ) / p ~ ( y ) qq q p(y)p(y) p ( y ) q~=Normalize(q×p(y)/p~(y))\tilde{q}=\mathrm{Normalize}(q \times p(y)/ \tilde{p}(y)) q ~ = N o r m a l i z e ( q × p ( y ) / p ~ ( y ) ) Normalize(x)i=xi/∑jxj\mathrm{Normalize}(x)_i=x_i/\sum_j x_j N o r m a l i z e ( x ) i = x i / ∑ j x j q~\tilde{q} q ~ uu u
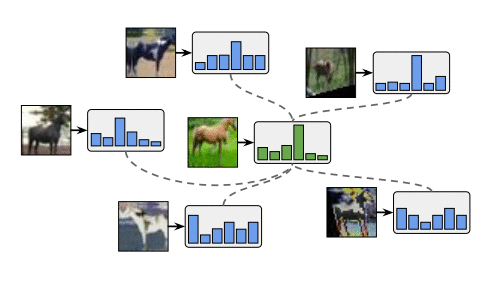
增强锚定(Augmentation Anchoring) KK K KK K
在少标签 SSL 情况下, AutoAugment, RandAugment 方法存在一些问题, 因此, 开发了 CTAugment, 一种设计高性能增强策略的替代方法. 与 RandAugment 一样, CTAugment 还对变换进行统一随机采样, CTAugment 不需要在有监督的代理任务上进行优化, 并且没有敏感的超参数, 因此可以直接将其包含在半监督模型中, 以在半监督学习中进行更积极的数据增强实验.
损失函数(Loss Function) ReMixMatch 算法描述如下:U^1\hat{\mathcal{U}}_1 U ^ 1 U^1\hat{\mathcal{U}}_1 U ^ 1 ∑x,p∈X′H(p,pmodel(y∣x;θ))+λU∑u,q∈U′H(q,pmodel(y∣u;θ))+λU^′∑u,q∈U′H(q,pmodel(y∣u;θ))+λr∑u∈U1′H(r,pmodel(r∣Rotate(u,r);θ))\sum_{x,p\in\mathcal{X}'} \mathrm{H}(p,p_{model}(y\vert x;\theta))+\lambda_{\mathcal{U}}\sum_{u,q\in\mathcal{U}'} \mathrm{H}(q,p_{model}(y\vert u;\theta))+\lambda_{\mathcal{\hat{U}'}}\sum_{u,q\in\mathcal{U}'} \mathrm{H}(q,p_{model}(y\vert u;\theta))+\lambda_{r}\sum_{u\in\mathcal{U}_1'} \mathrm{H}(r,p_{model}(r\vert \mathrm{Rotate}(u,r);\theta)) x , p ∈ X ′ ∑ H ( p , p m o d e l ( y ∣ x ; θ ) ) + λ U u , q ∈ U ′ ∑ H ( q , p m o d e l ( y ∣ u ; θ ) ) + λ U ^ ′ u , q ∈ U ′ ∑ H ( q , p m o d e l ( y ∣ u ; θ ) ) + λ r u ∈ U 1 ′ ∑ H ( r , p m o d e l ( r ∣ R o t a t e ( u , r ) ; θ ) ) u∈U1′^u \in \hat{\mathcal{U}_1'} u ∈ U 1 ′ ^ Rotate(u,r)\mathrm{Rotate}(u,r) R o t a t e ( u , r ) rr r r∼{0,90,180,270}r \sim \{0,90,180,270\} r ∼ { 0 , 9 0 , 1 8 0 , 2 7 0 }
代码地址: https://github.com/google-research/remixmatch













 京公网安备 11010802041100号
京公网安备 11010802041100号