python 爬取网页编码问题
我在爬取凤凰网却出现
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 151120: illegal multibyte sequence
这是我的代码
__author__ = 'my'
import urllib.request
url = 'http://www.ifeng.com/'
req = urllib.request.urlopen(url)
req = req.read()
req = req.decode('utf-8')
print(req)
为什么utf8却报错GBK?
-
# _*_ coding: utf-8 _*_
指定文件编码import sys reload(sys) sys.setdefaultencoding('utf-8')声明你程序的编码。
2022-11-12 01:45 回答 手机用户2502923413
手机用户2502923413 -
你是用windows控制台运行的吧?因为控制台默认编码是gbk。
用python自带的解释器就没问题: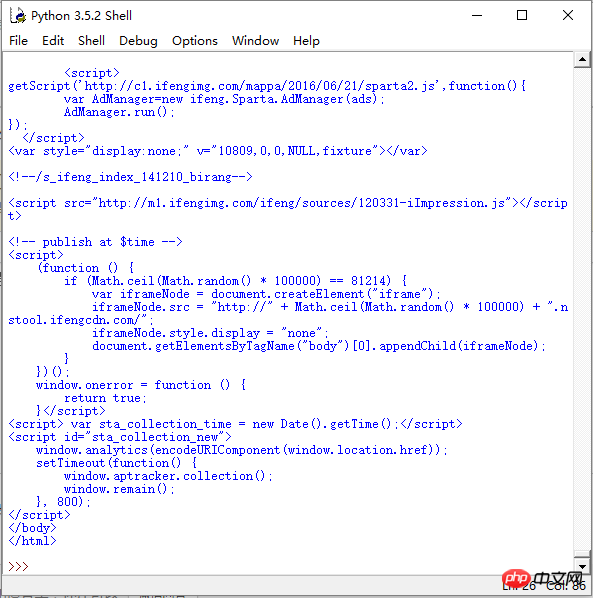
或者用其他的工具,别用控制台就行。2022-11-12 01:45 回答 手机用户2602886175
手机用户2602886175 -
估计你系统默认编码是gbk,你可以试试
import sys reload(sys) sys.setdefaultencoding('utf-8')2022-11-12 01:45 回答 玻璃里的鱼鱼
玻璃里的鱼鱼 -
刚我把题主的代码放到pycharm中,没有出现这个问题。然后我用windows命令提示符一行一行敲,出现了这个问题。windows命令提示符是使用的gbk编码,而网页本身使用的是utf-8进行编码。如果你希望在命令行能运行它,那么需要这么写:
`__author__ = 'my' import urllib.request url = 'http://www.ifeng.com/' req = urllib.request.urlopen(url) req = req.read() req = req.decode('gbk', 'ignore') print(req)`这里
req = req.decode('gbk', 'ignore')我解释一下:要在windows命令提示符中显示,需要解码为gbk,但是utf-8本身有些字符使用gbk解码又会失败,所以需要第二个参数ignore,这个参数意思就是把不能解码的字符舍弃掉。
说句题外话,编码可能也会遇到这个问题,比如用requests库请求的话直接就是请求的字符串而不是字节类型,如果编码遇到问题也用str.encode('编码', 'ingore').decode('解码')来解决类似问题。
如果没听明白可以看看我的这篇博客还有回答一下题主的一个问题,有的网页没问题可能是某些网页采用的就是GBK编码或者那些文字对于GBK和UTF-8都兼容
2022-11-12 01:45 回答 蜡笔小新11953150
蜡笔小新11953150 -
这个是 cmd.exe 的问题,别的软件都能正确解码。例如 记事本、浏览器。。。。
import urllib.request import os url = 'http://www.ifeng.com/' rsp = urllib.request.urlopen(url) body = rsp.read() html = r'C:\ifeng.html' # 文件路径, 可以改成你自己想要的 with open(html, 'wb') as w: w.write(body) # 直接以 二进制 写入文件,不必解码. os.popen('notepad.exe ' + html) # 用 记事本 打开,就可以看到内容了.
追加:
其实也可以修改cmd.exe 的编码为 utf-8(cp65001)
步骤:
1、运行CMD.exe
2、chcp 65001
3、修改窗口属性的字体
在CMD窗口标题栏上点击右键,选择"属性"->"字体",将字体修改为True Type字体"Lucida Console"
如图: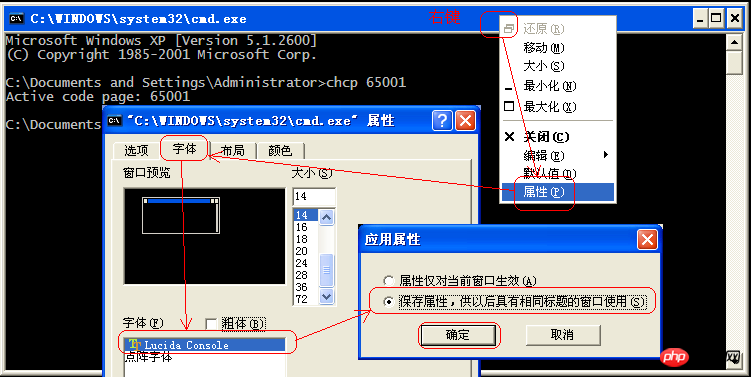
4、运行 python
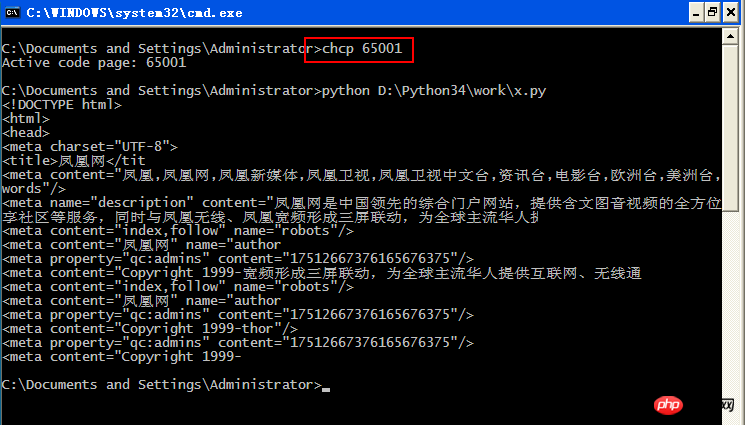
x.py 的内容:
import urllib.request url = 'http://www.ifeng.com/' rsp = urllib.request.urlopen(url) body = rsp.read() html = body.decode('utf-8') print(html[:500]) # 前500个字符 #print(html) # 也可打印全部,看看有没有错2022-11-12 01:45 回答 shinesmini
shinesmini
 京公网安备 11010802041100号
京公网安备 11010802041100号