1、支持向量机:
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
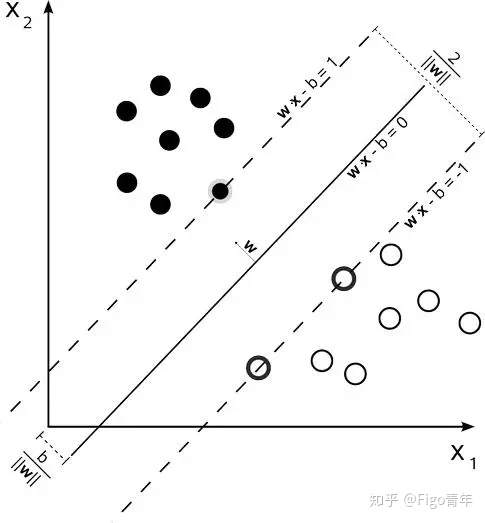
SVM的目的:寻找到一个超平面使样本分成两类,并且间隔最大。而我们求得的w就代表着我们需要寻找的超平面的系数。边界上的样本点就是支持向量,这些点很关键,这也是”支持向量机“命名的由来。
什么是线性可分?
在分类问题中给定输入数据和学习目标
![]()
,其中输入数据的每个样本都包含多个特征并由此构成特征空间(feature space):
![]()
,而学习目标为二元变量
![]()
表示负类(negative class)和正类(positive class)。
若输入数据所在的特征空间存在作为决策边界(decision boundary)的超平面(hyperplane):
![]()
将学习目标按正类和负类分开,并使
![]()
则称该分类问题具有线性可分性,参数
![]()
分别为超平面的法向量和截距。
满足该条件的决策边界实际上构造了2个平行的超平面:
![]()
作为间隔边界以判别样本的分类:
![]()
, if
![]()
, if
所有在上间隔边界上方的样本属于正类,在下间隔边界下方的样本属于负类。两个间隔边界的距离
![]()
被定义为边距(margin),位于间隔边界上的正类和负类样本为支持向量(support vector)。
2、损失函数:
在一个分类问题不具有线性可分性时,使用超平面作为决策边界会带来分类损失,即部分支持向量不再位于间隔边界上,而是进入了间隔边界内部,或落入决策边界的错误一侧。损失函数可以对分类损失进行量化,常用的损失函数有:铰链损失函数(hinge loss)、logistic损失函数(logistic loss)、指数损失函数(exponential loss)。
hinge:
logistic:
exponential:
其中SVM使用的是铰链损失函数。
图中
分类器的经验风险描述了分类器所给出的分类结果的准确程度;结构风险描述了分类器自身的稳定程度,复杂的分类器容易产生过拟合,因此是不稳定的。
最终的SVM损失函数既要考虑到经验风险,也要考虑到结构风险,因此最终的损失函数为:
第一项为经验风险,度量了模型对训练数据的拟合程度;第二项为结构风险,也称正则化项,度量了模型自身的复杂度,可以降低过拟合风险,由于该项为二次幂形式,所以又叫作L2正则项。
![]()
是一个可调参数,用来权衡经验风险和结构风险,以加大某一项的惩罚力度。
3、核函数:
SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。常见的核函数有:多项式核、径向基函数核、拉普拉斯核、Sigmoid核。
一些线性不可分的问题可能是非线性可分的,即特征空间存在超曲面(hypersurface)将正类和负类分开。使用非线性函数可以将非线性可分问题从原始的特征空间映射至更高维的希尔伯特空间(Hilbert space)H ,从而转化为线性可分问题,此时作为决策边界的超平面表示如下:
式中:
![]()
为映射函数
由于映射函数是复杂的非线性函数,因此其内积的计算是困难的,此时可使用核方法(kernel method),即定义映射函数的内积为核函数(kernel function)。
多项式核:
径向基函数核(RBF核)又被称为高斯核:
拉普拉斯核:
Sigmoid核:
当多项式核的阶为1时,其被称为线性核,对应的非线性分类器退化为线性分类器。RBF核也被称为高斯核(Gaussian kernel),其对应的映射函数将样本空间映射至无限维空间。



 京公网安备 11010802041100号
京公网安备 11010802041100号